Accepting Machine-Authored Diffs
Code review changes when the author is a machine.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. Code review changes when the author is a machine.
A human-authored diff arrives with social context. The reviewer knows the engineer's habits, level, intent, and likely blind spots. A machine-authored diff arrives with fluency but no accountability. It can be large, internally consistent, and subtly wrong. The reviewer's job is not to judge whether the model "did well." The reviewer's job is to decide whether this change should enter the maintained system.
The acceptance standard must therefore shift from author trust to artifact evidence.
GitHub Copilot productivity research showed that developers can complete some coding tasks substantially faster with AI assistance, such as the controlled experiment reporting faster completion on a specific JavaScript task (https://arxiv.org/abs/2302.06590). But faster completion is not the same as lower total delivery cost. SWE-bench and similar benchmarks test whether systems can resolve real software issues in real repositories (https://www.swebench.com/), and their existence underscores the point: software engineering is not only code generation; it is making correct changes in existing systems. The review process must protect that difference.
A generated diff acceptance checklist should not be a generic code review checklist. It should ask questions specific to machine authorship:
| Review area | Machine-authored risk | Acceptance question |
|---|---|---|
| Intent trace | Code may implement inferred intent | Which spec line or example does this satisfy? |
| Scope creep | Model may add plausible adjacent features | What changed outside the spec? |
| Consistency | Model may copy old patterns including bad ones | Did it follow current architecture constraints? |
| Tests | Model may generate self-confirming tests | Do tests fail against plausible wrong implementations? |
| Security | Model may omit abuse cases | Are permission, injection, secret, and tenant risks tested? |
| Dependencies | Model may add unnecessary packages | Are new dependencies justified and safe? |
| Migration | Model may ignore rollout/rollback | Is deploy order and rollback safe? |
| Maintainability | Code may be verbose or overfit | Will humans understand and own it later? |
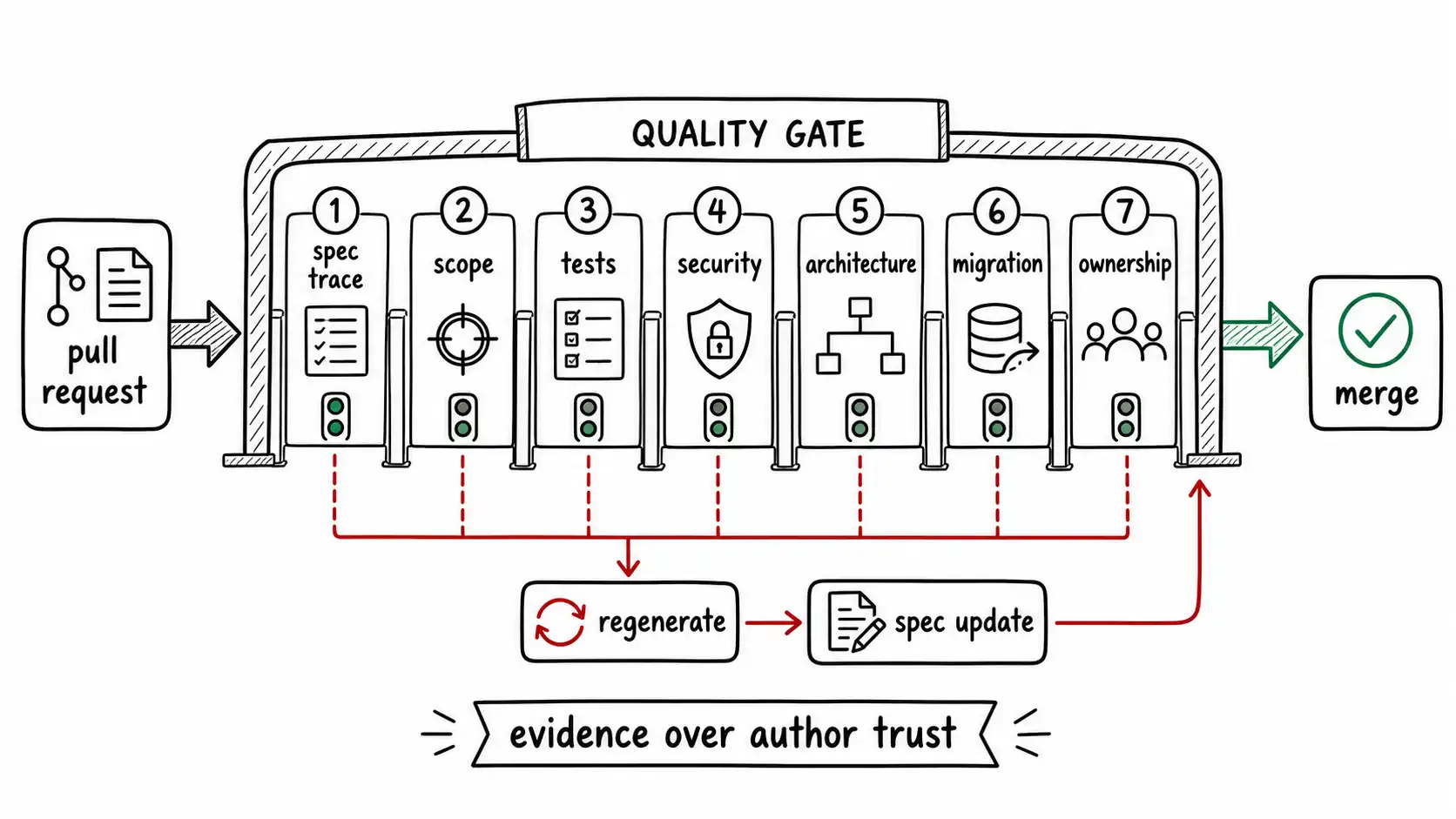
The first review question should be traceability. Every significant generated change should point back to outcome, example, constraint, or acceptance criterion. If the reviewer cannot trace a block of code to intent, the diff is suspect. It may be accidental helpfulness. It may be unnecessary complexity. It may be a hallucinated requirement.
Trace comments can be lightweight:
Spec trace:
- Outcome: self-serve cancellation for monthly plans.
- Example: unpaid invoice returns blocked state.
- Constraint: enterprise contracts out of scope.
- Acceptance: integration test covers payment-provider partial failure.A pull request template for AI-authored changes:
> **Key Takeaways**
> - Code review changes when the author is a machine.
> - The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
> - Read this with The Spec Is the Program and the adjacent chapters when you need the wider AI SDLC and Specs frame.
## Spec link
<!-- Link to SPEC-Lock artifact -->
## Generation scope
What was the model asked to implement?
## Human edits
What did a human change after generation?
## Acceptance evidence
- [ ] Examples implemented as tests
- [ ] Constraints checked
- [ ] Contract/API diff reviewed
- [ ] Security-sensitive paths reviewed
- [ ] Rollback plan included
## Known limitations
What does this change intentionally not solve?
## Reviewer focus
Which areas require human judgment?This template is not bureaucracy. It tells reviewers where judgment is needed.
Generated diffs also require size discipline. AI tools can produce large changes cheaply, but review cost rises with diff size. A large generated diff may be cheaper to author and more expensive to accept. Teams should prefer small, spec-bounded changes. If the model needs to refactor broadly, ask it to produce a plan and sequence, not one giant diff.
A useful rule: machine-authored diffs should be smaller than human-authored diffs for consequential systems, not larger. The model's speed should be spent on iteration, not review overload.
Security review deserves special treatment. NIST's Secure Software Development Framework provides practices for secure software development across the lifecycle (https://csrc.nist.gov/pubs/sp/800/218/final), and SLSA focuses on supply-chain integrity (https://slsa.dev/). AI-authored code does not remove those concerns. It can add new ones: generated dependencies, copied insecure patterns, hidden data exposure, and prompt/tool context leakage. The spec should state security constraints, and the acceptance gate should verify them.
A generated dependency policy:
| Dependency event | Required review |
|---|---|
| New runtime dependency | Human approval with license/security check |
| New dev dependency | Automated scan plus reviewer approval |
| Dependency major upgrade | Changelog review and compatibility test |
| Transitive dependency alert | Security owner triage |
| Model-suggested package with low reputation | Reject unless explicitly justified |
The reviewer should also inspect deletion. AI agents may remove code that looks unused but is invoked dynamically, used by customers through an undocumented path, or required for compatibility. A spec should define deprecation and compatibility. A generated cleanup diff without a compatibility plan is dangerous.
Tests are necessary but not sufficient. A generated change can pass tests because the tests were weak. DORA's research emphasizes that AI adoption works through the broader organizational system (https://dora.dev/dora-report-2025/). In code review, that means generated code benefits mature teams with strong tests, architecture, ownership, and CI. Weak teams may simply generate weak changes faster.
Acceptance also includes ownership. A machine cannot be on call. The team must know who owns the code after merge. If no human understands the generated implementation, the diff should not ship. This is especially important for infrastructure, payments, security, and data migration. "The model wrote it" is not an incident response plan.
A machine-authored diff should be rejected when:
- there is no spec;
- it changes behavior outside scope;
- tests are generated from implementation rather than intent;
- security constraints are absent;
- it adds dependencies without justification;
- it modifies public contracts without compatibility review;
- it introduces code no human owner understands;
- it cannot be rolled back;
- reviewer confidence depends on model fluency rather than evidence.
Review ergonomics
The team should also redesign the review interface. A reviewer should see the spec, generated prompt, changed files, test evidence, contract diffs, security scan results, and deployment risk in one place. If reviewing a generated diff requires reconstructing context from chat logs and local memory, review cost will explode. The correct response is not to tell reviewers to work harder. It is to make acceptance evidence available at the point of decision.
The chapter's central claim is that code review becomes acceptance review. The reviewer is no longer only a craft peer; they are the control point between generated implementation and maintained system. That control point must be supported by specs, tests, constraints, and traceability, or it will collapse under diff volume.
The reviewer's new job
In a traditional review, the reviewer may teach the author. In a machine-authored review, teaching the author is less direct. The reviewer teaches the system by updating specs, tests, prompts, constraints, and examples. A comment like "wrong approach" is weaker than adding the missing architecture constraint. A comment like "handle unpaid invoices" is weaker than adding the unpaid-invoice example and test.
This changes review etiquette. If a generated diff fails because the spec was incomplete, the right action may be to close the diff and update the spec, not to patch the code manually. Manual patching can hide the learning. The team should ask: did this failure reveal a missing instruction, missing example, missing test, missing constraint, or model limitation? Then improve the artifact that will prevent recurrence.
Diff provenance
Teams also need provenance. Was this file generated entirely by an agent? Edited by a human? Regenerated after review? Did the model have access to the active spec? Which prompt or task produced the diff? Provenance does not need to be heavyweight, but it matters during incidents. When a production bug is traced to a machine-authored change, the team should be able to reconstruct the intent and acceptance evidence.
A minimal provenance block in the pull request can answer:
- tool/model used;
- spec version used;
- human edits after generation;
- tests generated before or after implementation;
- files intentionally excluded;
- known limitations.
Provenance is not blame. It is debugging information.
Merge discipline
Finally, machine-authored diffs should not get a discount because they were fast to produce. If anything, high-autonomy diffs need stronger acceptance evidence. The machine does not feel ownership, does not remember production scars, and does not carry pager responsibility. Humans and systems must supply that accountability before merge.
Scaling the Review Queue
As machine-authored code volume rises, review becomes the bottleneck. Teams discover this after a few weeks of success. A developer who previously opened three pull requests a week can now open ten. The total number of lines changed grows. The number of small behavior changes grows. Reviewers feel productive at first because the backlog is full of apparently clean diffs. Then fatigue sets in. Important comments are missed. Review quality falls. The team has moved the bottleneck from implementation to acceptance.
The solution is not to demand heroic reviewers. It is to redesign review around risk. Low-risk generated changes should be made smaller and easier to accept. High-risk changes should be forced through stronger evidence. A dependency bump with generated adaptation code might need automated tests plus one reviewer. A payment-flow change needs spec review, contract tests, security signoff, and staged rollout. A broad refactor touching core authorization should be treated as high-risk even if the model labels it "cleanup."
Review packets help. A review packet is the evidence bundle attached to a machine-authored diff: the spec, the changed files, the tests added or updated, the contracts affected, the constraints triggered, the eval results, the rollout plan, and the rollback path. Reviewers should not have to reconstruct this context from scattered comments and chat logs. The model can help assemble the packet, but a human owner must vouch for it.
Diff size becomes an architectural concern. AI tools make it easy to submit broad changes because generating more code is cheap. Broad changes are expensive to review. Mature teams therefore instruct generation tools to work in narrow slices: one behavior change, one contract boundary, one migration step. This may feel slower than accepting a large generated diff, but it improves total throughput because the review queue stays healthy.
The final practice is post-merge accountability. The owner of a machine-authored diff owns the outcome. "The model wrote it" is never an incident explanation. The human accepted it, and acceptance is the act that matters. When teams internalize that, review becomes what it should be in the AI-native SDLC: not proofreading machine output, but accepting responsibility for a change the machine made cheap to produce.
The Acceptance Record
Every significant machine-authored change should leave an acceptance record. This does not need to be a heavyweight form. It can be a short section in the pull request: generated by which tool, from which spec, with which constraints, reviewed by whom, accepted on what evidence, and rolled out under what plan. The record matters because incidents happen later, after chat history has disappeared and the person who accepted the change may have moved on.
The acceptance record changes the psychology of review. Reviewers stop asking "does this look okay?" and start asking "am I willing to be named as accepting this behavior under this evidence?" That is the correct pressure. It does not make reviewers fearful; it makes review explicit. A low-risk change needs a lightweight record. A high-risk change needs a richer one.
This also prevents the tool from becoming an accountability sink. Organizations are often tempted to describe incidents as AI failures because that language feels less personal. But production systems do not care whether code was typed by a person or generated by a model. The organization accepted it. The acceptance record makes that fact visible.
A useful policy: if a change would require a postmortem if it failed, it requires an acceptance record before it ships. That single rule catches the important cases without burying every small change in paperwork.