Rerank Before You Believe
A vector index returns many plausible candidates; a reranker finally chooses the passages that answer the actual question. The failure is not that embeddings are useless.

Key Takeaways
- Reranking is the second judgment layer after broad recall. It narrows plausible matches into evidence the answer is allowed to use.
- A reranker adds cost and latency, so it belongs where quality risk justifies the extra pass.
- Measure whether reranking improves expected-document recall and final context quality, not whether it feels smarter.
Read this beside why RAG pipelines fail in month three, Retrieval That Survives Contact, and the Embeddings, Honestly overview when you turn the chapter into a production retrieval review.
Opening Problem
A vector index returns many plausible candidates; a reranker finally chooses the passages that answer the actual question. The failure is not that embeddings are useless. The failure is that the team expected the embedding to carry information it was never designed to carry. This is the honest starting point for this chapter: Why top-k vector results are candidates, not final answers; cross-encoders, semantic rerankers, LLM reranking, cost/latency tradeoff.
A production embedding system sits between human language and machine ranking. Humans ask questions with missing context, overloaded words, abbreviations, time references, permissions, and expectations about truth. The system converts some object into a vector and then searches for nearby vectors. That conversion is useful because it makes fuzzy language computable. It is dangerous because it quietly removes structure. A vector does not preserve the original document, the author's authority, the approval workflow, the user's permission boundary, or the business rule that says one source should override another. Those things have to be represented somewhere else in the system.
The recurring motif of this book is simple: a vector is a shadow, not the object. A shadow can tell you the rough shape of something. It cannot tell you everything the object is made of, when it was last changed, who owns it, whether it is safe, whether it is current, or whether it is legally binding. Good semantic systems are not built by denying that limitation. They are built by respecting it.
This chapter uses the chapter theme to make that limitation practical. We will look at what the embedding layer contributes, what it cannot contribute, which engineering controls must surround it, and how to recognize the failure pattern before users do. The aim is not to make you suspicious of embeddings. The aim is to make you accurate about them.
Plain-English Mental Model
Think of an embedding as a learned address. The model reads an object, such as a sentence, chunk, support ticket, product description, code function, image, or user profile, and places that object somewhere in a geometric map. Objects that the model has learned to treat as related tend to land near one another. This makes a certain kind of search possible: instead of asking only for exact words, the system can ask for nearby meaning.
That is the power. The limitation follows immediately. An address is not the house. If two houses are near one another, they may share a neighborhood, but they do not become the same house. A policy draft and an approved policy may discuss the same subject and therefore land close in vector space. A sales proposal and a binding contract may use nearly identical language and therefore look similar. A support ticket saying "I cannot access my account" and a help article saying "reset your password" may be close enough to be useful. The geometry captures relatedness. It does not certify correctness.
In engineering terms, this means the vector layer should be treated as a candidate-generation layer. It proposes possible neighbors. It should not be treated as the final authority. The final system must decide which candidates are allowed, current, authoritative, safe, complete, and useful.
Technical Explanation
The core pipeline has four movements. First, an object is prepared. In text systems, preparation often includes cleaning, splitting, chunking, preserving structure, and attaching metadata. Second, an embedding model maps the prepared object into a dense vector. Third, an index stores those vectors in a way that supports fast nearest-neighbor search. Fourth, a query is embedded and compared against the indexed vectors so the system can retrieve candidates.
Each movement introduces its own failure mode. If preparation is bad, the vector represents the wrong unit of meaning. If the embedding model is mismatched to the domain, the map itself may be wrong for your use case. If the index uses approximate search with poorly tuned recall, the right neighbor may not be found even when it exists. If the query is ambiguous, the nearest neighbors may answer the wrong intent. If ranking stops at cosine similarity, the system may surface the nearest text instead of the useful, authorized, or current one.
The most important discipline is to separate representation from decision-making. Embeddings represent. Retrieval proposes. Ranking decides. Policy constrains. Evaluation verifies. Monitoring watches. A system that collapses all of those into "vector search" will eventually fail in a way that looks surprising only because the architecture hid the distinction.
Table: What the Vector Layer Contributes and What the System Must Add
| Concern | Vector layer can help | Vector layer cannot guarantee | System control required |
|---|---|---|---|
| Semantic similarity | Finds nearby meaning and paraphrases | Correctness, authority, freshness | Reranking, metadata, source policy |
| Fuzzy matching | Handles wording variation | Exact IDs, SKUs, names, negation | Keyword/sparse lane and exact fields |
| Candidate retrieval | Produces a useful top-k list | Final answer quality | Evaluation and answer verification |
| Clustering | Groups related objects | Business category truth | Human labels and taxonomy mapping |
| Recommendation | Finds similar users/items | Diversity, fairness, safety | Exploration, constraints, monitoring |
| RAG context | Supplies possible evidence | Faithfulness of generated answer | Citations, grounded generation, evals |
Engineering Pattern
The practical pattern is to build a retrieval stack that keeps each responsibility explicit:
- Prepare the object with structure preserved.
- Embed the correct unit of meaning, not arbitrary blobs.
- Store metadata beside the vector, not in a separate forgotten spreadsheet.
- Retrieve more candidates than you plan to show.
- Filter by tenant, permission, status, date, locale, and product before anything is exposed.
- Combine dense vectors with sparse/keyword search when exact terms matter.
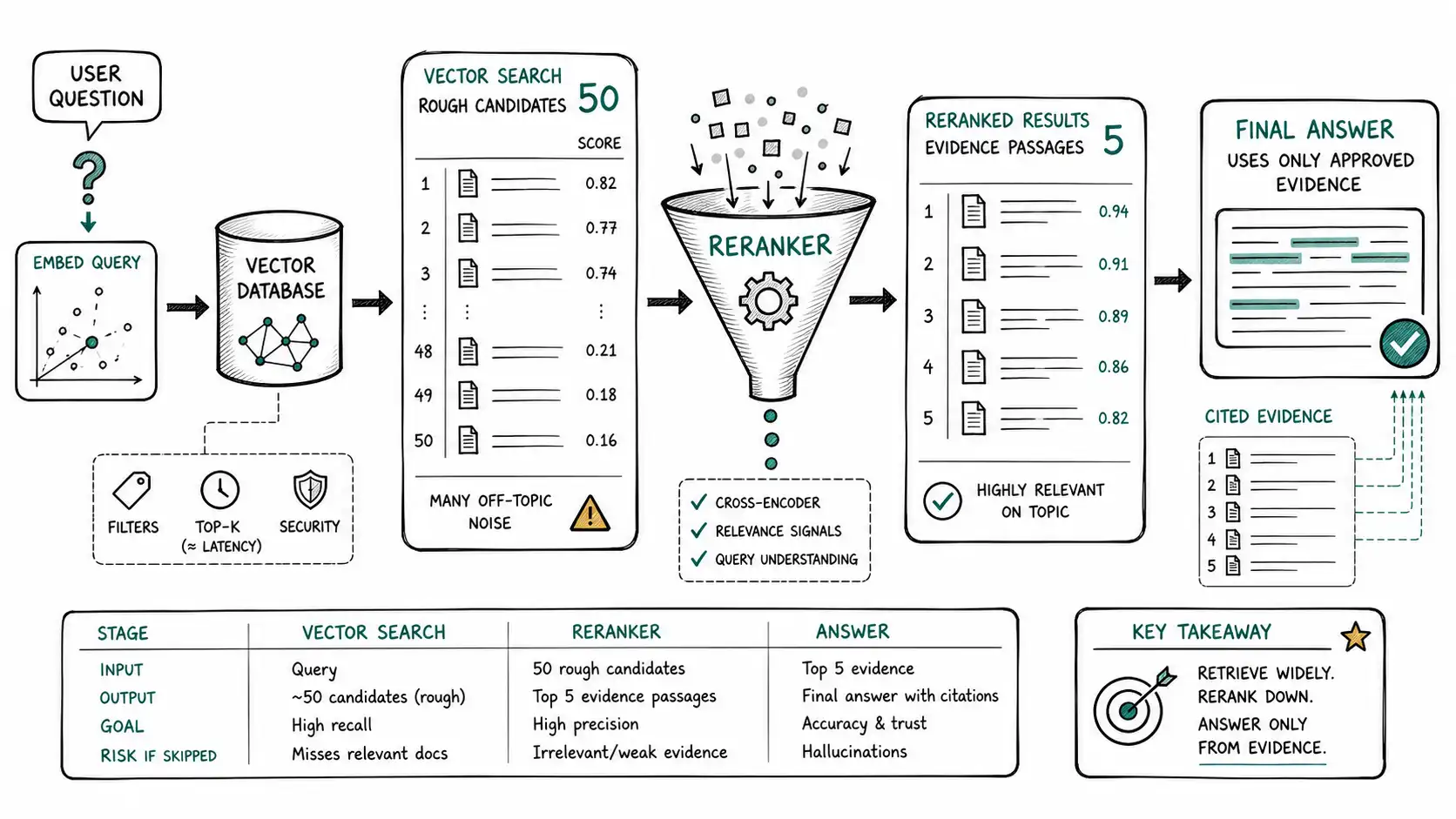
- Rerank candidates using a stronger relevance model when quality matters (see Elastic Rerank and Weaviate Hybrid for production reranking implementations; see RAG Eval Survey for evaluation frameworks that measure whether reranking actually helped).
- Evaluate retrieval separately from answer generation.
- Monitor drift, freshness, latency, cost, and failure cases after launch.
The pattern is intentionally boring. Production retrieval quality usually improves less from a heroic model choice than from disciplined object preparation, metadata, evaluation, hybrid search, and reranking.
Code / Config Example
def two_stage_retrieval(query):
candidates = vector_search(query, k=100)
# Reranker sees query and candidate text together, so it can judge relevance more directly.
reranked = cross_encoder_rerank(query, candidates)
return reranked[:10]The point of this example is not to prescribe a vendor or framework. The point is to expose the decision boundary. Wherever your production code hides this boundary, future debugging becomes forensic archaeology.
Failure Pattern
The most common failure in this chapter's territory is semantic over-trust. The system retrieves something that sounds right, and because it sounds right, the product treats it as right. This is especially dangerous in legal, healthcare, finance, HR, customer support, and internal knowledge-base systems where similar documents often coexist across versions, departments, jurisdictions, and approval states.
A good incident review does not stop at "the embedding returned the wrong result." It asks which missing control allowed the wrong result to become user-visible. Was the chunk boundary wrong? Was there no metadata filter? Did the index include drafts? Was there no freshness rule? Did the query need keyword matching for an exact identifier? Was the reranker absent? Did evaluation fail to include this class of query? The answer is rarely one thing. It is usually a chain of skipped controls.
Checklist
- Can we state exactly what object is being embedded?
- Do we know which facts are intentionally stored outside the vector?
- Are permissions, freshness, status, tenant, source, and version represented as metadata?
- Is vector similarity treated as candidate generation rather than final truth?
- Do exact identifiers have a keyword or structured-search path?
- Do we evaluate retrieval with realistic user queries?
- Do we monitor failures after launch instead of trusting the demo?
One-Sentence Takeaway
A vector is a shadow, not the object. The system must decide what the shadow is allowed to mean.
Deep Dive: Applying the Chapter Idea in Production
The chapter theme, Rerank Before You Believe, becomes important once a prototype leaves the notebook and starts serving messy users. Prototype retrieval systems are usually evaluated by the people who built them. Production retrieval systems are evaluated by users who do not share the builder's assumptions. They ask incomplete questions. They use product nicknames. They expect the newest policy, not the nearest old one. They assume permissions will be respected. They expect citations to support the answer. They do not care whether the vector database returned a high score.
For this chapter, the production stance is to make the hidden decision explicit. If the hidden decision is how to split documents, make chunking a design artifact. If the hidden decision is how to choose candidates, make retrieval strategy visible. If the hidden decision is how to trust output, make evaluation and governance part of the pipeline. If the hidden decision is cost, measure it before launch. The system becomes reliable when its implicit assumptions are turned into named controls.
A recurring pattern in successful embedding systems is two-stage humility. First, retrieve generously. Assume the first search stage is allowed to be rough. Bring back enough candidates to preserve recall. Second, decide carefully. Apply filters, reranking, metadata, policy, evidence checks, and evaluation. The teams that fail do the reverse: retrieve narrowly and then trust whatever appears. That gives a beautiful demo and a fragile product.
Production Design Questions
| Question | Why it matters | Failure if ignored |
|---|---|---|
| What is the retrieval unit? | Defines what the vector represents | Wrong or partial evidence |
| Which metadata is mandatory? | Restores source reality | Stale or unauthorized output |
| What is the fallback? | Prevents forced answers | Confident wrong answer |
| How is quality measured? | Converts demo into system | No regression detection |
| How are changes rolled out? | Supports safe migration | Ranking surprises after deploy |
Operational Guidance
Write a one-page design note before implementing this chapter's pattern. Include task definition, corpus shape, representation choice, metadata schema, retrieval strategy, reranking approach, evaluation set, security controls, monitoring signals, and rollback plan. That note will feel heavy for a prototype. It will feel light during the first incident.
When the system fails, do not start by changing models. Start by replaying the query through the pipeline. Show candidate generation. Show filters. Show reranking. Show final context. Show generated answer. Show citations. This makes errors visible. Visibility is more valuable than cleverness.
Extended Failure Analysis
Most failures in this chapter's territory are not random. They are patterned. A wrong result usually belongs to one of four classes: representation failure, retrieval failure, policy failure, or evaluation failure. Representation failure means the object embedded was not the object the user needed. Retrieval failure means the right object existed but was not found or ranked high enough. Policy failure means the wrong object was allowed through despite being stale, unauthorized, or low-authority. Evaluation failure means nobody had a test case for the scenario, so the regression was invisible until a user found it.
The fix should match the class. Representation failures are fixed with chunking, preprocessing, model choice, or metadata changes. Retrieval failures are fixed with hybrid search, larger candidate pools, better indexes, or reranking. Policy failures are fixed with filters, governance, ACLs, status fields, and source rules. Evaluation failures are fixed by adding labeled examples and regression gates.
Take This Into the Next Chapter
The next chapter builds on this one by treating embeddings not as magic objects but as system components. Keep asking: what does the vector know, what has it forgotten, and where does the system restore what was lost?