Operating Cadences and Performance Management
The manager wanted an AI adoption scorecard. The first draft had tool usage, prompt count, generated words, generated lines of code, and number of employees trained.

Key Takeaways
- Tool usage, prompt counts, and generated words are context metrics, not proof of progress.
- Operating cadences should expose judgment bottlenecks, autonomy changes, learning updates, and trust gaps.
- Performance reviews should reward people who reduce system ambiguity and review debt.
- Healthy teams allocate time to both exploration and exploitation.
AI-native performance management measures whether the system makes better decisions, not whether people create more machine-assisted artifacts.
The manager wanted an AI adoption scorecard. The first draft had tool usage, prompt count, generated words, generated lines of code, and number of employees trained. It looked professional and measured almost nothing that mattered. The second draft started with decision latency, review queues, defect escape rate, customer impact, learning-loop quality, and cost-to-serve. It was harder to collect. It was finally useful.
AI-native performance management has to measure the system, not the spectacle.
This chapter turns the staffing model into weekly and monthly management practice. AI-native teams need cadences that expose bottlenecks, improve standards, and protect judgment quality. The cadence must be light enough to run and strong enough to prevent the most common failure: believing adoption has happened because usage has increased.
Research spine
This chapter uses: DORA, State of AI-assisted Software Development 2025; Forsgren et al., The SPACE of Developer Productivity; Google SRE Book; March, Exploration and Exploitation in Organizational Learning.
The four cadences
The first cadence is the weekly judgment review: which decisions were hard, slow, escalated, or reversed? The second is the automation boundary review: which workflows can safely move up or down the autonomy ladder? The third is the learning review: what failure cases entered the eval set, rubric, playbook, or training exercise? The fourth is the trust review: what risks, incidents, complaints, permission issues, or audit gaps appeared?
These reviews do not need separate meetings in small teams. They do need separate questions. A single weekly operating review can cover them if the agenda is explicit.
Performance without artifact worship
Individual performance should not be reduced to AI usage. A person who uses AI constantly but creates review debt is not performing well. A person who uses AI selectively and creates a reusable standard may be creating more use. The measurement system should recognize outcome contribution, judgment quality, collaboration, learning, and system improvement.
SPACE again helps because it resists single-metric management. DORA's AI-assisted development research also points leaders away from tool-centric narratives and toward the organizational system. The people-management version of that lesson is: do not promote the person who produces the most machine-assisted output if their work makes the system harder to trust.
Exploration and exploitation
March's exploration/exploitation distinction becomes practical in AI-native management. Teams need exploration: trying new workflows, model capabilities, prompting patterns, agent behaviors, and automation boundaries. They also need exploitation: standardizing what works, reducing variance, hardening controls, and training the organization. Too much exploration creates permanent pilot mode. Too much exploitation creates stale playbooks and missed opportunities.
The cadence should deliberately allocate time to both. A healthy AI-native team has sanctioned experiments and a mechanism for retiring experiments that do not earn their keep.
Operating table
| Cadence | Primary question | Owner | Output |
|---|---|---|---|
| Weekly judgment review | Where did decisions slow or fail? | Team lead | Bottleneck fixes and standards |
| Automation boundary review | Can autonomy change safely? | Orchestrator + Trust Steward | Boundary decision |
| Learning review | What did failures teach us? | Learning Operator | Eval/rubric/playbook updates |
| Trust review | What evidence would an auditor or customer need? | Trust Steward | Evidence gaps and mitigations |
Artifact example: an AI-native scorecard that avoids artifact worship
ai_native_scorecard:
adoption:
tool_usage: "context only, not success metric"
outcomes:
customer_metric: "resolved cases without reopening"
engineering_metric: "defect escape rate"
revenue_metric: "pilot-to-paid conversion"
system_health:
review_queue_age_days: 2.5
decision_latency_days: 1.2
automation_incidents: 0
cost_per_outcome: "$3.40"
learning:
new_eval_cases_added: 24
repeated_failure_classes: 2
standards_updated: 3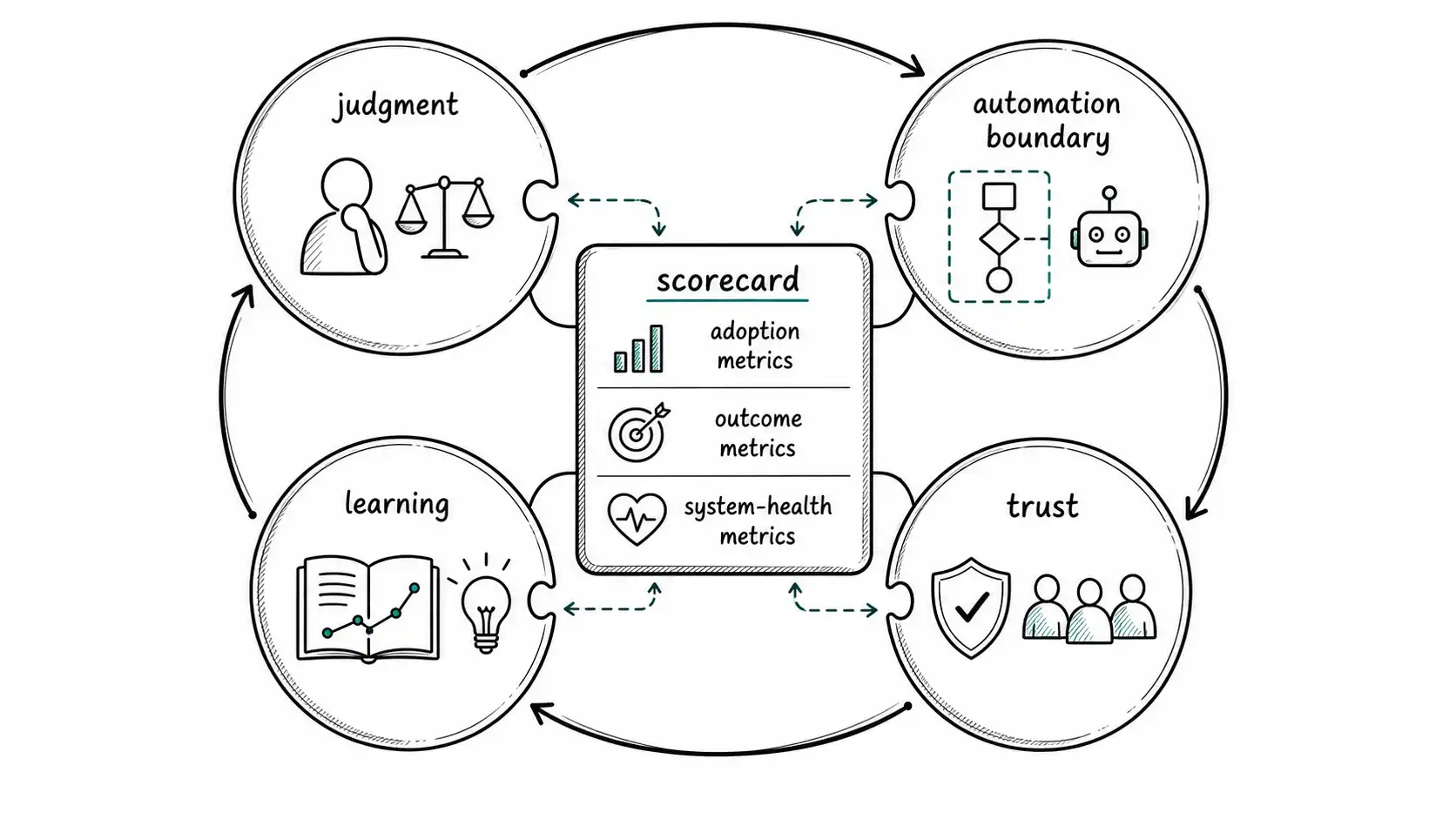
Checklist
- Treat tool usage as context, not success.
- Track review queue age and decision latency.
- Add failure cases to evals or rubrics within the same cadence that discovers them.
- Allocate explicit time to exploration and exploitation.
- Reward people who reduce system ambiguity.
Takeaway
AI-native performance management measures whether the system makes better decisions, not whether people make more artifacts.
Internal map
For the larger argument, keep this chapter connected to the AI-Native thesis, Building an AI-Native Team, The Judgment Economy, and Human in the Loop Is Not a Plan.