Scaling Without Making Humans the Bottleneck
The company had one successful AI workflow: support reply drafting. It saved time, improved consistency, and made new agents productive faster.

Key Takeaways
- A successful AI workflow becomes a scaling problem when every new use case needs the same senior reviewers.
- Controlled autonomy should rise only when standards, evidence, monitoring, and rollback are ready.
- Judgment artifacts should be versioned and treated as operational infrastructure.
- The operating model should centralize common controls while keeping outcome ownership local.
Scaling AI-native teams means converting judgment into infrastructure so senior reviewers are not the only thing keeping automation safe.
The company had one successful AI workflow: support reply drafting. It saved time, improved consistency, and made new agents productive faster. Then every function wanted the same pattern. Legal wanted clause drafting. Sales wanted account research. Product wanted roadmap analysis. Engineering wanted code agents. Finance wanted variance explanations. Suddenly the successful workflow became a scaling crisis because every new use case wanted the same three senior reviewers.
The team had learned to use AI. It had not learned to scale judgment.
The closing chapter gives leaders a scaling model. AI-native teams scale by converting judgment into artifacts, automation gates, evals, ownership maps, and operating cadences. They do not scale by asking senior people to approve everything faster. The goal is controlled autonomy: more machine action where the standard is clear, the risk is bounded, the evidence is available, and rollback is possible.
Research spine
This chapter uses: DORA, State of AI-assisted Software Development 2025; NIST AI Risk Management Framework; OWASP Top 10 for Large Language Model Applications; Google SRE Book; Team Topologies, Key Concepts.
The autonomy ladder
Every workflow should be placed on an autonomy ladder. Level 0 is manual work with AI used only for private assistance. Level 1 is draft assistance with full human review. Level 2 is recommendation with sampled review. Level 3 is bounded action with monitoring and rollback. Level 4 is autonomous operation within a narrow, well-evaluated domain. The point is not to rush upward. The point is to know where you are and what evidence is required to move.
Scaling requires many workflows to sit at different levels. A company can have autonomous internal ticket triage while keeping customer-facing contract language at draft-only. Maturity is not uniform autonomy; it is differentiated autonomy.
The judgment artifact stack
The stack includes problem statements, decision records, rubrics, eval sets, risk registers, prompt/spec versions, test suites, incident reviews, customer feedback, and owner maps. These artifacts are not paperwork. They are how the organization prevents human judgment from being trapped in private memory.
The strongest teams treat these artifacts as infrastructure. They are versioned, reviewed, searchable, and used by both humans and machines. When a workflow improves, the artifact changes. When an incident occurs, the artifact changes. When the company enters a new market or customer segment, the artifact changes.
The operating model at scale
At scale, AI-native team design resembles platform thinking. Stream-aligned teams own customer outcomes. Platform teams provide common AI capabilities, security controls, evaluation infrastructure, and observability. Enabling teams help groups adopt practices without creating permanent dependency. Complicated-subsystem teams own hard model, data, retrieval, or governance areas.
The leader's job is to avoid two extremes: centralizing all AI work into a gatekeeping team, or decentralizing all AI work into uncontrolled local experiments. The right model creates common controls and local ownership.
Operating table
| Scale problem | Bad response | Better response |
|---|---|---|
| Too many artifacts | Hire more reviewers | Create rubrics, evals, and risk routing |
| Too many tools | Let every team choose | Platform common controls with local configuration |
| Too many pilots | Declare innovation success | Require evidence before expansion |
| Too much risk | Ban AI broadly | Define autonomy ladders and trust boundaries |
Artifact example: an autonomy ladder policy
autonomy_ladder_policy:
level_0_private_assist:
customer_visible: false
evidence_required: "none beyond normal policy"
level_1_draft:
customer_visible: "after human approval"
evidence_required: "review rubric"
level_2_recommendation:
customer_visible: "human chooses"
evidence_required: "sampled accuracy and failure taxonomy"
level_3_bounded_action:
customer_visible: true
evidence_required: "eval pass, monitoring, kill switch, owner"
level_4_autonomous_domain:
customer_visible: true
evidence_required: "continuous eval, incident playbook, audit trail, rollback rehearsal"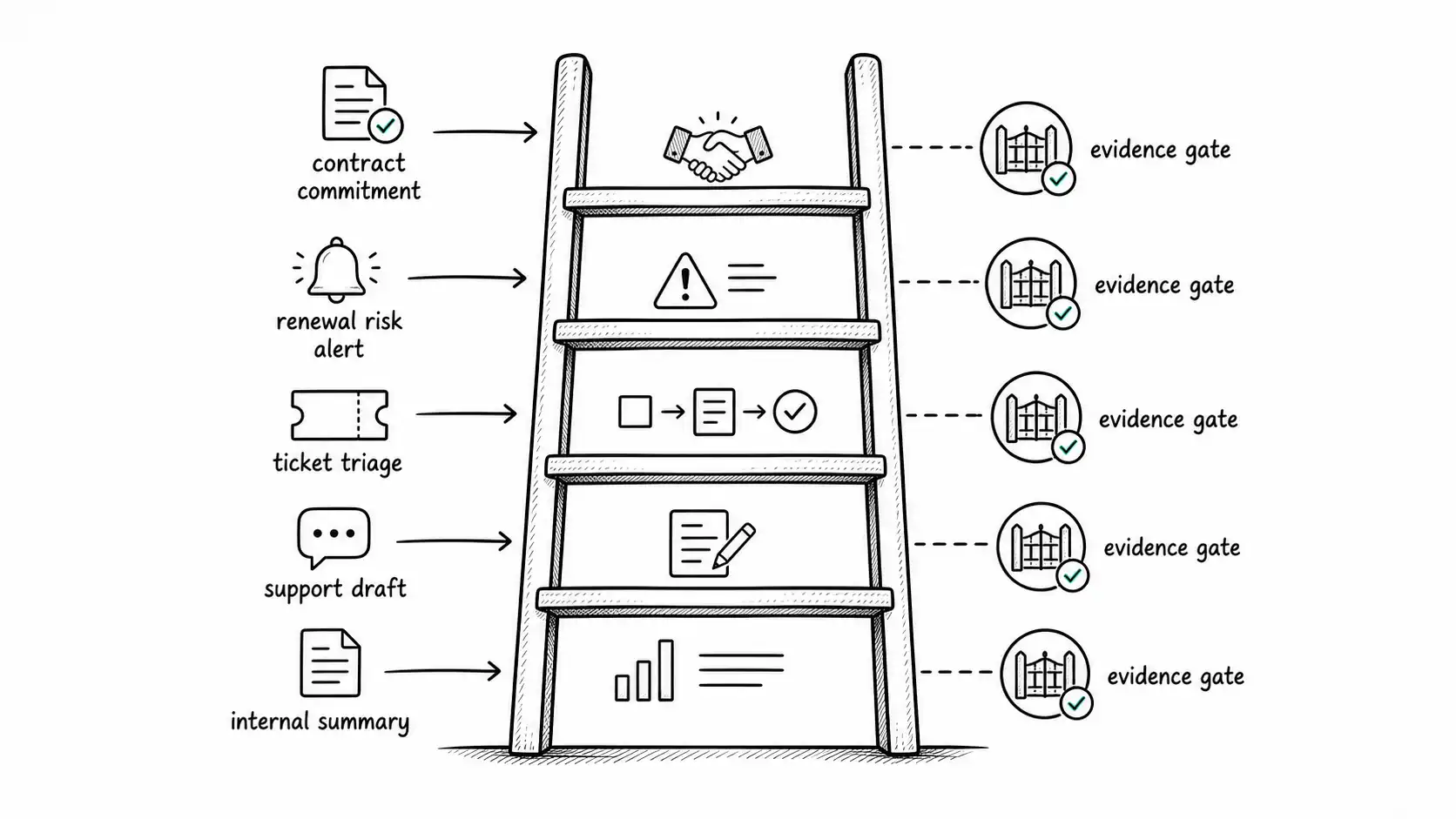
Checklist
- Place each AI workflow on an autonomy ladder.
- Require evidence, not enthusiasm, to move up a level.
- Version the judgment artifacts that let others operate safely.
- Centralize common controls; decentralize outcome ownership.
- Scale by reducing review demand per unit of work, not by overloading reviewers.
Takeaway
AI-native teams scale when judgment becomes infrastructure.
Internal map
For the larger argument, keep this chapter connected to the AI-Native thesis, Building an AI-Native Team, The Judgment Economy, and Human in the Loop Is Not a Plan.