Properties, Contracts, and Invariants
Examples catch known cases. Properties catch classes of cases.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. Examples catch known cases. Properties catch classes of cases.
A team can write ten examples for a discount calculator and still miss the strange combination of coupon, tax region, renewal date, currency, and invoice adjustment that breaks production. A model can generate tests that look thorough but only cover the cases it imagined. Property-based testing changes the posture: instead of listing individual inputs, the team states a rule that should hold across many inputs, and the test framework searches for counterexamples.
Hypothesis, the Python property-based testing library, describes this directly: you write tests that should pass for all inputs in a described range, and Hypothesis chooses cases including edge cases you may not have considered (https://hypothesis.readthedocs.io/). In AI-assisted development, property tests are valuable because they express intent at a higher level than generated examples. They are SPEC-Lock's "Lock acceptance" mechanism for broad behavior.
Suppose an AI agent implements a function that applies account credits to invoices. Example tests cover a few invoices. A property test can state: applying credit must never increase the amount due, must never apply more credit than available, and must preserve integer cents.
from hypothesis import given, strategies as st
def apply_credit(invoice_cents: int, credit_cents: int) -> tuple[int, int]:
applied = min(invoice_cents, credit_cents)
return invoice_cents - applied, credit_cents - applied
@given(
invoice_cents=st.integers(min_value=0, max_value=1_000_000),
credit_cents=st.integers(min_value=0, max_value=1_000_000),
)
def test_credit_application_invariants(invoice_cents, credit_cents):
new_invoice, remaining_credit = apply_credit(invoice_cents, credit_cents)
assert new_invoice >= 0
assert remaining_credit >= 0
assert new_invoice <= invoice_cents
assert remaining_credit <= credit_centsThis test is a statement of business intent: applying credit cannot increase debt or create negative balances. A model asked to implement credit logic should be given the invariant before code generation.
Contracts operate at boundaries between systems. A public API, event stream, data pipeline, or service integration can break even when internal tests pass. Consumer-driven contract testing tools like Pact let consumers define expected interactions and providers verify that they still satisfy them (https://docs.pact.io/). This matters when AI agents modify services because generated code can accidentally break behavior that current tests do not cover.
An API provider might return a new field, change an error code, or alter null behavior. The generated code may be cleaner. It may even be more "RESTful." But if a consumer depends on the old contract, the change is a production bug. The spec must preserve interface intent, not only internal elegance.
A contract table:
| Boundary | Contract artifact | What it protects |
|---|---|---|
| HTTP API | OpenAPI + Pact tests | Consumer expectations and error behavior |
| Event stream | Schema registry + compatibility checks | Downstream pipeline stability |
| Database migration | Migration contract + rollback plan | Data integrity and deploy safety |
| UI component | Visual states + accessibility checks | User experience and compliance |
| AI tool call | Tool schema + policy tests | Agent action safety |
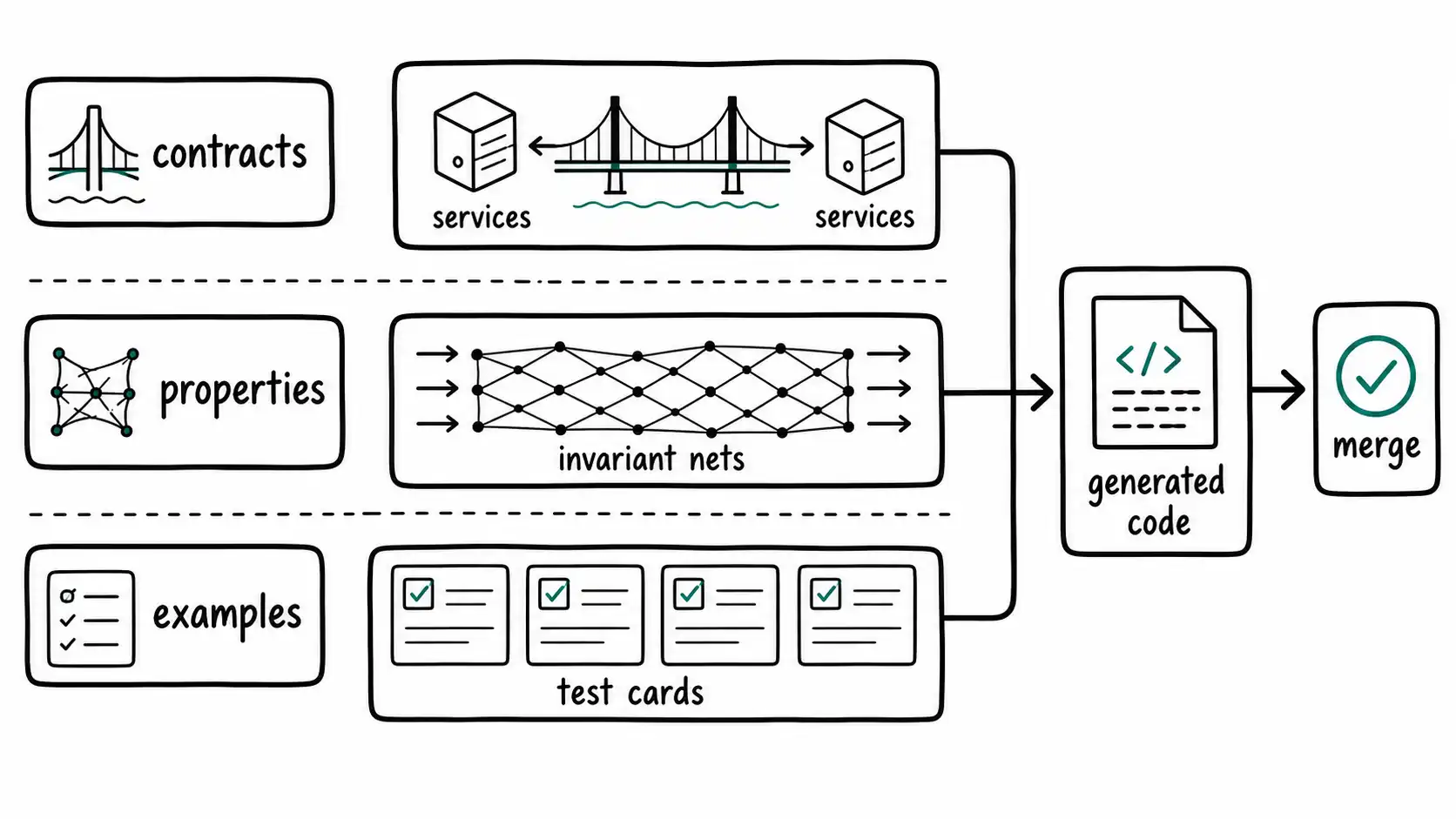
Invariants are the deepest form of specification because they state what must remain true across changes. An invariant might be: a user can never access another tenant's data; invoice totals must equal line items plus tax minus credits; every state-changing action must be auditable; a public API field cannot change type without versioning; generated summaries must cite source documents; a workflow action must be reversible within a defined window.
AI-generated code can satisfy local instructions and violate global invariants. That is why invariants should be visible in the spec and enforced where possible.
A small invariant register:
| Invariant | Enforcement |
|---|---|
| Tenant ID is checked before resource lookup returns content | Integration tests and policy review |
| Money values are integer minor units, never floats | Type checks and schema |
| Public API error codes remain backward compatible | Contract tests |
| Background jobs are idempotent | Property tests with repeated execution |
| AI-generated customer answers cite approved sources | Eval suite |
An idempotency property test:
@given(job_id=st.text(min_size=1), amount=st.integers(min_value=1, max_value=100000))
def test_refund_job_is_idempotent(job_id, amount):
first = run_refund_job(job_id=job_id, amount_cents=amount)
second = run_refund_job(job_id=job_id, amount_cents=amount)
assert first.refund_id == second.refund_id
assert total_refunded_for_job(job_id) == amountThis test is more than quality assurance. It is a statement of business intent: retries must not double-refund customers. A model asked to implement refund processing should be given this invariant before code generation.
Generated tests require caution. AI can generate tests that simply confirm its own implementation. A test that mirrors the code's logic is not independent evidence. The spec should drive tests, not implementation. One practical rule: ask the model to generate tests from the spec before generating implementation, then review tests as intent artifacts. If implementation and tests are generated together from the same vague prompt, they may share the same misunderstanding.
A safer workflow:
- Human writes SPEC-Lock artifact.
- Model proposes examples, properties, contracts, and missing edge cases.
- Human reviews and edits tests before implementation.
- Model implements against tests and contracts.
- CI runs examples, properties, contracts, static checks, and security scans.
- Human reviews diff against spec and failing/added tests.
- Production incidents update examples and properties.
Formal methods belong in this conversation, but lightly. Tools like TLA+ and Alloy can model state machines and find design flaws before implementation. Leslie Lamport's TLA+ materials emphasize specifying and checking system behavior at the design level (https://lamport.azurewebsites.net/tla/tla.html). Most product teams do not need formal specifications for every feature. But AI-assisted development makes state ambiguity more costly. For distributed systems, permission systems, payment flows, and concurrency-heavy workflows, a small model can prevent expensive generated implementation of a broken design.
Key Takeaways
- Examples catch known cases. Properties catch classes of cases.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Spec Is the Program and the adjacent chapters when you need the wider AI SDLC and Specs frame.
Choosing the right lock
Use examples when the team needs shared understanding. Use properties when the state space is broad. Use contracts when a boundary has consumers. Use formal models when state transitions are dangerous. The wrong lock creates either false confidence or unnecessary process. A color change does not need TLA+. A distributed refund workflow probably needs more than three examples.
The chapter's takeaway: examples define known behavior, properties define broad rules, contracts define boundaries, and invariants define what must never break. Together, they turn the spec into an executable control system.
Invariants as architecture memory
Invariants preserve the system's deepest commitments. They usually come from pain: a duplicate payment incident, a cross-tenant leak, a broken public API, a migration that could not be rolled back. If those commitments live only in senior engineers' heads, AI-generated code will eventually violate them. The invariant register is architecture memory in a form that tools can use.
A good invariant is short and absolute:
- a refund job is idempotent;
- a tenant cannot observe another tenant's identifiers;
- public API error codes are backward compatible within a major version;
- invoice money values are never floats;
- every AI-generated customer answer cites an approved source.
These statements are stronger than examples because they apply across many future features.
Contracts as organizational diplomacy
Contract tests also reduce cross-team conflict. Without contracts, a provider team changes an API and downstream teams discover the break in staging or production. With contracts, consumer expectations are visible. AI-generated code should not be allowed to "clean up" a provider response in a way that violates consumers. The contract is the diplomacy layer between teams and services.
This is especially important when AI agents operate in monorepos. A model may see both provider and consumer and update both at once. That can hide a breaking change because tests pass inside the same diff while external consumers break. Public contracts and compatibility checks prevent the model from rewriting history.
Tests as spec artifacts
Tests should not be treated as lower-status engineering chores. In AI-assisted development, tests are the executable portion of the spec. A reviewed test expresses accepted intent. A generated test that is not reviewed expresses model guesswork. The team should review tests with the same seriousness as production code because tests now guide future machine behavior.
The best acceptance package includes examples for readability, properties for breadth, contracts for boundaries, and a short human explanation of why those checks matter.
Contract Failures in Machine-Authored Code
Machine-authored code often fails at boundaries. It can implement the internal logic of a function correctly while subtly violating the contract expected by a caller. It may rename a response field because the new name is clearer. It may return a null where the old API returned an empty list. It may change error order, status codes, retry semantics, pagination behavior, or timestamp precision. None of these changes necessarily look wrong inside the generated diff. They become wrong because other systems depended on the previous contract.
This is why contract tests are disproportionately valuable in an AI-native SDLC. They are not simply tests. They are a defense against invisible social agreements being rewritten by a model that has no memory of the downstream consumer. Pact-style consumer-driven contracts are one approach. OpenAPI schemas with example responses are another. Snapshot tests can help when schemas are stable and payloads are complex. Property-based tests help when the contract is behavioral rather than structural: sorting remains stable, idempotency holds, authorization precedes mutation, totals equal the sum of line items.
A useful rule is to test the seam, not only the function. If the model changes a service that publishes events, test the event shape. If it changes an endpoint, test the response contract. If it changes a database migration, test the before-and-after data state. If it changes an AI workflow, test the trace: which tools were called, in what order, with what permissions, and with what fallback behavior. The seam is where generated convenience becomes production risk.
Invariants are the most compressed form of contract. They state what must always be true, independent of implementation. Account balances cannot go negative except through a named overdraft mechanism. A user cannot access another tenant's document. A support ticket cannot be resolved without either customer confirmation or an approved policy reason. These statements should appear in specs, tests, monitors, and runbooks. Repetition is acceptable here because the invariant is load-bearing.
The deeper lesson is that AI-native code review should become less interested in clever implementation and more interested in boundary preservation. The model can generate ten implementations. The team's scarce judgment is deciding which boundaries those implementations must never cross.
Choosing the Right Proof Surface
Different risks need different proof surfaces. Unit tests are good for local logic. Property tests are good when the space of possible inputs is large. Contract tests are good at service boundaries. Snapshot tests are good for stable structured output. Scenario tests are good for workflows. Evals are good for probabilistic behavior where exact outputs are not fixed. The mistake is treating all evidence as interchangeable.
Consider a support automation feature. A unit test can verify that the escalation classifier parses priority labels. A contract test can verify that the ticketing API receives the same fields as before. A scenario test can verify that a refund request moves through draft, approval, and send states. An eval can measure whether generated replies remain grounded in policy. A monitor can detect whether escalation rates change after release. None replaces the others. Each watches a different failure mode.
The spec should therefore name the proof surface. It should not merely say "add tests." It should say which boundaries require contract tests, which invariants require property tests, which examples become fixtures, and which behaviors require evals. This makes test generation more useful because the model is no longer guessing what kind of evidence the team values.
When code is cheap, proof selection becomes judgment. The team can generate many tests, but useless tests create false confidence. The question is not "did the model add tests?" The question is "do the tests protect the behavior users and systems depend on?" That is a human decision, and it belongs in the spec.