The First Ninety Days of Eval-Led Delivery
A staged plan for moving from scattered examples to a maintained evaluation system.

Why Most Eval Programs Die in Month Two
The most common way an eval program fails is not a bad metric or a weak grader. It is abandonment. A team reads a book like this one, gets excited, builds an ambitious evaluation platform with a hundred cases and a dashboard, ships it, and then watches it rot. By week six the cases are stale, nobody owns the review, the dashboard shows a number no one acts on, and the next release goes out on a demo and a gut feeling. The infrastructure survives. The discipline does not.
I have watched this happen often enough to believe the problem is sequencing. Teams try to build the whole system before they have earned the habit of using any of it. They optimize for the artifact instead of the behavior. The artifact is a dashboard. The behavior is a team that does not ship a regression because the gate said no and the team respected the gate.
This closing chapter is a ninety-day plan to build the behavior first and let the system grow underneath it. It assembles everything the earlier chapters established: the product promise and failure classes from chapter one, the reference set from chapter two, the graders and rubrics from chapter three, the regression gates from chapter four, and the operating cadence from chapter five. The plan is staged on purpose. Each phase produces something that changes a real decision before the next phase begins. If a phase does not change a decision, you stop and fix that before adding scope.
The motif of the book is the design constraint for the whole ninety days. Measure the failure you can afford to prevent, not the benchmark you can afford to brag about. Every artifact you build in this plan should trace back to a specific production failure you are trying to stop from recurring. If you cannot name the failure, do not build the artifact yet.
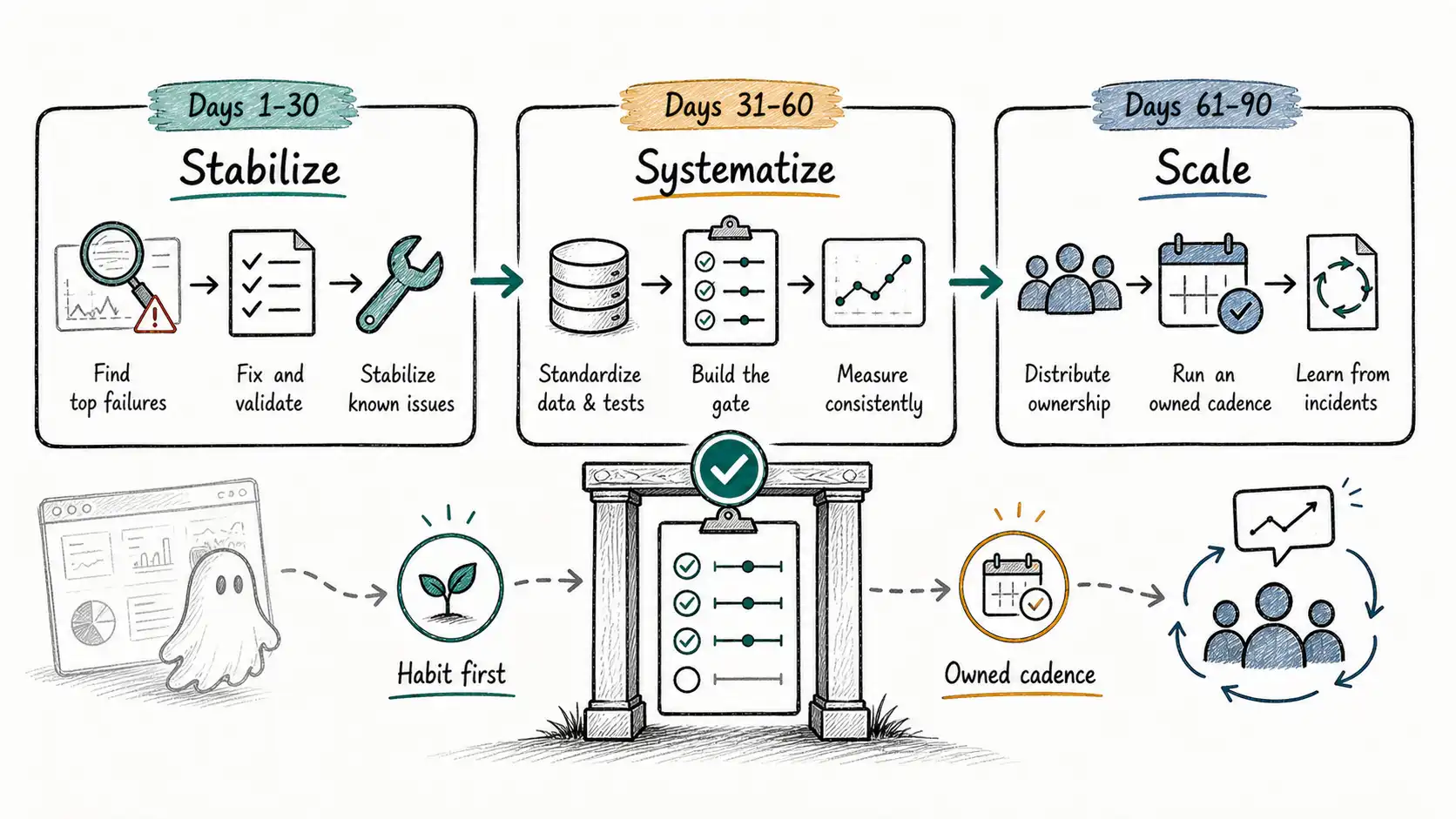
The Shape of the Plan
The ninety days run in three thirty-day phases, each with a single dominant goal.
| Phase | Days | Dominant goal | The decision it must change |
|---|---|---|---|
| Stabilize | 1 to 30 | Stop repeating known failures | Block one release that would have shipped a known regression |
| Systematize | 31 to 60 | Make the gate trustworthy and routine | Run the gate on every release without a hero doing it manually |
| Scale | 61 to 90 | Make the system maintainable and owned | Hand the cadence to named owners and survive a real incident |
The phases are deliberately not equal in difficulty. The first phase is the hardest, because it is where the habit is born and where the team is most tempted to skip to tooling. The Google ML Test Score rubric is a useful companion through all three phases, because it scores production readiness across data, model, infrastructure, and monitoring, and it rewards teams for having tests that run automatically and are acted upon, not merely tests that exist. Use it as a self-audit at the end of each phase: not "do we have a test," but "does the test run, and does anyone act on it."
Phase One: Stabilize (Days 1 to 30)
The goal of the first month is narrow and unglamorous: stop repeating the failures you already know about. You are not building a platform. You are proving that an eval can block a bad release.
Week 1: Write the promise and harvest failures. Start where chapter one started. Write the product promise for one workflow in plain operational language: what the system may do, what evidence it must use, what is out of scope, when it escalates. One workflow, not all of them. Then harvest failures. Pull the last quarter of support escalations, incident tickets, refunds caused by the system, and angry-customer transcripts for that one workflow. Do not write synthetic cases yet. The failure-first method means your first cases come from real damage.
Week 2: Build the seed reference set and failure taxonomy. Turn each harvested failure into a normalized case using the schema from chapter two: source, task type, expected behavior, required evidence, disallowed behavior, risk tier, failure class, owner. Aim for 30 to 50 cases. Most should be incident-regression cases, because preventing repeats is this month's only job. Tag every case with a failure class from your taxonomy. By the end of the week you should be able to say "these are the eight failure classes that have actually hurt us, and here are the cases that catch each one."
Week 3: Write the rubric and the cheapest defensible graders. Build the multidimensional rubric from chapter three for this one case type, with gating critical dimensions. Then grade with the lowest rungs of the Judge Trust Ladder that work: deterministic checks for format and citation presence, an LLM judge with a versioned prompt for groundedness and scope, and a human reviewer for the incident-regression cases and anything the judge flags as uncertain. Do not build a trained evaluator this month. It is premature optimization.
Week 4: Write the first gate and use it once. Write the gate from chapter four as block, warn, and ship conditions. Make every harvested incident an absolute block: if a case from a past incident reopens, the release is blocked, full stop. Then do the thing that makes this real. Run the gate against your next candidate release. If it would have blocked a regression, you have proven the program's value in thirty days. If everything passes trivially, your cases are too easy and you go back and add the hard ones.
The phase-one exit criterion is a single sentence: the gate blocked, or could have blocked, at least one release that would otherwise have shipped a known failure. If you cannot say that, do not advance. The behavior is not born yet.
Phase Two: Systematize (Days 31 to 60)
The second month removes the hero. In phase one, the gate ran because one motivated person ran it. That does not survive contact with a busy quarter. The goal now is to make the gate routine, trustworthy, and automatic enough that it runs on every release whether or not anyone feels like it.
Week 5: Wire the gate into the release pipeline. Move the gate from a manual script someone remembers to run into CI, so it runs automatically on every candidate. The configuration is the gate YAML from chapter four, versioned alongside the rubric. The output is the five-question release memo, generated automatically and posted where the team makes release decisions. The point is that skipping the gate should now require a deliberate, visible override, not just forgetting.
Week 6: Establish the weekly sample and the calibration loop. Stand up the weekly production sample from chapter five with a published sampling rule. Begin double-labeling ten to twenty percent of reviewed cases and computing chance-corrected agreement, using the coefficients from chapter three. This is the week you find out whether your reviewers actually agree. If Krippendorff's alpha is below 0.60 on a gating dimension, that dimension is not ready to gate releases, and you treat the low agreement as a rubric or policy problem to resolve, not a number to ignore.
Week 7: Add segmentation and confidence intervals to the gate. The phase-one gate probably watched a global number. Now make it read segments and report intervals, as chapter four requires. Identify your high-cost segments, enterprise, regulated, high-revenue, and give each its own gate condition. Add the paired, case-by-case fixed-versus-broken view so the team can see the actual trade a change makes, not just two averages. This is the week the gate stops being foolable by a change that improves the easy majority and quietly regresses the expensive minority.
Week 8: Add a shadow eval. Stand up the first production-time gate from chapter four: run the candidate against live traffic without exposing it to users, and grade the measurable properties, latency, refusal rate, format validity, retrieval coverage. The first time the shadow eval flags a failure class that your offline set never contained, you will understand viscerally why the reference set must keep being refreshed. That moment is the most important learning of phase two.
The phase-two exit criterion: the gate runs automatically on every release, reads segments with confidence intervals, and a reviewer-agreement number is computed and trending. The hero is removed. A release cannot quietly skip the gate.
Phase Three: Scale (Days 61 to 90)
The third month makes the program durable. The gate is trustworthy and routine. Now it has to survive ownership changes, a real incident, and the slow decay that kills eval programs. The goal of phase three is to hand the cadence to named owners and prove it survives a crisis.
Week 9: Assign owners and write the operating calendar. Every recurring activity from chapter five gets a named owner: the weekly sample, the rubric and label guide, the score run, the triage meeting, the release gate, the monthly review, and the incident response. Ownership is a name, not a team. "The platform team owns the sample" is how things rot. "Priya owns the weekly sample and Marco backs her up" is how things survive. Write the maintenance calendar that says what gets reviewed weekly, what monthly, and what is triggered by events.
Week 10: Build the incident-to-eval pipeline. Codify the loop that turns every production incident into eval cases. The template, drawn from chapter five, captures affected version, time window, segment, failed evidence, failure class, corrective action, owner, and the new cases added to the set. Then test it for real on the next incident, or run a deliberate fire drill on a past one. The pipeline is not done until an incident has flowed through it end to end and produced new regression cases that the gate now blocks on.
Week 11: Add a canary and the rollback runbook. Stand up the canary gate from chapter four: ship to a small live slice with guardrail metrics and automatic rollback. Write and test the rollback runbook before you need it: revert command, data implications, customer-communication trigger, time-to-restore, owner. A program that can block and shadow but cannot safely roll back is still incomplete. Test the revert on a staging release so the first real rollback is not also the first rehearsal.
Week 12: Run the readiness review and plan refresh. Close the ninety days with the production eval readiness review below, and then schedule the maintenance that keeps the system alive: weekly sampling, monthly set refresh and case retirement, quarterly rubric and segment review, and standing incident triggers. The system is not finished, because eval systems are never finished. It is now maintained, which is the only state that matters.
The phase-three exit criterion is the strongest of the three: the cadence has named owners, an incident has flowed through the incident-to-eval pipeline and produced new gate cases, and the rollback path has been tested. The program now survives the people who built it.
The Production Eval Readiness Checklist
This is the checklist the introduction promised and the artifact to run at day ninety and quarterly thereafter. Treat any "no" as a backlog item with an owner, not a reason for shame.
| Area | Question | Ready? |
|---|---|---|
| Promise | Is there a written product promise for each gated workflow? | |
| Failure-first | Does every reference case trace to a real or named failure class? | |
| Reference set | Are release, exploratory, and incident-regression sets kept separate? | |
| Sources | Is the set built from traffic, incidents, policy edges, and targeted synthetics? | |
| Segmentation | Does every release report break out high-cost segments with intervals? | |
| Rubric | Are critical dimensions gating, with behavioral anchors at each level? | |
| Graders | Does every rubric dimension map to a Judge Trust Ladder rung? | |
| Judge controls | Are position, length, and self-family biases controlled and the judge versioned? | |
| Human review | Is chance-corrected agreement computed, with hidden gold seeded? | |
| Quarantine | Can graders abstain, and do gray-zone cases stay out of the average? | |
| Gate | Are block, warn, and ship conditions agreed before each run? | |
| Significance | Are score moves checked against the noise band before being called real? | |
| Decisions | Are ship, narrow rollout, hold, and rollback all available and defined? | |
| Production gates | Do shadow and canary gates run, with automatic rollback tested? | |
| Cadence | Does a weekly sample, score run, triage, and monthly review happen on schedule? | |
| Ownership | Does every recurring activity have a named owner and a backup? | |
| Incidents | Does every incident produce new regression cases through a defined pipeline? | |
| Ledger | Is every release decision recorded with evidence, scope, and unresolved risk? | |
| Refresh | Are stale cases retired and the set refreshed when policy or corpus changes? |
A program that can answer yes across this checklist is doing release discipline for probabilistic systems. That phrase is the whole point of the book. Deterministic software has tests and merge gates. Probabilistic software needs the same discipline, adapted for the fact that its outputs are distributions and its quality is multidimensional. Evals are how you get release discipline for systems that cannot be unit tested into certainty.
Common Mistakes
The first mistake is building the platform before the habit. A dashboard nobody acts on is worse than a spreadsheet that blocks a release, because the dashboard looks like progress. Build the behavior first.
The second mistake is starting with synthetic cases. In month one, your cases should come from real damage. Synthetic pressure tests are valuable later, as chapter two argued, but starting there means you are testing your imagination instead of your incidents.
The third mistake is skipping the calibration loop. If you never compute reviewer agreement, you are gating releases on labels you have not validated. The number can be high while the labels are confidently wrong together.
The fourth mistake is leaving the gate as a manual hero task. If running the gate depends on one motivated person remembering, it will be skipped in the exact busy quarter when it matters most. Wire it into the pipeline so skipping requires a visible override.
The fifth mistake is declaring victory at day ninety. The system is not finished. It is maintained. The work that keeps it alive, refresh, retirement, recalibration, and incident learning, is the work that prevents the month-two death described at the start of this chapter.
Practical Exercise
Plan your own ninety days on one page before you write a single eval case.
- Name the one workflow you will start with and write its product promise in five sentences.
- List the failure classes that have actually hurt that workflow in the last quarter, with one real incident per class.
- For phase one, write the single exit sentence: which release would the gate have blocked.
- For phase two, name the person who will remove themselves as the hero by wiring the gate into CI.
- For phase three, name the owner of each recurring activity and their backup, and pick the past incident you will run through the incident-to-eval pipeline as a fire drill.
If you cannot name the workflow, the failures, and the owners, you are not ready to start the platform. You are ready to start the conversation that produces them, which is itself a good use of day one.
Summary
Eval programs do not usually die from bad metrics. They die from abandonment, because teams build the system before they build the habit. The ninety-day plan inverts that. Phase one stabilizes by turning real failures into a gate that blocks at least one bad release. Phase two systematizes by removing the hero, wiring the gate into CI, segmenting it, calibrating reviewers, and adding a shadow eval. Phase three scales by assigning owners, building the incident-to-eval pipeline, adding a canary with tested rollback, and running the readiness review. At day ninety the system is not finished, because it never is. It is maintained, owned, and trusted when the release decision is hard.
That is the whole argument of this field guide in one sentence. An eval is not a scoreboard. It is a production alarm designed before production breaks, and the ninety-day plan is how a team earns the right to trust the alarm. Evals are release discipline for probabilistic systems. Build the discipline, and the system will follow.
Key Takeaways
- Eval programs die from abandonment, not bad metrics. Build the habit before the platform.
- Phase one stabilizes: turn real failures into a gate that blocks one bad release within thirty days.
- Phase two systematizes: wire the gate into CI, segment it with intervals, calibrate reviewers, and add a shadow eval.
- Phase three scales: assign named owners, build the incident-to-eval pipeline, add a canary with tested rollback.
- Start from real incidents, not synthetic cases. Synthetics come later, once the habit holds.
- Run the production eval readiness checklist at day ninety and quarterly. Treat every no as an owned backlog item.
- The system is never finished. It is maintained. Maintenance is what prevents the month-two death.