Living Specs and Spec Drift
A spec that is correct on launch day can be wrong six months later.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. A spec that is correct on launch day can be wrong six months later.
Customers use the feature differently. Regulations change. The product expands to new segments. Support discovers edge cases. Data volume grows. Dependencies shift. A generated implementation is patched. A reviewer approves an exception. An incident reveals a missing constraint. The code changes, and unless the spec changes with it, the maintained intent drifts away from production behavior.
Spec drift is the distance between what the artifact says the system should do and what the system actually does.
Spec drift is not ordinary documentation staleness. It is more dangerous in AI-assisted development because future machine work may use stale specs as authoritative context. A coding agent asked to modify a feature may read the old spec, implement against outdated intent, and reintroduce bugs the team already learned from. A stale spec becomes a regression generator.
The solution is to treat specs as living artifacts with ownership, versioning, and feedback loops.
A spec should have:
| Field | Purpose |
|---|---|
| Owner | Who decides when intent changes |
| Status | Draft, active, deprecated, superseded |
| Linked code areas | Where implementation lives |
| Linked tests/evals | How acceptance is enforced |
| Production signals | What metrics indicate behavior |
| Decision log | Why major choices were made |
| Drift log | What production taught after release |
| Review cadence | When the spec is revalidated |
An Architecture Decision Record (ADR) is useful for preserving why a decision was made. A lightweight ADR:
# ADR-014: Large invoice exports use asynchronous jobs
> **Key Takeaways**
> - A spec that is correct on launch day can be wrong six months later.
> - The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
> - Read this with The Spec Is the Program and the adjacent chapters when you need the wider AI SDLC and Specs frame.
## Status
Accepted
## Context
Synchronous invoice export caused database contention for large tenants.
Generated implementation originally used a direct request/response path.
## Decision
Exports above 10,000 rows will create an async job and notify the user when complete.
The job runs in the tenant's residency region and stores output for 7 days.
## Consequences
- UI must show pending/export-ready states.
- Support can see job status.
- Tests must cover large export path.
- Small exports remain synchronous for usability.This ADR keeps intent alive. A future AI agent asked to "simplify exports" should not remove the async path because it looks unnecessary in small tests.
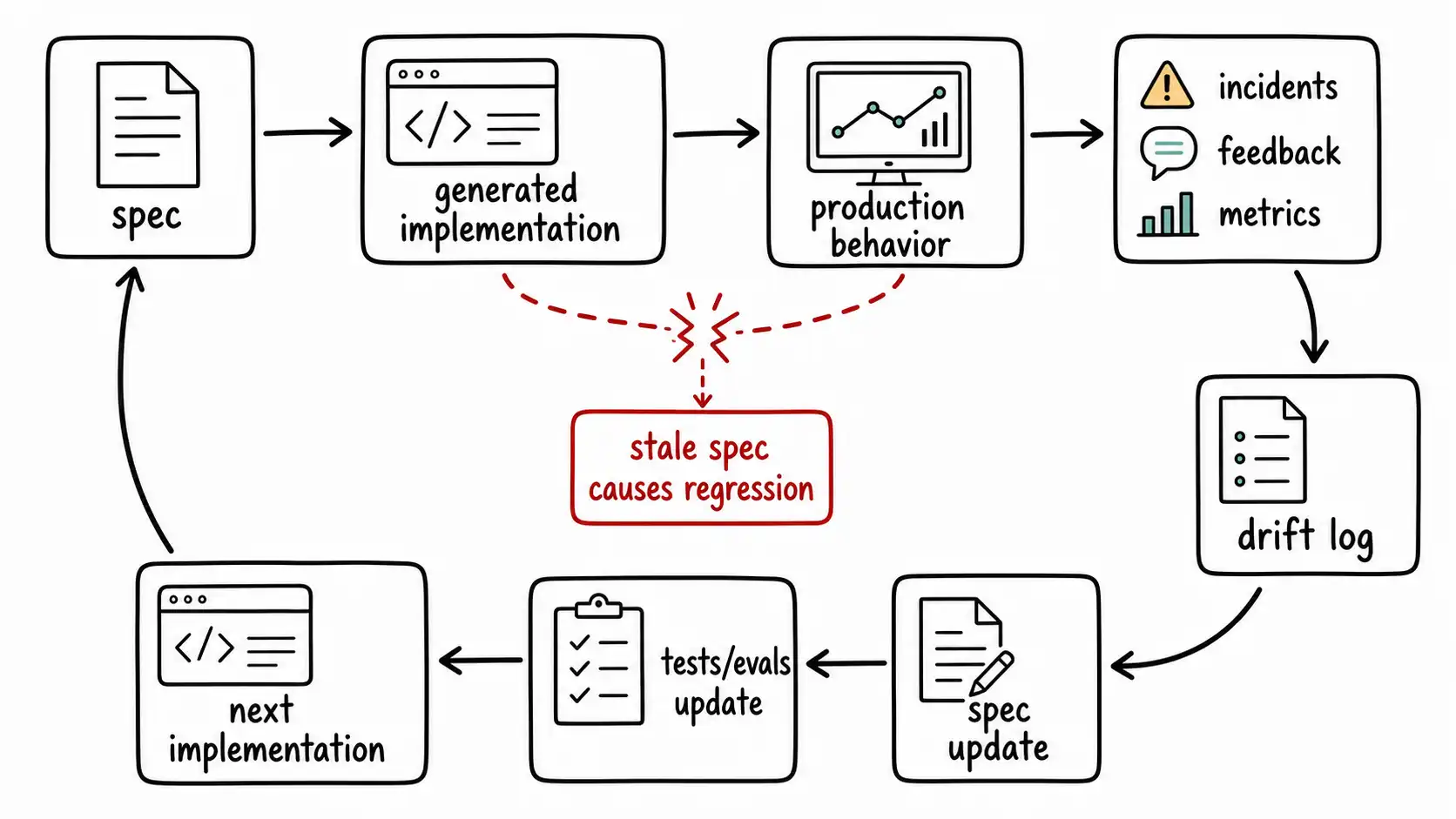
Spec drift should be detected. Some signals are obvious: production incident, customer escalation, support workaround, repeated reviewer comment, failing eval, mismatched docs, or API consumer complaint. Others are subtle: tests added without spec updates, code comments contradicting docs, feature flags becoming permanent, support macros diverging from product behavior, or generated code repeatedly changing the same area because intent is unclear.
A spec drift log:
| Date | Signal | Drift discovered | Spec update | Test/eval update |
|---|---|---|---|---|
| Mar 4 | Support escalation | Enterprise contracts cannot self-cancel | Added out-of-scope boundary | Added enterprise cancellation test |
| Apr 12 | Incident | Large exports blocking DB | Added async export constraint | Load test and ADR |
| May 8 | Legal review | EU storage retention changed | Updated retention from 30 to 7 days | Residency/retention test |
| Jun 2 | Reviewer disagreement | Role name ambiguous | Clarified billing owner vs admin | Permission fixture |
The drift log turns production learning into maintained intent.
Living specs also require repository design. Specs should live near the code or in a discoverable spec repository with links from code, tests, docs, and tickets. They should be version-controlled. Pull requests that change behavior should update specs. CI can enforce some of this by requiring a spec link for high-risk directories or public API changes. A spec without a path into developer workflow becomes a wiki graveyard.
A repository layout:
/specs
/billing
subscription-cancellation.md
invoice-export.md
adr-014-async-large-exports.md
/api
credit-balance.openapi.yaml
/ai
support-answer-evals.yaml
/apps
/billing
/tests
/contracts
/propertiesThe exact layout matters less than the linking discipline. A developer or agent should be able to answer: where is intent defined, where is it enforced, and who owns it?
AI can help maintain specs, but it should not silently rewrite intent. A useful agent task is: "Compare this diff to the active spec and propose spec updates for changed behavior." Another is: "Search recent incidents and reviewer comments for cases missing from the spec." The human owner then approves the change. This uses the model as a drift detector rather than an autonomous source of truth.
Spec review cadence should follow risk. High-consequence workflows need scheduled review. Public APIs need compatibility review. Internal tools may update on change. AI-heavy workflows need review when model, prompt, tool, or retrieval behavior changes. A spec tied to an AI support assistant may need updates whenever policy documents change, because the assistant's correct behavior depends on policy freshness.
The final challenge is organizational. Specs can become performative if leaders reward shipping without maintaining intent. The spec must be part of done. A feature is not done when code ships. It is done when behavior, tests, docs, monitoring, and spec agree. In AI-assisted development, this agreement is the only thing that keeps machine speed from turning into system entropy.
The book closes with a practical map:
| AI-assisted development risk | Spec practice |
|---|---|
| Vague prompt creates wrong feature | SPEC-Lock before implementation |
| Model overbuilds scope | Boundaries and non-goals |
| Happy path passes | Examples and counterexamples |
| Hidden system rules break | Constraint register |
| Generated tests mirror code | Tests from spec before implementation |
| Public contract changes | OpenAPI/Pact contract checks |
| Future agent reintroduces old bug | Living spec and drift log |
| Review overload | Traceability and acceptance checklist |
The spec repository as institutional memory
A living spec repository becomes one of the most valuable assets in an AI-native engineering organization. It tells future humans and future models why the system behaves as it does. It prevents old incidents from being rediscovered. It lets teams onboard faster because intent is not trapped inside senior engineers' memory. It also makes AI coding tools better because they retrieve better context.
The repository should not contain only polished final specs. It should contain decisions, rejected alternatives, incident learnings, and deprecation plans. Machines are good at reading large context, but they are not good at knowing which context is authoritative unless the repository marks status and ownership. A stale draft should not look equivalent to an active contract. A superseded spec should point to the replacement.
The conclusion is not that every team should write more documents. It is that every team should preserve intent in artifacts strong enough to guide machines and humans. The spec is the program because the spec is where the system's meaning lives before code and after code.
When the machine writes the implementation, the human job does not disappear. It moves to intent, examples, constraints, acceptance, and stewardship. The teams that master that move will ship faster because they will stop letting ambiguity generate code.
Spec versioning and compatibility
Specs need semantic care when public behavior changes. A minor internal clarification is different from a breaking API change. A spec repository should mark compatibility impact: no behavior change, behavior clarification, backward-compatible extension, breaking change, deprecation, or removal. This helps agents and humans understand whether implementation can be local or requires migration.
For public APIs, the spec should define deprecation windows and consumer communication. For internal workflows, it should define rollout and rollback. For AI assistants, it should define model/prompt/eval version because a behavior change can come from non-code artifacts. A living spec treats all behavior-shaping artifacts as part of the system.
Drift review ceremony
A quarterly spec review can be lightweight. Pick high-risk specs. Compare active spec to incidents, support escalations, recent code changes, eval failures, and customer-facing docs. Ask:
- did production behavior diverge from the spec?
- did the spec omit a case now known to matter?
- did tests change without spec change?
- did customer documentation promise behavior not in the spec?
- did an AI prompt or policy change alter behavior?
The review should produce concrete updates, not discussion notes. Add examples, update constraints, deprecate stale behavior, link new ADRs, or mark the spec superseded.
The final operating principle
The spec is not upstream-only. It is the thread connecting design, implementation, review, release, incident response, and future generation. When that thread breaks, AI-assisted development becomes fast forgetting. When the thread holds, the organization accumulates intent. That accumulation is how speed becomes durable.
Spec Drift in AI Context Retrieval
Spec drift becomes more dangerous when AI tools retrieve context automatically. A human developer might remember that an old design document is obsolete. A code-generation system may retrieve it because the text is semantically similar to the current task. If the repository contains three versions of a pricing policy and only one is authoritative, the model may blend them. The generated code can then implement a policy that no human actually approved.
This is the same problem that retrieval systems face elsewhere: similarity is not authority. A living spec system therefore needs metadata. Each spec should have status, owner, effective date, superseded-by link, domain, product surface, and trust level. Generation tools should prefer current approved specs and exclude drafts unless explicitly requested. Old specs are not deleted, because history matters, but they are marked as historical. The toolchain should know the difference.
Deprecation is part of specification maintenance. When a behavior is replaced, the old spec should not simply remain beside the new one. It should point to the successor and explain the migration. Tests and examples tied to the old behavior should either be retired or moved into compatibility coverage. Otherwise the example library can become self-contradictory: one example says refunds require approval, another says they do not, and the model averages the inconsistency into nonsense.
A useful quarterly practice is a spec inventory. List the specs most frequently retrieved by AI tools. Check their owners. Check their statuses. Check whether the code still matches them. Check whether incidents or support escalations reveal behavior not represented in the specs. This sounds mundane, but it is the maintenance discipline that keeps intent from rotting while implementation accelerates.
The final point is philosophical and practical: in an AI-native SDLC, the repository is no longer only code plus tests. It is a context supply chain. The model uses that context to produce work. If the context is stale, contradictory, or unauthoritative, the generated work will inherit those defects. Living specs are how a team controls that supply chain.
Spec Retirement
A living spec system needs a retirement process. Not every old behavior should remain in active context forever. Some specs describe deprecated APIs. Some describe temporary migration behavior. Some describe features that were removed. If these remain retrievable as if they were current, the generation system will eventually use them in the wrong place.
Retirement should preserve history while removing authority. A retired spec should keep its text, date, author, and rationale. It should be marked retired, linked to successor behavior if one exists, and excluded from default generation context. Tests tied to retired behavior should either be deleted, moved to compatibility suites, or documented as historical. This is the specification equivalent of decommissioning a service.
The same process applies to prompts. A prompt that once produced good output may become dangerous after the underlying model changes. A generation instruction that worked for a monolith may be wrong after a service split. Prompts used as reusable development tools should have versioning, owners, and deprecation notes. Otherwise the team ends up with prompt folklore: snippets copied into new work long after their assumptions expired.
Spec retirement is not glamorous, but it is part of treating intent as source code. Code has dead branches. Specs have dead assumptions. Both need deletion discipline.