Constraints as Source Code
Features tell the system what to do. Constraints tell it what must remain true while doing it.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. Features tell the system what to do. Constraints tell it what must remain true while doing it.
AI coding tools are naturally drawn toward feature completion. They add the endpoint, create the component, write the query, build the flow. Constraints are less visible because they often live in architecture memory, security policy, privacy commitments, performance budgets, and compatibility promises. When the model writes implementation, constraints must be made explicit or they will be treated as optional.
A constraint can be functional: a user without permission must not see data. It can be nonfunctional: p95 latency must remain under 200 ms. It can be architectural: the service must not call the billing database directly. It can be legal: EU tenant exports must remain in EU storage. It can be operational: every state-changing action must produce an audit event. It can be economic: the workflow must use the small model unless confidence falls below threshold. It can be product: cancellation must not be available to enterprise contracts.
In old teams, many constraints were carried in human review. A senior engineer knew not to call the billing database from the UI service. A security reviewer knew that tenant IDs must be checked before object IDs. A privacy specialist knew which fields could not be exported. That tacit review does not scale when AI increases diff volume. Constraints must move into artifacts.
JSON Schema is one example of constraints as code. It cannot express every business rule, but it can lock structure, types, required fields, formats, and value ranges. The JSON Schema project describes it as a vocabulary for data consistency, validity, and interoperability at scale (https://json-schema.org/). That is exactly what a machine implementer needs: a boundary it cannot politely ignore.
Example:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "RefundRequest",
"type": "object",
"required": ["account_id", "invoice_id", "amount_cents", "reason"],
"properties": {
"account_id": {"type": "string", "minLength": 1},
"invoice_id": {"type": "string", "minLength": 1},
"amount_cents": {
"type": "integer",
"minimum": 1,
"maximum": 50000
},
"reason": {
"type": "string",
"enum": ["duplicate_charge", "service_failure", "billing_error"]
}
},
"additionalProperties": false
}This schema does not decide whether a refund should be approved. But it prevents malformed requests and caps a self-serve path. It moves part of the spec into a machine-enforceable boundary.
OpenAPI moves API constraints into a contract. Pact moves consumer expectations into tests. Database constraints move invariants into storage. Feature flags move rollout constraints into release control. Static analysis moves security constraints into the build. Policy engines such as Open Policy Agent can move access decisions into inspectable policy. The common principle is that constraints should not depend only on reviewer memory.
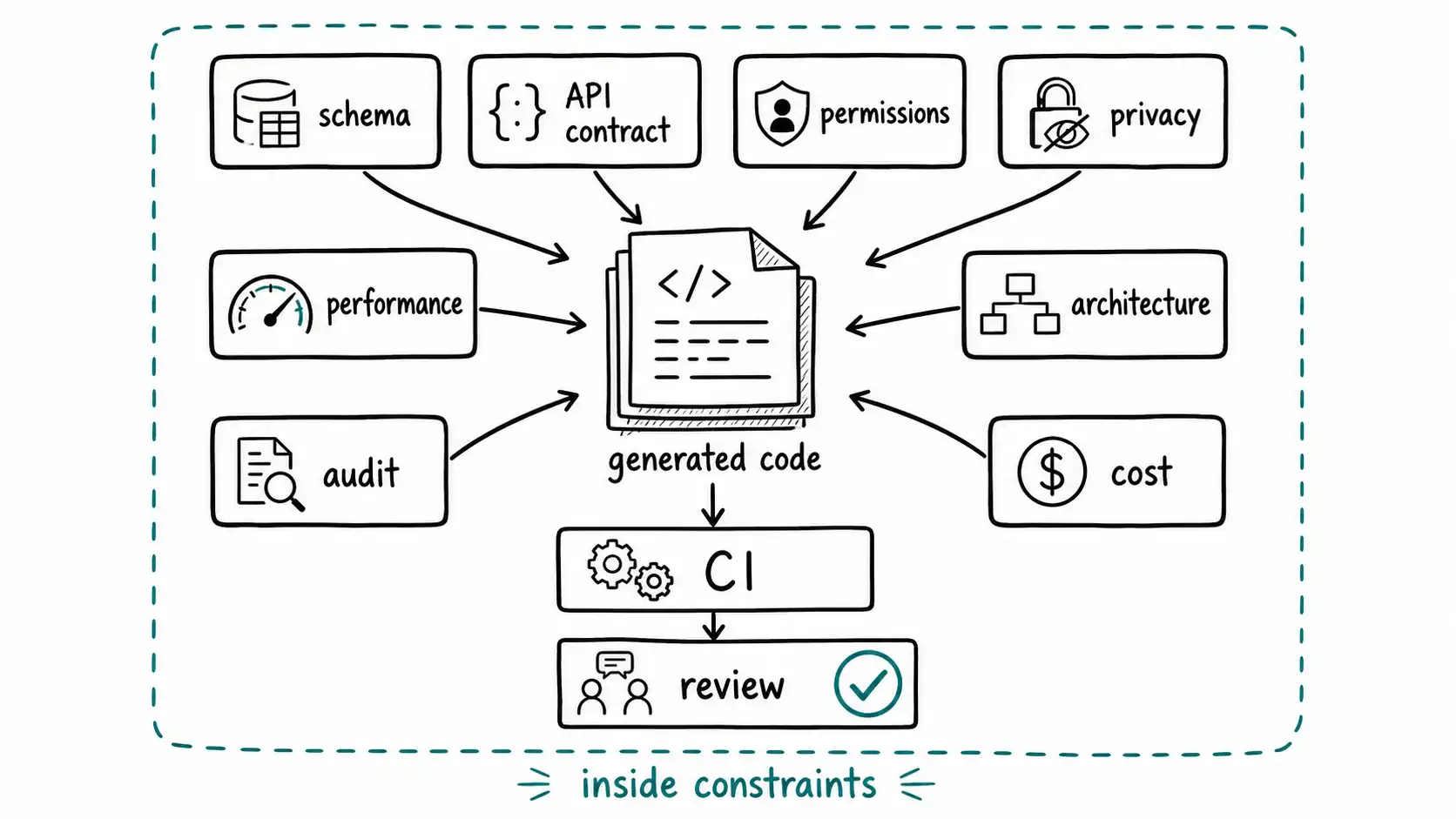
Constraints also help the model. A coding agent given architecture rules can avoid bad implementation paths. A prompt that says "use the existing repository pattern and do not query the database from controllers" is better than a vague request. But the stronger form is a maintained architecture spec that the agent and reviewer both reference.
An architecture constraint snippet:
> **Key Takeaways**
> - Features tell the system what to do. Constraints tell it what must remain true while doing it.
> - The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
> - Read this with The Spec Is the Program and the adjacent chapters when you need the wider AI SDLC and Specs frame.
## Data access constraint
Services in `apps/web` must not access billing tables directly.
All billing reads go through `BillingReadService`.
All state-changing billing operations go through command handlers in `apps/billing`.
Generated code violating this boundary should be rejected even if tests pass.This is plain English, but it is still useful. It can become a lint rule later. Not every constraint starts executable. The important step is making it explicit and reviewable.
Security constraints deserve special attention. AI-generated code may reproduce insecure patterns from the repository or from training data. OWASP's Top 10 and OWASP's Top 10 for LLM Applications are useful references for common web and LLM system risks (https://owasp.org/www-project-top-ten/ and https://owasp.org/www-project-top-10-for-large-language-model-applications/). The lesson for specs is practical: security requirements must appear before code generation, not after. "Add authentication" is insufficient. The spec should state roles, permissions, denial behavior, audit logging, abuse cases, and data exposure limits.
A security constraint table:
| Constraint | Spec expression | Acceptance evidence |
|---|---|---|
| Tenant isolation | Query must scope by tenant before object ID | Integration test with cross-tenant object ID |
| Permission denial | 403 must not reveal resource existence | Contract test for unauthorized known/unknown IDs |
| Auditability | Every denied export logs actor, tenant, reason | Audit assertion in test |
| Secret handling | No secrets in generated logs | Static scan and log test |
| Prompt injection defense | Retrieved content cannot override system policy | Eval case with malicious document |
Constraints also include performance. AI-generated implementations may be correct on small fixtures and disastrous on production data. The billing export example failed partly because the spec did not constrain large-account behavior. A performance constraint should be concrete: p95 latency target, max rows for synchronous path, memory budget, job timeout, backpressure behavior. "Should be fast" is not a constraint. "Exports above 10,000 rows must be asynchronous and must not hold a database connection longer than 500 ms" is.
The chapter's practical artifact is the constraint register:
| Constraint ID | Type | Statement | Enforcement | Owner |
|---|---|---|---|---|
| SEC-001 | Security | All billing exports require billing_export:read | Integration test + policy check | Security |
| PRIV-003 | Privacy | EU tenant export storage remains in EU region | Deployment config + audit | Privacy |
| PERF-010 | Performance | Large exports use async job path | Load test | Platform |
| ARCH-007 | Architecture | Web app cannot query billing tables directly | Static rule + review | Architecture |
| UX-004 | Product | Enterprise contracts cannot self-cancel | Feature test | Product |
A mature spec links feature behavior to this register. A machine-authored diff that violates a constraint fails regardless of how elegant the implementation looks.
Constraint hierarchy
Not all constraints are equal. Some are hard blocks; others are budgets; others are preferences. A hard security boundary should fail CI. A performance budget may fail a release gate. A design preference may trigger review. Labeling constraint severity prevents both chaos and over-process.
A model can help maintain the register by scanning a spec and asking, "Which constraints are not enforceable yet?" The answer becomes engineering work. Over time, the most important constraints should migrate from prose to tests, schemas, policies, static checks, and runtime monitors.
The final point: constraints are how organizations preserve decisions. Every architecture rule, privacy limit, audit requirement, and performance budget is a decision made in the past. If those decisions are not encoded, AI-generated code will slowly erode them. The model does not know which scars created your architecture. The spec must know.
The chapter's takeaway: features are not correct unless constraints survive. When machines write code, constraints must become part of the source.
From prose to enforcement
Constraints often begin in prose because writing a test or policy takes effort. That is fine. The maturity path matters:
- Named prose - the constraint is written and owned.
- Reviewed prose - relevant stakeholders approve it.
- Checklist enforcement - reviewers check it manually.
- Automated enforcement - tests, schemas, policies, or static rules enforce it.
- Runtime monitoring - production detects violations or drift.
Do not pretend a prose constraint is as strong as an automated one. But do not wait for automation before naming it. The named constraint is the seed. The most critical constraints should migrate toward automation over time.
Cost constraints
AI-assisted teams often forget cost constraints. A generated implementation may call a large model inside a tight loop, add expensive retrieval to a high-volume path, or create a background job that runs too often. If cost matters, say so in the spec.
Example:
Cost constraint:
- The synchronous path must not call the large reasoning model.
- The nightly enrichment job may process at most 50,000 records per run.
- The feature must expose per-tenant usage metrics before GA.Cost constraints are product constraints because cloud bills become gross margin. They are also reliability constraints because expensive paths often become latency bottlenecks.
Constraint conflict
Constraints can conflict. Privacy may require less logging; audit may require more logging. Performance may prefer caching; authorization may require fresh permission checks. Compatibility may preserve a bad API shape; architecture may want a cleaner boundary. A spec should surface conflicts instead of letting generated code choose implicitly.
When constraints conflict, write the decision down. That is the difference between engineering judgment and accidental behavior.
Constraints in Continuous Integration
Once constraints are written down, the next question is whether the pipeline can enforce them. Not every constraint can be mechanically checked, but more can be checked than teams assume. "All admin endpoints require an authorization middleware" can be linted. "All outbound emails must include an unsubscribe footer" can be tested. "All migration scripts must be reversible or explicitly marked irreversible" can be checked in review automation. "All generated answers must include citations" can be enforced at the application layer. "No personally identifiable information in logs" can be partially detected through scanners and log sampling.
The right implementation is a severity ladder. Blocking constraints stop the build. Warning constraints require explicit acknowledgment. Advisory constraints appear in review comments. Not every rule deserves the same force. A payment idempotency violation should block. A missing explanatory comment might warn. A naming convention might advise. If every constraint blocks, the team will route around the system. If no constraint blocks, the system is decoration.
Here is the important cultural shift: the model should see the constraints before it writes code. A CI failure after generation is useful, but prevention is better. Put the relevant constraints in the generation context. If a feature touches billing, include billing invariants. If a change touches privacy, include privacy constraints. If a change touches an agent tool, include tool-use boundaries. The model is much more likely to produce acceptable work when the acceptance criteria are present during generation rather than discovered after failure.
Constraints also need a removal process. A stale constraint is worse than no constraint because it teaches the team that the constraint catalog is not trustworthy. Each constraint should have an owner, a rationale, examples, and a review date if it is tied to a temporary policy. When a business rule changes, the corresponding constraint should change in the same pull request as the code and tests. Otherwise, the repository begins to contain multiple versions of reality.
In a mature system, constraints become a form of organizational memory. They carry lessons from incidents, legal reviews, customer escalations, performance regressions, and security audits. The model may write the code, but the constraints tell it which parts of the company's past must not be forgotten.
The Constraint Catalog
A constraint catalog is the companion artifact to the example library. Examples show what should happen in named cases; constraints state the rules that generalize beyond those cases. The catalog should be organized by domain, not by implementation file. Billing constraints live together. Privacy constraints live together. Agent-tool constraints live together. This lets generation tools and reviewers retrieve the relevant rules without requiring deep repository knowledge.
A good entry has five fields: statement, rationale, enforcement, examples, and owner. The statement is the rule. The rationale explains why the rule exists. The enforcement field says whether the rule is checked by tests, linters, review, runtime monitors, or policy. The examples field links to cases that demonstrate the rule. The owner field names the person or team allowed to change it. Without ownership, constraints become folklore written in Markdown.
The catalog should be opinionated about conflicts. Real systems contain rules that pull against each other: minimize friction but prevent fraud; personalize responses but protect privacy; automate resolution but avoid unsafe commitments. A constraint catalog should not pretend these tensions do not exist. It should name priority order and escalation paths. For example, privacy constraints override personalization constraints. Legal holds override retention cleanup. Customer safety overrides speed.
For AI-native development, the catalog is a prompt input, a review checklist, a CI rule source, and an incident reference. That multi-use property is what makes it worth maintaining. A document read only by humans will drift. An artifact used by tools every day has a chance to stay alive.