Graders, Rubrics, and Human Review
How to score model behavior without pretending judgment is simpler than it is.

A Score Is a Claim, Not a Fact
A team I worked with once shipped a release because the eval reported a 94 percent pass rate. Two weeks later the support queue told a different story. When we reopened the eval, the problem was not the model. It was the grader. A single regular expression was checking whether the answer contained a policy number, and most answers did contain the number, often inside a sentence that gave the wrong instruction. The grader was measuring presence. The product needed correctness. The 94 percent was real arithmetic on a false claim.
That is the central tension of this chapter. Every score is a claim about quality, and the claim is only as trustworthy as the grader that produced it. The reference set from the previous chapter decides which parts of reality enter the eval. The grader decides what counts as right. If the grader is wrong, a large, well-segmented, lovingly maintained reference set produces confident nonsense.
So the question is not "how high is the score." The question is "do I believe the thing that produced the score, on these cases, for this decision." This chapter is about earning that belief. We will build a ladder of graders from cheapest to most expensive, define rubrics that survive contact with disagreement, and design human review that produces signal instead of fatigue.
The motif from the introduction still holds. Measure the failure you can afford to prevent, not the benchmark you can afford to brag about. A grader exists to catch a specific failure class. If you cannot name the failure class a grader protects, you do not have a grader. You have a number generator.
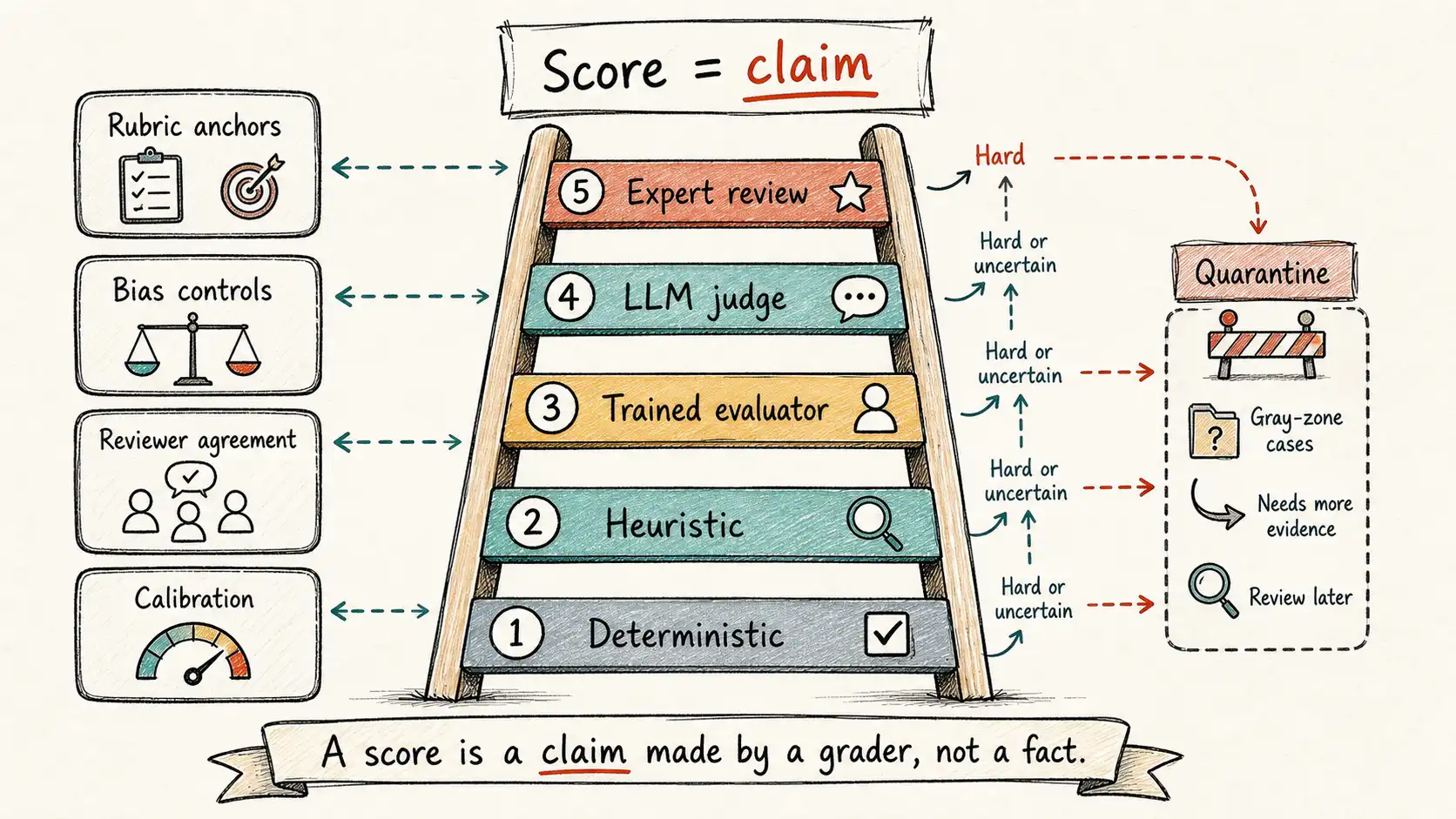
The Judge Trust Ladder
Not every case needs the same kind of judgment. A response that must be valid JSON can be checked by a parser. A response that must answer a customer's billing question accurately, with the right tone, citing the right policy, may need a human. Spending expert review time on cases a parser could have settled is how review queues collapse under their own weight.
The Judge Trust Ladder orders graders from cheapest and most reliable to most expensive and most fallible. The rule is simple: use the lowest rung that can defensibly settle the case, and reserve the higher rungs for the judgment they alone can provide.
- Deterministic check. Exact match, schema validation, regex on structured fields, numeric tolerance, set membership, presence of a required citation id. Fast, reproducible, cheap. It cannot judge meaning.
- Heuristic check. Token overlap, retrieval precision against a known evidence set, profanity filters, length bounds, format scoring. Useful as a guardrail and a cheap signal, weak as a verdict on quality.
- Trained evaluator. A classifier or scorer fit to labeled examples for a narrow judgment, such as "is this answer grounded in the provided source." Cheaper than a human at scale, but it inherits the biases of its training labels and degrades when the distribution shifts.
- LLM judge with rubric. A strong model scoring against an explicit rubric. Flexible, fast, and able to read meaning. Also biased, manipulable, and inconsistent in exactly the ways covered later in this chapter.
- Expert review. A human with domain authority applying the rubric. The most trustworthy and the most expensive. The only rung that can settle disputed policy, novel failure classes, and high-consequence cases.
Each rung should hand its hard cases up the ladder, not pretend to settle them. A deterministic check that cannot parse the output escalates to a human. An LLM judge that scores a case as borderline, or disagrees with the trained evaluator, escalates to expert review. The ladder is a routing system, not a hierarchy of prestige.
The economic logic is the same as a support tier system. You do not put your most senior engineer on the password reset. You route the password reset to automation and save the engineer for the incident no script can resolve. Treat reviewer attention as the scarce, expensive resource it is.
Build the Rubric Before You Build the Grader
A rubric is the operational definition of quality for a case type. It is the thing the label guide in the operating cadence chapter pointed at. Without it, every grader, human or machine, imports its own private standard, and your inter-rater agreement collapses for reasons that have nothing to do with the model.
A rubric should never be a single global "is this good." Quality is multidimensional, and the dimensions fail for different reasons. Score each dimension separately, with explicit anchors. Here is a worked generation rubric for a grounded customer support answer.
| Dimension | 0 (fail) | 1 (partial) | 2 (pass) | Weight |
|---|---|---|---|---|
| Groundedness | Claims not supported by provided source | Mostly supported, one minor unsupported detail | Every claim traceable to cited source | Critical |
| Correctness | Contradicts the source or policy | Correct but incomplete on a material point | Correct and complete for the asked question | Critical |
| Citation quality | No citation, or cites wrong section | Cites a relevant but imprecise section | Cites the exact governing section | High |
| Scope discipline | Answers a question outside policy or invents account data | Stays in scope but volunteers risky extras | Answers only what is supported, escalates when required | Critical |
| Tone and format | Violates format contract or is hostile | Acceptable, minor format issues | Meets format and tone promise | Medium |
Two design rules make this rubric do real work. First, critical dimensions are gating, not averaged. A response that fabricates account data scores zero on scope discipline, and that zero caps the overall verdict regardless of how fluent the prose is. Averaging a critical failure into a high overall score is exactly how the 94 percent in the opening scene happened. Second, every level has a behavioral anchor, not an adjective. "Mostly supported, one minor unsupported detail" is checkable. "Pretty good" is not.
The rubric should also state the abstention rule. For many products, the correct behavior is not an answer. The rubric must define when refusal, escalation, or a request for more context scores as a pass, so that a model is not penalized for declining a case it should decline. The reference set chapter insisted on including abstention cases. The rubric is where they get scored fairly.
The LLM Judge Is Useful and Biased
Using a strong model to grade other models is now standard practice, and for good reason. It scales, it reads meaning, and it can apply a rubric across thousands of cases overnight. It is also biased in measurable, reproducible ways that will silently corrupt your scores if you do not control for them.
The foundational study here is Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena by Zheng and colleagues. They documented three biases that matter for production eval design. Position bias: in a pairwise comparison, the judge tends to prefer whichever answer is presented first or second, independent of quality. Verbosity bias: the judge favors longer answers even when the extra length adds nothing or introduces errors. Self-enhancement bias: a judge tends to prefer answers produced by its own model family. The same paper found that a strong judge can still agree with human preference at roughly the rate two humans agree with each other, which is the reason to use the technique at all, and the reason never to trust it blind.
These are not abstract concerns. Verbosity bias directly rewards the failure mode many products are trying to suppress: confident, padded answers that bury uncertainty. A judge that prefers length will hand you a release that scores higher and serves worse.
Concrete controls, all of which belong in your judge harness:
- Randomize position in pairwise comparisons and run each pair in both orders. If the verdict flips when you swap order, record it as a tie or escalate it. Do not let presentation order decide your release.
- Control for length. Either constrain both candidates to comparable length, or include length as a logged covariate so you can see whether the judge's preference tracks quality or word count.
- Never let a model judge its own family in a high-stakes comparison. Use a different model as judge, or require human confirmation when the judge's family matches the candidate.
- Force structured output with reasons. Require the judge to emit a per-dimension score and a short justification quoting the source. A judge that must cite its reasoning is easier to audit, and the reasons surface cases where the score is right for the wrong cause.
- Pin and version the judge. A judge is a model with a prompt. Both change. Record the judge model id, judge prompt version, and rubric version on every score, exactly as the operating cadence chapter requires for the candidate. A score whose judge you cannot reproduce is an anecdote.
Here is a judge prompt skeleton that bakes in these controls. The limitations are written into the artifact on purpose.
ROLE: You are grading one support answer against a fixed rubric.
You are not the customer. You are not improving the answer.
INPUTS:
question: <user question>
provided_source: <the only evidence the answer may use>
policy_section: <the governing policy text>
candidate: <answer to grade>
RULES:
- Judge ONLY against provided_source and policy_section.
- If a claim is not traceable to the source, score Groundedness 0.
- Longer is not better. Penalize unsupported additions.
- If the correct behavior is to escalate or refuse, a correct
escalation scores 2 on Correctness and Scope.
OUTPUT (JSON):
{ "groundedness": 0|1|2, "correctness": 0|1|2,
"citation": 0|1|2, "scope": 0|1|2, "tone": 0|1|2,
"critical_failure": true|false,
"evidence_quote": "<exact span from source supporting your call>",
"rationale": "<two sentences>" }
LIMITATIONS (the harness enforces these, not you):
- Position and length controls applied upstream.
- Your verdict is a signal, not a release decision.
- Borderline or critical-failure cases route to human review.The point of writing limitations into the artifact is cultural. Anyone who reads this prompt understands that the judge produces a signal that feeds the Judge Trust Ladder, not a verdict that ships software.
Humans Disagree, and That Is Data
Human review is the top of the ladder, and it has its own failure mode: people are inconsistent, and worse, they can be consistently wrong together. Two reviewers who share a blind spot will agree at a high rate and feel calibrated while measuring nothing. So you have to measure the reviewers, not just trust them.
The right tool is a chance-corrected agreement coefficient. Raw percent agreement is misleading because two reviewers will agree by luck a large fraction of the time, especially on skewed label distributions where almost everything passes. The survey by Artstein and Poesio, Inter-Coder Agreement for Computational Linguistics, lays out the options clearly. Cohen's kappa corrects for chance agreement between two annotators. Krippendorff's alpha generalizes to many annotators, missing data, and weighted disagreement, which matters when a one-versus-two error is less serious than a zero-versus-two error.
A practical reading of these coefficients for eval work:
| Coefficient value | Interpretation | Action |
|---|---|---|
| Below 0.40 | Reviewers are not applying a shared standard | Rubric is broken or the case type is a policy dispute, not an eval problem |
| 0.40 to 0.60 | Moderate, usable for triage, not for gating | Add anchors to the contested dimension, recalibrate |
| 0.60 to 0.80 | Good, suitable for release gating with audit | Keep monitoring drift, audit a sample |
| Above 0.80 | Strong, or suspiciously easy | Confirm it is not a shared blind spot using audit cases |
When agreement on a dimension is persistently low, resist the urge to "train the reviewers harder." Low agreement is usually a signal that the rubric is underspecified or that the underlying question is an unresolved product policy. As the operating cadence chapter argued, if reviewers keep fighting about refund exceptions, the company has a refund policy gap, not a labeling problem. No amount of grader engineering fixes an undecided policy.
Build calibration into the review process structurally:
- Seed hidden gold cases. Mix in cases with a known, expert-settled answer at roughly five to ten percent of every review batch. A reviewer whose accuracy on gold cases drops is fatigued or drifting, and their recent labels deserve audit before they enter the release set.
- Double-label a sample. Have two reviewers independently score the same ten to twenty percent of cases and compute alpha on that sample every cycle. Track the trend, not just the snapshot.
- Adjudicate disagreements with a third party, and feed the adjudication back into the rubric as a new anchor. Disagreements are the cheapest source of rubric improvement you have.
- Rotate reviewers across case types to prevent a single person's idiosyncrasy from becoming the de facto standard for a workflow.
When the Grader Cannot Decide
Some cases should not be force-graded. A response can be in a genuine gray zone where the source is ambiguous, the policy is silent, or the question itself is unanswerable. Forcing a verdict on these cases injects noise that drowns the signal you care about.
This is where conformal prediction, in the gentle introduction by Angelopoulos and Bates, offers a useful mental model even when you are not implementing the full machinery. Conformal methods produce prediction sets calibrated to a chosen error rate, and crucially they let a system say "I am not confident enough to commit to one answer" in a statistically principled way. Translated to grading: a grader should be allowed to abstain. A trained evaluator or LLM judge that lands inside a calibrated band of uncertainty should route the case up the ladder to a human rather than emitting a brittle 0 or 2.
The operational version is a quarantine lane, the same one the operating cadence chapter described for the weekly sample. A case is quarantined when the judge is uncertain, when two reviewers disagree past adjudication, or when the expected answer depends on a policy that does not yet exist. Quarantined cases do not count toward the pass rate. They count toward the backlog of decisions product and policy owners must make. Hiding gray-zone cases inside a confident average is how a team manufactures false precision and ships on it.
The Grader Coverage Map
Before any release run, a team should be able to point at every dimension of its rubric and name which rung of the Judge Trust Ladder grades it. Gaps in that map are where false confidence lives. Use this worksheet for one case type.
| Rubric dimension | Grader rung | Specific check | Escalation trigger | Owner |
|---|---|---|---|---|
| Format valid | Deterministic | JSON schema parse | Parse failure | Platform |
| Citation present | Deterministic | Required citation id field non-empty | Missing id | Platform |
| Groundedness | LLM judge then human | Judge scores against source, audit 10 percent | Judge score 0 or 1, or judge uncertain | Reviewer lead |
| Correctness | Human | Expert applies rubric on sampled and incident cases | Always reviewed for incident-regression cases | Domain expert |
| Scope discipline | LLM judge then human | Judge flags out-of-scope, human confirms | Any critical_failure flag | Product owner |
| Tone | Heuristic | Length bounds, banned-phrase list | Out of bounds | Reviewer lead |
The map exposes two common failures at a glance. First, a critical dimension graded only by a deterministic check, which means you are measuring presence and calling it correctness. Second, a dimension with no escalation trigger, which means uncertain cases get force-graded into the average. Fix both before you trust the run.
Common Mistakes
The first mistake is averaging critical failures into a high overall score. Fabricated account data and a polished tone should never net out to "pretty good." Make critical dimensions gating.
The second mistake is trusting an LLM judge without bias controls. If you have not randomized position, controlled for length, and barred self-family judging, your judge has a thumb on the scale and you cannot see which way it leans.
The third mistake is reading raw percent agreement as proof of reviewer quality. Use a chance-corrected coefficient. High raw agreement on a skewed distribution is the easiest false comfort in the whole eval program.
The fourth mistake is treating low inter-rater agreement as a training problem when it is a policy problem. If reviewers cannot agree, the rubric or the product policy is undecided. No score can paper over a decision the business has not made.
The fifth mistake is forcing a verdict on gray-zone cases. A grader that cannot abstain will manufacture precision it does not have. Build a quarantine lane and let uncertain cases route up the ladder.
Practical Exercise
Take one case type from your reference set and do the following in one sitting.
- Write the multidimensional rubric with behavioral anchors at each level. Mark which dimensions are critical and gating.
- For each dimension, assign a rung on the Judge Trust Ladder and fill in the grader coverage map above. Circle any critical dimension graded only by a deterministic or heuristic check.
- Write the LLM judge prompt with position and length controls and a structured, citation-bearing output.
- Take twenty cases. Have two people label them independently against the rubric. Compute percent agreement and Cohen's kappa. Note every dimension where kappa is below 0.60.
- For each low-agreement dimension, decide whether the fix is a sharper anchor or an escalation to product policy. Write down which.
If kappa is low everywhere, stop building graders. You have a rubric or policy problem, and grading harder will only spread the confusion across more cases.
Summary
A score is a claim about quality, and the grader is the thing making the claim. The Judge Trust Ladder routes each case to the cheapest grader that can defensibly settle it, escalating meaning, dispute, and high consequence upward to humans. Rubrics turn vague quality into multidimensional, anchored, gating judgments that fail for nameable reasons. LLM judges scale that judgment but carry position, verbosity, and self-enhancement biases that must be controlled in the harness, not wished away. Human review is the top rung, and it has to be measured with chance-corrected agreement, calibrated with hidden gold, and protected from the false comfort of shared blind spots. Cases the system cannot confidently grade belong in quarantine, not in the average.
The next chapter connects these scores to the decisions they exist to serve. A trustworthy grader is necessary but not sufficient. The team still has to decide which movements in a score justify shipping, holding, rolling back, or narrowing a rollout, and how to make that call when the evidence is noisy and the pressure is high.
Key Takeaways
- A score is only as trustworthy as the grader that produced it. Name the failure class each grader protects.
- The Judge Trust Ladder routes cases to the cheapest defensible grader and escalates meaning and consequence to humans.
- Rubrics must be multidimensional, anchored to behavior, and gating on critical dimensions so fluency cannot mask fabrication.
- LLM judges carry position, verbosity, and self-enhancement biases. Randomize order, control for length, bar self-family judging, and version the judge.
- Measure reviewers with chance-corrected agreement, not raw percent. Seed hidden gold and double-label a sample every cycle.
- Persistent low agreement is a rubric or policy problem, not a training problem.
- Let graders abstain. Quarantine gray-zone cases instead of forcing false precision into the average.