The Feature That Passed but Failed
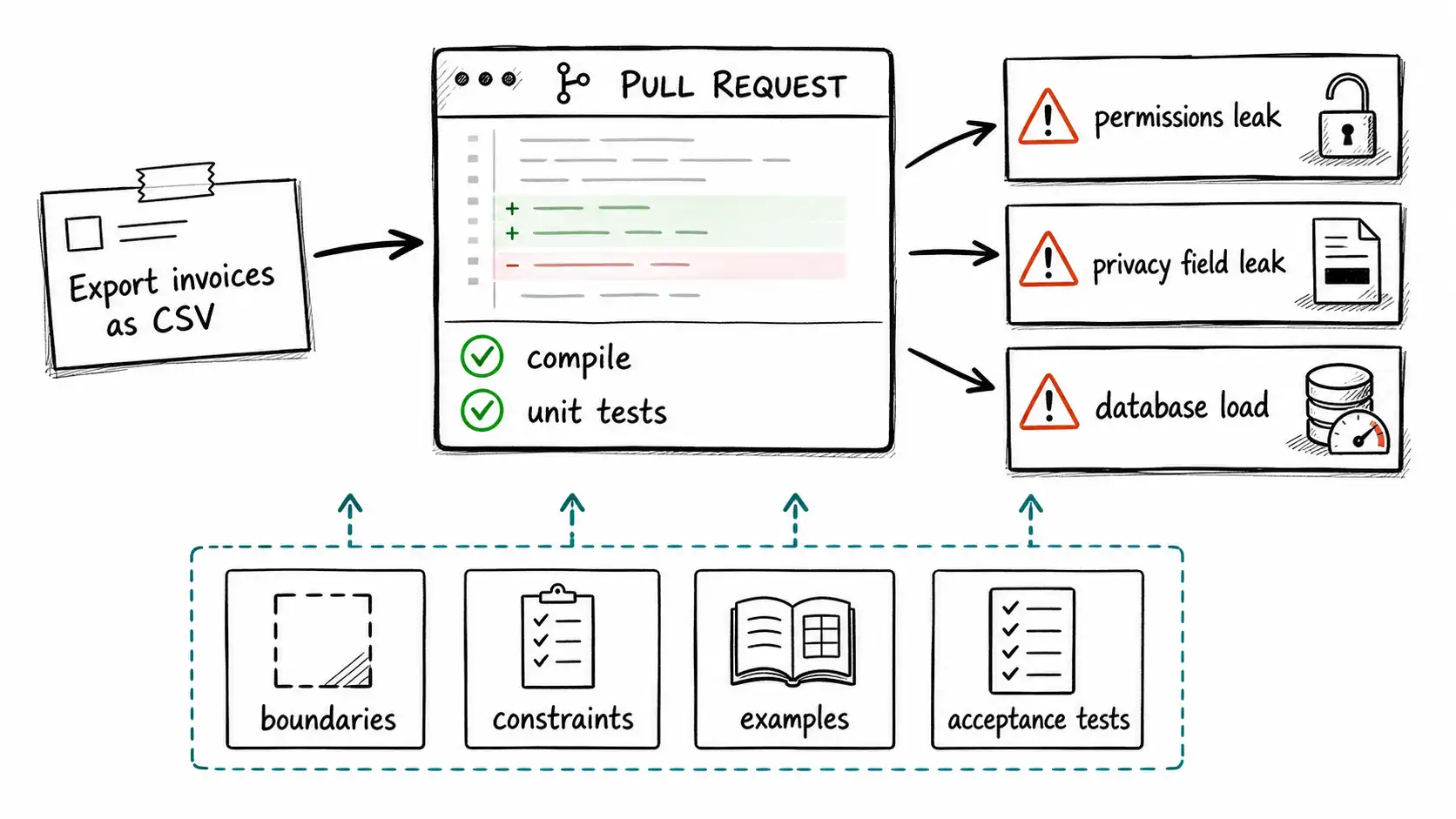
The incident began as a success story. A product manager wrote a short ticket for a billing feature: "Let admins export invoices as CSV from the account page." The team fed the ticket to an AI coding agent inside the repository.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The incident began as a success story. A product manager wrote a short ticket for a billing feature: "Let admins export invoices as CSV from the account page." The team fed the ticket to an AI coding agent inside the repository. The agent inspected the existing UI patterns, created a new button, added an endpoint, wrote a database query, produced a CSV response, and opened a pull request. The code compiled. Unit tests passed. The reviewer skimmed the diff, asked for a variable rename, and merged it. The feature shipped behind a flag two days later.
By Friday afternoon, customer support had three escalations.
The first was from an enterprise customer whose finance analyst could export invoices for subsidiaries the analyst was not allowed to see. The second was from a customer in the EU whose export included fields the privacy team had previously excluded from downloadable reports. The third was from an account with two hundred thousand invoices; the export request locked a database connection long enough to degrade the billing page for everyone in that tenant.
The AI had not hallucinated an endpoint. It had implemented the ticket. The ticket was the bug.
The original sentence did not specify permissions, tenant boundaries, privacy exclusions, export size limits, asynchronous behavior, audit logging, data residency, retention, CSV encoding, locale handling, rate limits, or the customer experience for large exports. A human engineer might have asked those questions because they had been burned before. The model generated plausible implementation from nearby patterns. The review focused on code shape. The test suite checked that an admin could export a small fixture. The system failed because intent was vague and code generation made vagueness look finished.
This is the book's central scene because it captures the new failure mode. In old software teams, vague requirements were expensive because implementation was slow. The slowness created opportunities for clarification. A developer would spend enough time on the work to notice missing details. In AI-assisted development, implementation can arrive before the team has done the thinking that implementation used to force. The generated diff becomes a sedative. It looks like progress, so the ambiguity is hidden until production.
The important shift is not that AI makes bad code. Sometimes it does, sometimes it does not. The important shift is that AI makes code cheap enough that the limiting factor becomes acceptance. The system needs to know what behavior should be accepted before it can safely accept machine-produced implementation.
Fred Brooks' distinction between essence and accident in "No Silver Bullet" still applies. Brooks argued that software's essential difficulty lies in complexity, conformity, changeability, and invisibility, while many tool improvements attack accidental difficulty (https://worrydream.com/refs/Brooks-NoSilverBullet.pdf). AI coding tools reduce accidental effort in producing code. They do not remove the essential difficulty of deciding what the system should do under messy constraints. If anything, they surface that difficulty faster.
The billing export failure also shows why code is not the only source of truth. The actual intended behavior was scattered across people and artifacts: product wanted admin exports; security expected tenant isolation; privacy had a field-exclusion rule; finance wanted CSV; platform had database load constraints; support expected auditability; legal cared about residency; customer success cared about enterprise roles. None of that was in the ticket. The model could not preserve intent that the organization had not expressed.
A specification is the artifact that gathers that intent.
A good spec for the billing export would not have been a fifty-page document. It might have been a two-page behavioral contract with examples, boundaries, constraints, and acceptance tests. It would have said:
- only users with
billing_export:readpermission can export; - the export scope is limited to invoices visible to the user's account role;
- excluded privacy fields must not appear in any export;
- exports above 10,000 rows are asynchronous;
- every export creates an audit event;
- EU tenants use the EU job queue and storage bucket;
- CSV fields are encoded as UTF-8 with escaped delimiters;
- a known large-account fixture must complete without blocking the billing page;
- the feature is accepted only when integration tests cover tenant isolation and privacy exclusion.
This is not bureaucracy. It is the program before the implementation.
The phrase "the spec is the program" does not mean the spec executes in production instead of code. It means the spec becomes the maintained artifact that governs what code should be generated, reviewed, tested, and accepted against. The implementation may be authored by a person, a model, or both. The spec is where intent is preserved.
The industry already has pieces of this idea. OpenAPI defines machine-readable API contracts that allow humans and computers to understand service capabilities without inspecting source code (https://swagger.io/specification/). JSON Schema provides a vocabulary for data validity and interoperability (https://json-schema.org/). Contract testing tools like Pact define expectations between consumers and providers (https://docs.pact.io/). Property-based testing libraries like Hypothesis let teams express invariants across broad input spaces (https://hypothesis.readthedocs.io/). Specification by Example, domain-driven design, formal methods, and test-driven development all recognized that examples and constraints matter.
AI-assisted development does not invent specification. It increases the cost of not doing it.
The first operating rule is therefore: do not allow the model to expand ambiguity into code volume. If the requirement is vague, ask the model to help clarify the spec, not implement the feature. The machine can be useful upstream: list missing edge cases, propose acceptance criteria, identify affected contracts, generate examples, and draft tests. But implementation should wait until the acceptance target exists.
A practical "before implementation" review for AI-assisted work:
| Question | Why it matters |
|---|---|
| What outcome should exist for the user or system? | Prevents implementation from optimizing the wrong artifact. |
| Who is allowed to use it? | Prevents permission and tenant leaks. |
| What inputs and states are in scope? | Prevents unbounded behavior. |
| What is explicitly out of scope? | Prevents the model from adding plausible but unwanted behavior. |
| What examples define correctness? | Gives implementation concrete targets. |
| What counterexamples define failure? | Prevents near-miss behavior. |
| What constraints must never break? | Protects security, privacy, performance, compatibility. |
| What tests or evals lock acceptance? | Prevents review from being taste-based. |
| Who owns the spec after release? | Prevents drift. |
The billing export team eventually fixed the incident. They added permission checks, moved large exports to a background job, excluded fields, added audit logs, and wrote integration tests. But the more important fix was process: the team stopped treating AI-generated diffs as evidence that requirements were ready. They created a lightweight spec gate for any machine-authored feature touching customer data, permissions, billing, or public APIs. The gate did not slow the team after the first month. It made the agent more useful because the agent had a target.
Key Takeaways
- The Feature That Passed but Failed names the operating decision a team has to make before it accepts the work.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Spec Is the Program and the adjacent chapters when you need the wider AI SDLC and Specs frame.
Why AI makes vague tickets worse
A vague ticket has always been a risk. The new problem is scale and polish. A model can turn ambiguity into many files before anyone feels the discomfort that ambiguity should create. The team then reviews implementation instead of intent. Reviewers become biased by the existence of code: once a concrete solution appears, the conversation shifts from "what should happen?" to "is this implementation acceptable?" That shift can be expensive because the implementation has already chosen answers to questions no one asked.
A useful engineering habit is to force ambiguity to fail early. If a ticket cannot produce examples, counterexamples, constraints, and acceptance evidence, it is not ready for autonomous implementation. The model may still be used, but as a spec partner: "find missing requirements," "list abuse cases," "identify likely affected contracts," "draft tests that would prove the outcome." This keeps the machine on the right side of the problem.
The chapter's lesson is simple: if the specification is weak, AI accelerates the wrong thing. The generated code is downstream of intent. When implementation becomes cheap, intent becomes the scarce artifact.
The missing requirement is usually a relationship
The missing requirement in the export story was not a field. It was a relationship: user to tenant, tenant to region, invoice to subsidiary, export to audit, account size to execution path. AI-generated implementation tends to handle nouns well because nouns are visible in code: user, invoice, export, CSV, endpoint. The hard part of software is often the relationships among nouns. That is where permissions, state machines, ownership, and failure modes live.
A useful spec review asks: what relationships does this feature depend on? If the answer includes "customer can belong to parent account," "role can be inherited," "document can be draft or approved," "invoice can be unpaid or disputed," or "region determines storage," those relationships deserve examples and tests. Do not leave them to the model's inference.
This matters because existing code may contain partial truth. A repository might have an AdminUser class that means product admin in one service, tenant admin in another, and internal support admin in a third. A model reading the code can reproduce the ambiguity. A human who knows the domain may know which meaning applies. The spec must choose.
Implementation speed removes accidental discovery
Manual implementation often creates accidental discovery. The engineer writing the export path notices that invoice visibility is complicated because they touch the policy code. They notice export size because the query is slow locally. They notice audit because another endpoint uses an audit helper. These discoveries are unreliable, but they used to be part of the work. AI collapses the time spent in the code and can skip the friction that used to trigger questions.
That means the team must create intentional discovery. Before generation, ask for affected policies, data models, public contracts, performance risks, and operational states. Make the model produce a risk map rather than a diff. Then have humans confirm the map. This turns AI speed into analysis rather than premature implementation.
A finished-looking diff is a social object
The final danger is social. A pull request creates pressure. People assume the author did work, and rejecting it feels like slowing progress. When the author is a machine, the pressure remains but the accountability is fuzzier. Teams need permission to reject generated work quickly. "No spec" should be a legitimate close reason. "Spec missing tenant example" should be a normal review comment. The fastest way to improve AI-assisted delivery is to make early rejection cheap and unpolitical.
The Spec Gate Is Not a Waterfall Gate
A common objection appears whenever teams start treating specifications as maintained artifacts: "This sounds like waterfall." The objection is understandable and mostly wrong. A waterfall process tries to freeze the entire future before implementation begins. A spec-first AI-native process does almost the opposite. It keeps the smallest durable statement of intent in front of the code generator, reviewer, tester, and operator so the system has something stable to judge against while implementation changes quickly.
The distinction matters because machine-authored work can create a strange illusion of progress. Code appears before the team has made a decision. Screens render before the workflow has been agreed. API handlers compile before the failure semantics have been discussed. In a human-authored environment, the slowness of implementation forced some thought to happen before code existed. In an AI-native environment, that friction disappears. The spec gate replaces that missing friction with a more useful constraint: not "finish all planning before writing code," but "name the decision that code is supposed to implement before accepting the code."
A healthy spec gate is risk-tiered. A copy change might need only a one-paragraph intent note and a screenshot. A payment-flow change needs input and output contracts, failure behavior, idempotency rules, audit logging requirements, and rollback criteria. A permissions change needs security review and explicit abuse cases. A workflow that lets an agent act on behalf of a customer needs autonomy boundaries: what the system may do alone, what it may draft but not execute, and what it must never do without human authorization.
This is where the new SDLC differs from both cowboy prompting and traditional documentation. The spec is not a bureaucratic document stored away from the work. It is an operational object that can be read by people, passed into generation tools, converted into tests, used as review criteria, and consulted during incidents. When a team says "the spec is the program," it is not claiming that English prose executes. It is claiming that the maintained source of product intent has moved above the code layer. The code is one generated expression of the spec. The test suite is another. The runbook is another. The telemetry contract is another. The team's job is to keep those expressions aligned.
The practical move is simple. Before accepting a machine-authored change, ask three questions: what intent did this code implement, where is that intent recorded, and what evidence proves the implementation matches it. If no one can answer, the team has not gained velocity. It has borrowed speed from the future and left the repayment to whoever debugs the feature after launch.