Seniority, Review Load, and Apprenticeship
The senior engineers were drowning. Not in implementation, but in review.

Key Takeaways
- AI acceleration often moves time from writing into review, where senior capacity is scarce.
- Review should be routed by risk, with mechanical checks and rubrics absorbing low- and medium-risk work.
- Apprenticeship reps should teach comparison, critique, and rubric writing.
- Senior contribution compounds when repeated review becomes standards and infrastructure.
AI-native apprenticeship has to teach discrimination: people learn by comparing, critiquing, and routing generated work, not by producing boilerplate alone.
The senior engineers were drowning. Not in implementation, but in review. AI tools had made junior engineers faster at creating changes, but not equally faster at understanding system consequences. The result was a queue of plausible pull requests, generated tests, half-understood migrations, and architectural questions disguised as small diffs.
The old apprenticeship model assumed juniors learned by doing the easy parts manually. AI removed some of those reps. The team needed a new way to teach judgment before review became the bottleneck that killed the productivity gain.
This chapter argues that AI-native seniority is not about writing more than others. It is about carrying larger judgment surfaces while building systems that transfer judgment to others. Senior people become maintainers of standards, reviewers of high-risk work, designers of learning loops, and owners of the decision artifacts that allow less-senior people and machines to operate safely.
Research spine
This chapter uses: DORA, State of AI-assisted Software Development 2025; Forsgren et al., The SPACE of Developer Productivity; Edmondson, The Fearless Organization / psychological safety research; Peng et al., The Impact of AI on Developer Productivity: Evidence from GitHub Copilot.
The review bottleneck
AI acceleration often moves time from writing to reviewing. That can be good: review is where quality lives. It becomes bad when review is undifferentiated. If every generated artifact requires the same senior attention, the senior people become a queueing system. Their calendar fills with reviews that should have been handled by tests, rubrics, static checks, linters, evals, preflight gates, or peer comparison.
The fix is not to ask seniors to work harder. The fix is to stratify review by risk. Low-risk generated work should be checked mechanically and sampled. Medium-risk work should be reviewed against a clear rubric. High-risk work should receive senior attention before generation, not only after. The senior should shape the task, standard, and boundary, so the output arrives closer to safe.
New apprenticeship reps
AI-native apprenticeship must create deliberate judgment reps. Instead of assigning a junior person to write boilerplate manually, ask them to compare three generated implementations against a design rubric. Ask them to explain why one test is shallow and another test captures a meaningful invariant. Ask them to classify customer cases by risk and propose an automation boundary. Ask them to write the checklist a model will later use.
The rep shifts from production to discrimination. That does not eliminate hands-on work; people still need to build. But the learning objective becomes explicit: see the difference between plausible and correct, between local improvement and system regression, between helpful automation and unsafe autonomy.
Seniority as standard-setting
In AI-native organizations, seniority expresses itself through reusable standards. A senior engineer who reviews the same generated-code issue ten times has not solved the problem; they have become the problem's human patch. A senior engineer who turns those ten issues into a generator constraint, CI rule, design note, or review checklist has converted judgment into infrastructure.
This is the most important change for performance management. A senior person's contribution should be measured partly by the judgment load they remove from the system without reducing safety. That is different from measuring how many artifacts they personally approve.
Operating table
| Seniority level | Old visible contribution | AI-native contribution | Managerial signal |
|---|---|---|---|
| Junior | Completes assigned work | Learns to classify, verify, and explain generated work | Reasoning is visible and coachable |
| Mid-level | Owns feature delivery | Owns workflow slice with tests, prompts, and evals | Can reduce review burden for common cases |
| Senior | Designs systems and reviews others | Creates standards that safely increase autonomy | Turns repeated review into infrastructure |
| Staff+ | Sets architecture across teams | Shapes judgment economy of the organization | Reduces cross-team ambiguity and risk |
Artifact example: risk-based review routing
review_routing:
low_risk:
examples: ["copy changes", "generated unit-test additions", "non-critical refactors"]
gate: ["automated checks", "peer sample review"]
medium_risk:
examples: ["API behavior changes", "workflow prompt changes", "support automation policy edits"]
gate: ["rubric review", "owner approval"]
high_risk:
examples: ["security-sensitive code", "pricing logic", "customer-facing autonomous action"]
gate: ["senior design review before generation", "eval evidence", "rollback plan"]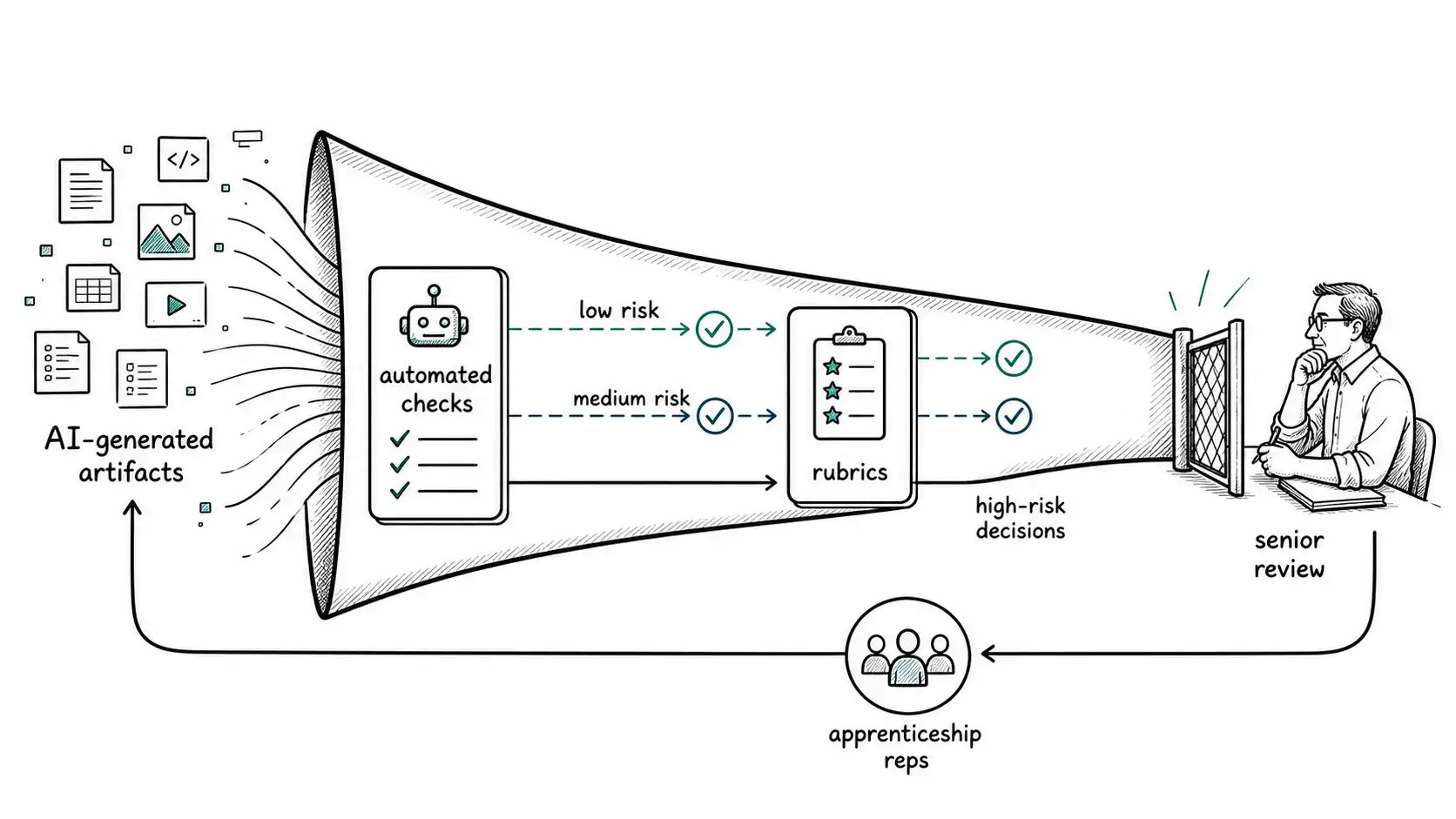
Checklist
- Measure review load after AI adoption.
- Classify generated work by risk before assigning reviewer attention.
- Create apprenticeship tasks based on comparison, critique, and rubric writing.
- Reward seniors for turning repeated review into standards.
- Keep juniors close to consequences, not only tools.
Takeaway
AI-native apprenticeship teaches people to discriminate, not merely to produce.
Internal map
For the larger argument, keep this chapter connected to the AI-Native thesis, Building an AI-Native Team, The Judgment Economy, and Human in the Loop Is Not a Plan.