Operating Cadence
A practical operating rhythm for keeping evaluation suites aligned with production traffic, release risk, and business decisions.

Key Takeaways
- An eval suite stays useful only when it is tied to weekly samples, release decisions, and incident learning.
- The cadence starts with fresh evidence from traffic, support, release notes, and reviewer disagreement.
- Monthly review and incident triggers keep the suite aligned with product behavior instead of stale launch assumptions.
The Cadence Problem
An evaluation suite is not a folder of tests. It is a management system for deciding when a model change, prompt change, retrieval change, or product change is safe enough to ship. The mistake most teams make is treating evals as a one-time launch artifact. They build the first set, celebrate the first passing score, and then let the suite drift away from production traffic. Within a few releases, the score still looks orderly, but the product has moved.
The research base points in the same direction. OpenAI's evals guidance frames evaluations as a way to test outputs against criteria a team specifies, especially when models or behavior change. The NIST AI Risk Management Framework separates risk work into govern, map, measure, and manage. Google's ML Test Score research makes the same production point from another angle: readiness includes tests, infrastructure, and monitoring, not just model accuracy.
Chapter 5 is the operating layer of A Field Guide to Evals. Earlier chapters define the production problem, the reference system, the measurement logic, and the failure modes. This chapter asks a narrower question: who does what every week, every release, every month, and every incident so the evaluation suite remains true to the product?
Research First, Ritual Second
The cadence should not start with a ceremony. It should start with topic research. For evals, research means inspecting live traffic, reading support failures, reviewing release notes, studying reviewer disagreement, and checking external failure literature before deciding what the suite or release gate should contain. A weekly meeting without that evidence becomes a status ritual. A weekly meeting with the evidence becomes a decision forum.
The operating cadence has to absorb three kinds of research. First, product research tells the team what users are actually asking the system to do. Second, technical research tells the team where the system is structurally weak, such as retrieval gaps, instruction conflicts, unstable tool calls, or grading ambiguity. Third, risk research tells the team which failures matter most to customers, compliance, security, support, and revenue. The chapter outline should follow those findings, not the other way around.
This is also why eval work should link to adjacent operating books inside the site instead of appearing as detached references. When a failure is caused by missing evidence, the next reading is Retrieval That Survives Contact. When a failure comes from an autonomous workflow crossing a boundary, the next reading is Agents That Actually Work. When the problem is reproduction, trace quality, or release comparison, the work belongs beside Observability for AI Systems.
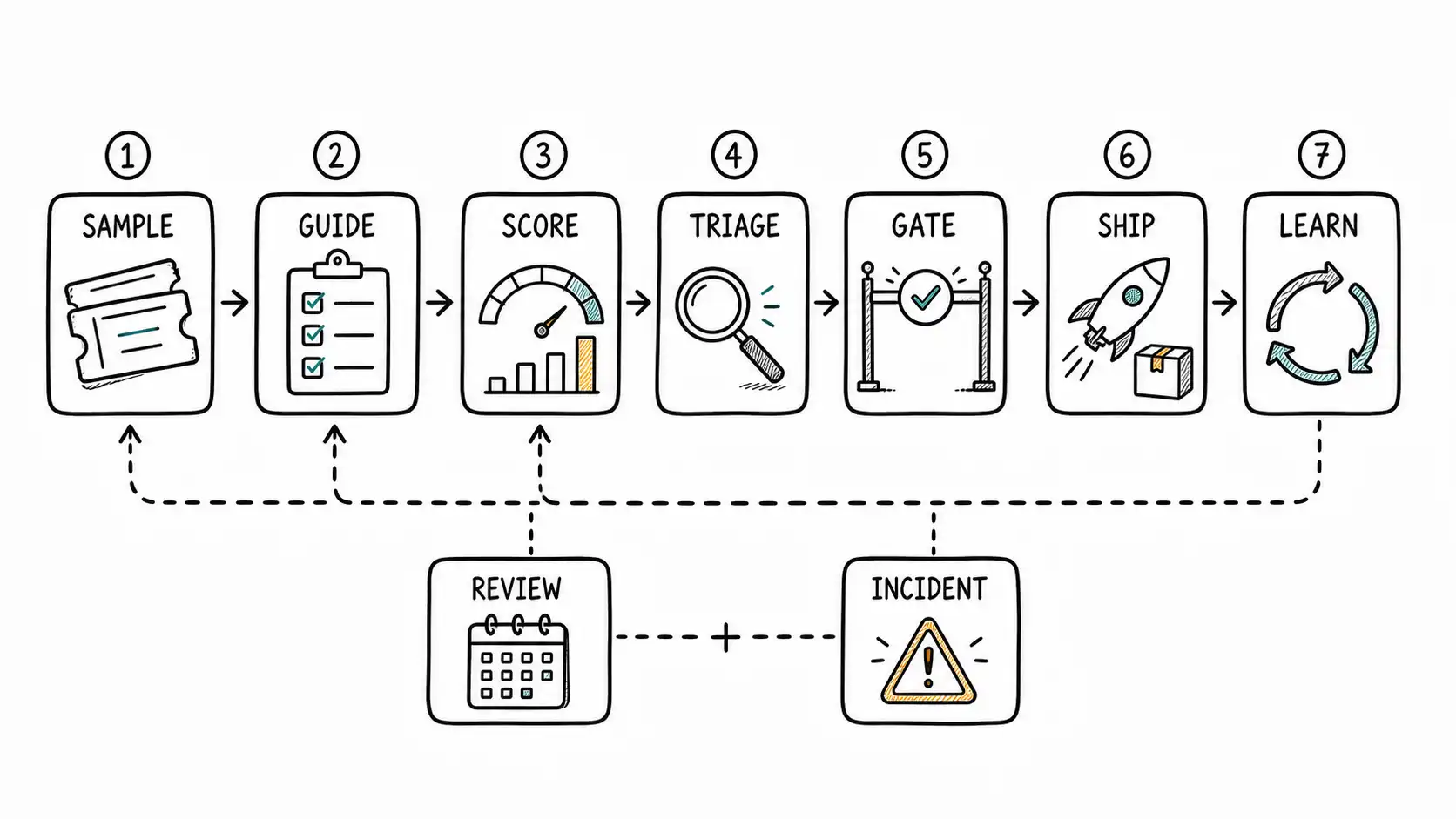
The Outline That Follows
Once the research is done, the chapter outline becomes straightforward. Start with the sample because the sample defines what reality enters the suite. Move to the label guide because reviewers need a shared definition of quality before any score can be trusted. Run the score after those two pieces are stable. Triage the failures only after the score is segmented. Gate the release only after triage has assigned owners. Ship only the scope supported by evidence. Then feed what was learned back into the next sample.
This order matters. Teams often want to start with tooling because tooling feels concrete. The better order starts with the decision the company needs to make. If the decision is whether a new version can serve a larger account segment, the eval has to include that segment's tasks. If the decision is whether a retrieval change is safe, the eval has to include source quality and answerability. If the decision is whether an agent can act without approval, the eval has to include tool-use boundaries and escalation cases.
The outline also prevents overbuilding. A small team does not need an elaborate governance calendar on day one. It needs a weekly sample, a written guide, a repeatable score run, a triage owner, and a release rule. The monthly review and incident trigger can be lightweight at first, but they must exist. Otherwise the suite will age quietly until the first serious customer failure forces a rushed rebuild.
The Weekly Sample
Every week needs a fresh sample from production-shaped work. Not all of it has to come from live users, but the sample should represent the current product surface. Include ordinary successful cases, known edge cases, recent support issues, failed handoffs, low-confidence outputs, and examples from any new feature or source. A stale sample set is the fastest way for an evaluation program to become decorative.
The sample owner should publish the sampling rule before reviewing the examples. That rule might say: twenty routine cases, ten high-risk cases, ten recent failures, ten cases from the newest traffic class, and five synthetic pressure cases that target a known weakness. The exact numbers matter less than the principle. The team should know why the cases exist and what decision they can change.
A good weekly sample also keeps a quarantine lane. These are cases the team is not ready to score because the expected answer is disputed, the source of truth is missing, or the policy is unclear. Quarantine prevents the suite from absorbing bad labels under deadline pressure. It also gives product and policy owners a visible backlog of decisions they must make before autonomy expands.
The Label Guide
The label guide is the constitution of the eval. It defines what a pass means, what a fail means, what counts as partial credit, what evidence is required, and what reviewers should do when the expected answer is ambiguous. Without a label guide, the team is not measuring the model. It is measuring the mood, memory, and preferences of whoever reviewed the examples that week.
This is where the lesson from Hidden Technical Debt in Machine Learning Systems matters. Production systems accumulate debt through data dependencies, configuration choices, undeclared consumers, and changes in the external world. In evals, the label guide is one of the places that debt becomes visible. If reviewers keep arguing about the same class of example, the system may not have an evaluation problem. It may have a product-policy problem that no score can solve.
The guide should be reviewed on a monthly cadence and after any major incident. Do not revise it silently. Version it, note why the change happened, and rerun affected historical examples when the change alters the meaning of previous scores. A label guide that changes without replay breaks the trend line and makes release comparison unreliable.
The Score Run
The score run is the mechanical part of the cadence, but it should still be treated as an operating event. Run the suite against the candidate version, the current production version, and any relevant fallback version. Record the model, prompt, retrieval configuration, tool permissions, source snapshot, grader version, and label-guide version. A score without configuration is an anecdote with a number attached.
Segment the score before discussing it. The overall pass rate can hide the failures that matter. Break results down by task type, user intent, source quality, risk tier, language, customer segment, and workflow stage. If the product has a premium workflow, a regulated workflow, or a high-revenue workflow, it deserves its own segment. The business needs to know where the system is safe, not only whether the average improved.
The score run should produce a short release memo, not a dashboard screenshot. The memo should answer four questions: what changed, what improved, what regressed, and what decision is recommended. The recommendation must name the gate: ship, ship behind a narrower rollout, hold for repair, or roll back. Anything softer pushes the hard decision into a meeting where urgency will overpower evidence.
Triage And Ownership
Triage starts after the score run, not before. First classify the failures by cause: bad source, missing context, prompt ambiguity, grader weakness, tool failure, policy gap, unsupported request, product bug, or model limitation. Then assign each class to an owner. A failure class with no owner will recur until users become the monitoring system.
The triage meeting should be small enough to decide. It usually needs an engineering owner, a product owner, a reviewer lead, and whoever owns the source of truth. Security, legal, support, or customer success should join only for the cases that touch their domain. Large review meetings create the appearance of governance while slowing down the fixes that actually reduce risk.
The most important triage habit is to separate repair from expansion. A team should not widen the system's scope in the same cycle where high-cost regressions are unresolved. Expansion is earned by stable evidence. This is the point where eval cadence becomes business discipline. It protects margin, support load, customer trust, and sales promises from a roadmap that moves faster than proof.
The Release Gate
The release gate is where the team stops admiring the score and makes a decision. A gate should have thresholds that were agreed before the run. For example: no critical regressions in high-risk tasks, no unsupported claims above an agreed rate, no unresolved reviewer disagreement in regulated workflows, and no latency or cost movement that breaks the product promise. The thresholds should reflect the business consequence of failure, not a generic target copied from another team.
NIST's risk framing is useful here because it keeps measurement connected to management. A team that measures but does not manage is collecting evidence without changing behavior. A team that manages without measurement is relying on seniority and instinct. The gate forces both sides together: evidence becomes a release decision.
The gate should also define partial release patterns. Not every failure blocks every launch. Some changes can ship to a low-risk segment, a smaller account group, an internal workflow, or a path with human approval. The point is not to be conservative by default. The point is to make the release shape match the evidence. That is how a company keeps moving while respecting what the eval has learned.
The Decision Ledger
Every cadence needs a decision ledger. This is not a heavy governance artifact. It is a simple record of the decision made, the evidence used, the owner, the scope, the unresolved risks, and the next review date. The ledger is what lets a team explain why a release was approved three weeks later, when nobody remembers the exact examples that changed the room.
The ledger should capture the negative decisions too."Held because retrieval recall dropped in enterprise policy questions" is more useful than a vague note that quality was not ready."Released only to internal support because reviewer disagreement remained high on refund exceptions" is more useful than a binary pass or fail. These records become training data for the organization. They show which risks repeat, which fixes work, and which promises should stop appearing in sales or product language until the system can support them.
For a company trying to turn evals into a real operating advantage, this ledger is where technical quality meets commercial discipline. It keeps the release story defensible for engineering, product, support, and revenue leadership. It also gives an implementation partner like Devlyn a sharper path into the work: fix the control points that repeatedly block decisions, not the cosmetic parts of the workflow that merely look mature.
Incident Triggers
The weekly cadence is not enough. The system also needs event-based triggers. Run an incident eval when a customer reports a harmful answer, when a source corpus changes materially, when a model or provider changes, when a prompt or tool permission changes, when support sees a new failure cluster, or when a reviewer finds a class of examples the suite does not cover.
An incident eval should be narrow. Reproduce the failure, collect nearby cases, identify the class, repair the smallest layer that explains it, and add the right examples to the suite. Do not turn every incident into a full-suite redesign. The goal is to learn from the event without letting the event consume the operating system.
The incident record should include the affected version, time window, customer or workflow segment, decision IDs if applicable, failed evidence, corrective action, owner, and revalidation result. If the failure created external exposure, the notification path should already be known. Waiting until an incident to invent the communication plan is an avoidable operational failure.
Monthly Review
The monthly review asks whether the eval suite still represents the business. Remove cases that no longer change decisions. Add cases from new traffic. Review label-guide changes. Inspect score movement by segment. Compare incident classes against the current suite. Look for places where cost, latency, or support burden moved while quality scores stayed flat.
This review is also where leadership should see the operating narrative. The best question is not "what is the score?" It is "what did the score let us decide?" If the answer is unclear, the suite is not connected tightly enough to product management. If the answer is clear, the eval program becomes a strategic asset because it lets the company ship with more speed and less theatrical certainty.
For Devlyn-style delivery work, this is the commercial point. Better eval cadence is not a documentation exercise. It reduces rework, makes sales commitments safer, shortens incident diagnosis, and gives technical leaders a defensible way to decide when a system is ready for more customers. The business value comes from turning model behavior into accountable operating decisions.