The Throughput Team Breaks
The team looked productive until the launch slipped.

Key Takeaways
- More pull requests, specs, and messages can hide slower decisions and wider review queues.
- The bottleneck ladder moves from production to integration, evaluation, judgment, and accountability.
- Raw artifact count should become an anti-metric, not the operating headline.
- Weekly reviews should ask which decisions became harder because output increased.
AI-native team throughput is a weak progress signal once machines can produce drafts faster than people can judge them.
The team looked productive until the launch slipped.
Every dashboard said the same reassuring thing. Pull requests were up. Product specification drafts were up. Sales enablement content was up. Customer research summaries were up. The engineering manager had a weekly slide showing that the team was "AI-accelerated" because people were closing more tickets per person. The demo environment improved every Friday. The product, however, did not ship. It got wider, not closer. Each meeting opened with five new options and ended with three unresolved risks. The AI tools had removed the friction from producing work, but nobody had rebuilt the system for deciding what work mattered.
This is the first organizational failure mode of AI-native work. A team that was already confused about priorities becomes faster at expressing that confusion. The machine does not fix a weak product instinct, an unclear owner, an unresolved customer segment, a brittle trust boundary, or a missing evaluation standard. It turns all of them into more polished artifacts. The old team model assumed output was expensive, so output became the visible proxy for progress. Once output becomes cheap, that proxy breaks.
The chapter's claim is simple: an AI-native team cannot be managed primarily by throughput. Throughput still matters, especially in delivery and support operations, but it stops being the best measure of human contribution. The scarce variable becomes judgment: choosing the right problem, setting the right standard, rejecting plausible but wrong solutions, knowing when a model-generated artifact is only a draft, and owning the consequences of a decision.
The danger is subtle because the old metrics improve first. Teams do not initially feel broken; they feel energized. Developers complete routine code faster. Support agents resolve more cases per hour. PMs write richer specs. Marketers generate more campaign variants. Those gains are real, and research supports the productivity potential. But the better evidence also warns against simplistic interpretation: gains differ by task, skill level, workflow, and organizational context. The leader's job is to ask what new bottleneck appears after production becomes cheaper.
Research spine
This chapter uses: Brynjolfsson, Li, Raymond, Generative AI at Work, NBER Working Paper 31161; Peng et al., The Impact of AI on Developer Productivity: Evidence from GitHub Copilot; DORA, State of AI-assisted Software Development 2025; Forsgren et al., The SPACE of Developer Productivity.
Why raw output became misleading
Old management systems made sense under old constraints. If implementation was expensive, measuring the amount of implementation told you something useful. If writing a first draft took hours, draft count was not a terrible signal of effort. If code took days to produce, lines or tickets could serve as crude evidence of movement. AI assistance attacks that assumption directly. It lowers the cost of producing the visible artifact while leaving many of the hard decisions untouched.
That means a team can improve its output metrics while reducing its decision quality. A product manager can generate ten versions of a roadmap without improving the company's strategic focus. An engineer can open more pull requests while increasing review burden and integration risk. A customer-success team can send more personalized messages while avoiding the hard question of which customers should be saved and which should be allowed to churn. In each case, the machine creates more surface area for human judgment, not less.
The SPACE framework is useful here because it cautions against one-dimensional productivity measurement. It treats productivity as a composition of satisfaction and well-being, performance, activity, communication and collaboration, and efficiency and flow. AI-native teams need that broader view even more urgently, because activity becomes easier to inflate. A raw count of artifacts is now the least trustworthy part of the measurement system.
The new bottleneck ladder
A useful way to diagnose the shift is to walk the bottleneck ladder. At the bottom is production: can the team create enough artifacts to operate? AI improves this quickly. Above that is integration: can the artifacts fit together without creating contradictions? AI can help, but it also creates more combinations to reconcile. Above that is evaluation: can the team tell which output is good? This becomes the first serious bottleneck. Above evaluation is judgment: can the team decide which good output is worth pursuing? Above judgment is accountability: can someone own the outcome after the machine has done the work?
Most organizations get stuck between evaluation and judgment. They can generate candidate answers, but cannot decide which candidate answer should become policy, product behavior, customer communication, roadmap, or shipped code. This is why "human in the loop" becomes overloaded. The loop is not a staffing model; it is a bottleneck. If every machine-generated artifact requires a senior human to read it end to end, the organization has converted cheap output into expensive review debt.
The first hiring consequence
Hiring for an AI-native team begins with accepting that the person who can produce the most artifacts may not be the most valuable hire. The valuable hire is the person who can produce a reliable decision environment. That person clarifies the standard, narrows the problem, constructs the evaluation, names the risk, records the reasoning, and leaves behind an artifact that other people and machines can operate against.
This does not mean every hire must be senior. It means every role must be connected to a judgment system. Junior people can still learn, execute, and contribute; in fact, they need better apprenticeship than before because the machine hides intermediate struggle. But the team must stop assuming that human value equals manual production. The new question is: what decision, standard, boundary, or learning loop does this person improve?
Operating table
| Old team question | AI-native replacement | Why the change matters |
|---|---|---|
| How many tickets did we close? | Which customer or system outcome changed? | Ticket count rises easily when AI drafts implementation; outcome proves relevance. |
| Who wrote the most? | Who clarified the standard others can reuse? | The standard compounds across machine-generated artifacts. |
| Can this person execute? | Can this person judge, recover, and learn? | Execution is increasingly shared with tools; recovery remains accountable to humans. |
| Is the team busy? | Where is the review bottleneck? | AI often moves work from production into evaluation. |
Artifact example: a weekly bottleneck review that looks beyond activity
ai_native_team_bottleneck_review:
cadence: weekly
artifacts_reviewed:
- shipped_outcomes
- generated_artifacts
- review_backlog
- unresolved_decisions
- incidents_or_near_misses
questions:
- "Which outputs increased this week?"
- "Which decisions became harder because output increased?"
- "Which artifact should become a reusable standard?"
- "Which senior reviewer is becoming the hidden bottleneck?"
- "What can be evaluated mechanically next week?"
anti_metric:
name: "raw artifact count"
warning: "Do not use as the primary measure of human contribution."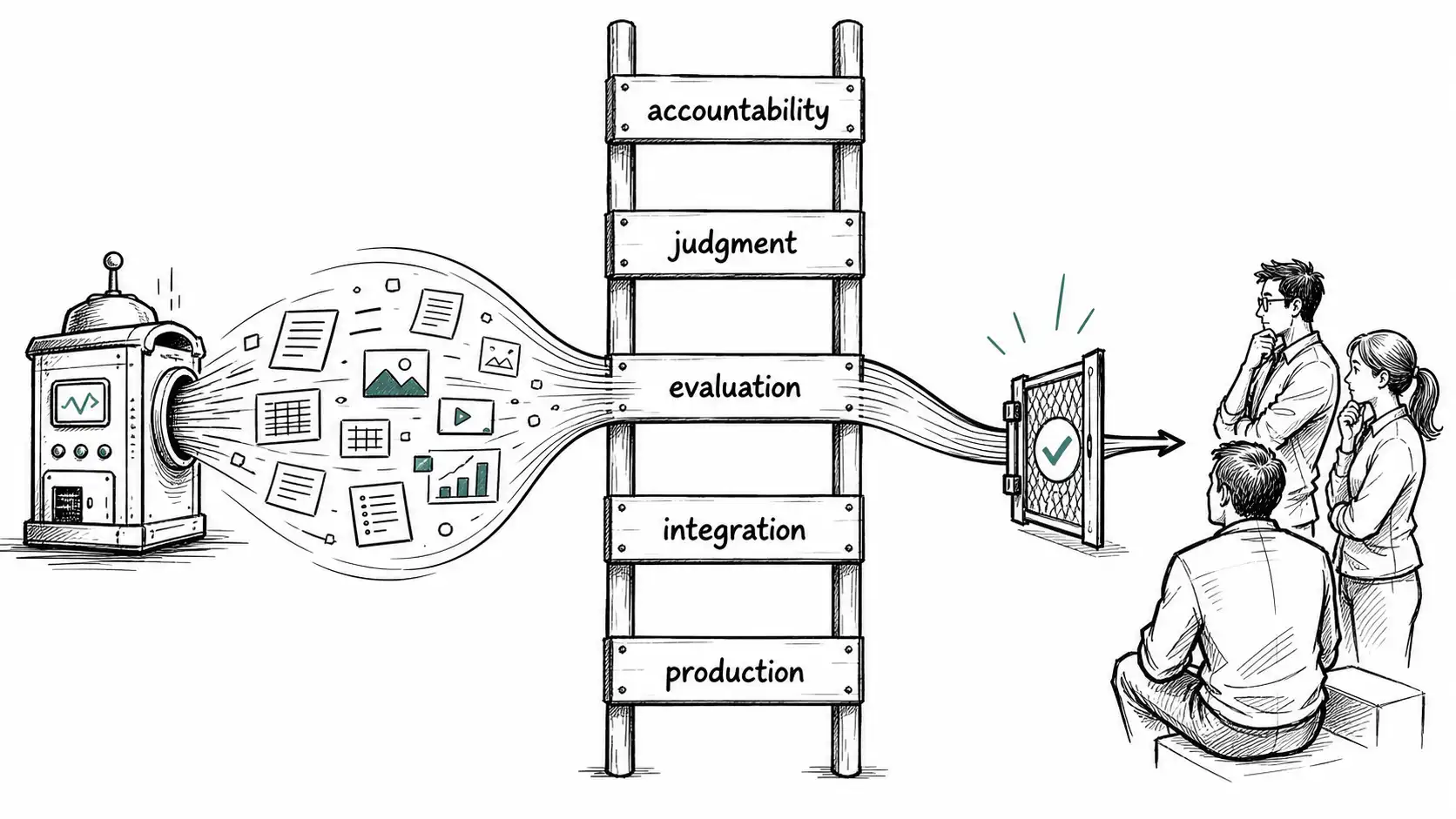
Checklist
- Identify which old productivity metric became easier to inflate.
- Name the current human bottleneck: review, decision, risk, or ownership.
- Separate artifact production from outcome ownership in status reporting.
- Create one reusable standard this week instead of reviewing the same class of output repeatedly.
- Protect senior judgment from becoming an invisible queue.
Takeaway
When output gets cheaper, the team has to manage the bottleneck that appears after output.
Internal map
For the larger argument, keep this chapter connected to the AI-Native thesis, Building an AI-Native Team, The Judgment Economy, and Human in the Loop Is Not a Plan.