Instrument Behavior and Learn From Contact
The product team watched request volume and declared adoption. The support team watched confused escalations and knew something was wrong.

The product team watched request volume and declared adoption. The support team watched confused escalations and knew something was wrong. The model was being used, but not always trusted. Users copied answers into another tool for verification. Some ignored correct refusals. Some accepted bad summaries because they looked official.
Usage was not behavior. Instrumentation had to become more honest.
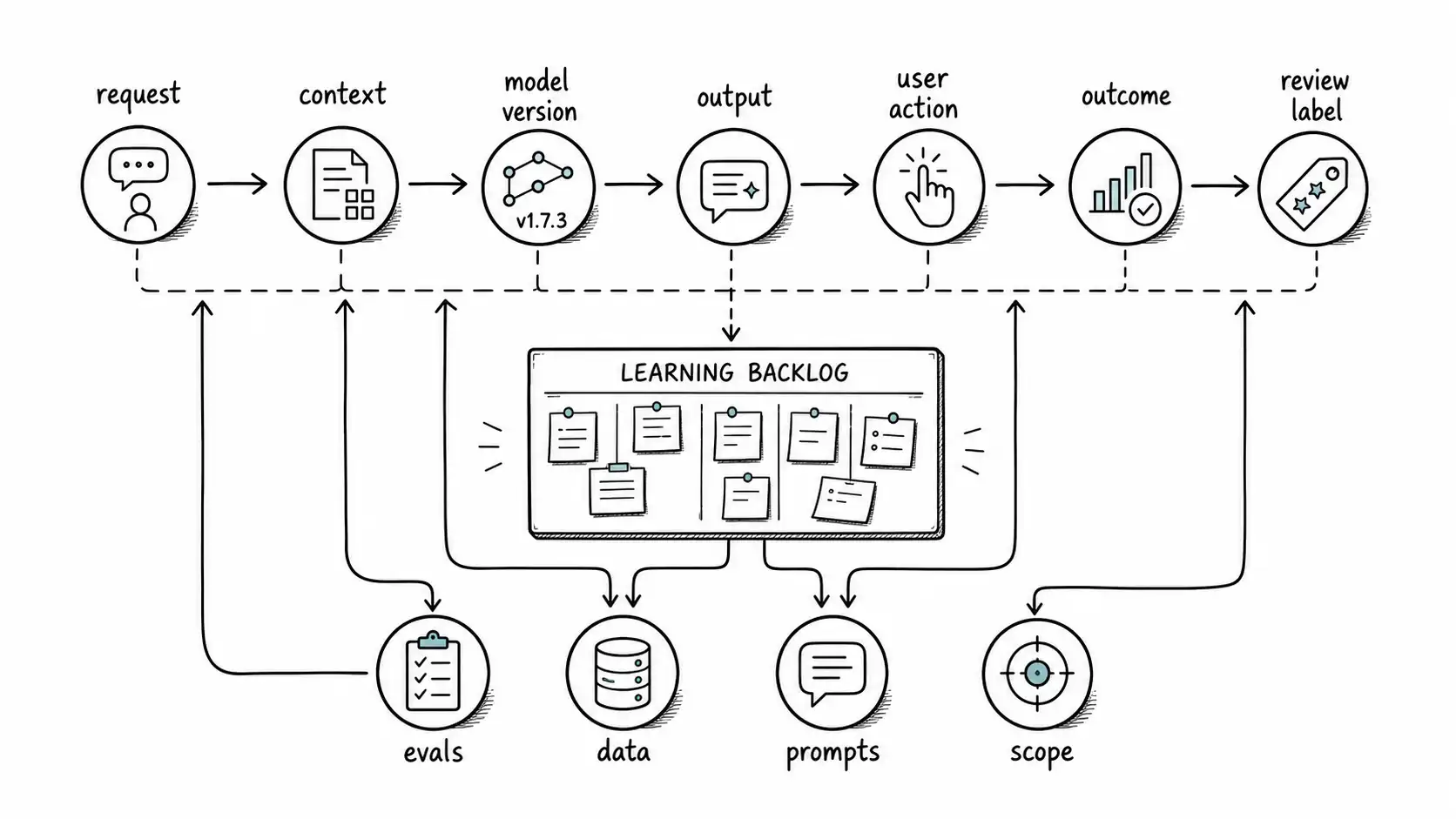
AI product instrumentation must capture what the system did, what the user did with it, what quality signals appeared, what it cost, how long it took, where it refused, where it escalated, and where it was overridden. Without behavior instrumentation, the team cannot learn from contact with real users.
Research spine
This chapter uses: Google SRE Book; DORA, State of AI-assisted Software Development 2025; OpenAI Evals; Forsgren et al., The SPACE of Developer Productivity.
The behavior event
A useful event record includes user intent category, input source, retrieval set or context reference, model/prompt version, output type, confidence or score where meaningful, latency, cost, refusal/escalation status, user action, later outcome, and review label. Not every product can collect every field, and privacy constraints matter. But the team should know which fields are required to improve the system.
From telemetry to learning
Instrumentation is not learning until someone changes the product. A weekly review should convert observations into eval cases, prompt/spec changes, data fixes, UX changes, scope changes, or rollout decisions. The learning loop must have an owner. Otherwise dashboards become wallpaper.
Qualitative signals
Quantitative metrics miss important signals: confusion, distrust, workarounds, hesitation, overreliance, and misuse. User interviews, session replay where appropriate, support notes, reviewer comments, and field observations should feed the same learning backlog as metrics.
Operating table
| Signal | What it reveals | Action |
|---|---|---|
| Override rate | Users disagree with output | Review failure cases |
| Refusal rate | Scope boundary pressure | Adjust scope or education |
| Escalation rate | Automation limit | Improve workflow or handoff |
| Cost per task | Economic sustainability | Optimize routing or pricing |
| Latency abandonment | UX mismatch | Async or budget redesign |
| Review label | Quality truth | Eval/rubric update |
Artifact example: a behavior event for AI product instrumentation
{
"event": "ai_answer_served",
"workflow": "policy_assistant",
"scope": "benefits_policy",
"prompt_version": "2026-04-12",
"retrieval_corpus_version": "hr_approved_v18",
"latency_ms": 1840,
"estimated_cost_usd": 0.021,
"refused": false,
"escalated": false,
"user_action": "copied_answer",
"review_label": null,
"outcome_join_key": "case_9a41"
}
Checklist
- Define behavior events before pilot.
- Track user action after output, not only request volume.
- Join outcomes back to AI events where possible.
- Review qualitative signals alongside metrics.
- Convert observations into artifact updates weekly.
Takeaway
AI products learn from contact only when behavior is instrumented and someone owns the learning loop.
Operational note: Usage can hide distrust
A user may use an AI feature frequently while verifying every answer elsewhere. In the context of Instrument Behavior and Learn From Contact, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The durable AI product operations argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Field expansion: Dashboards need decision rights
Instrumentation without a team empowered to change the product produces awareness without improvement. In the context of Instrument Behavior and Learn From Contact, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The durable AI product operations argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Design consequence: Qualitative evidence finds the why
Metrics show that users override; interviews and review notes often explain why. In the context of Instrument Behavior and Learn From Contact, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The durable AI product operations argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Managerial implication: Usage can hide distrust
A user may use an AI feature frequently while verifying every answer elsewhere. In the context of Instrument Behavior and Learn From Contact, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The durable AI product operations argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Production implication: Dashboards need decision rights
Instrumentation without a team empowered to change the product produces awareness without improvement. In the context of Instrument Behavior and Learn From Contact, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The durable AI product operations argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Operational note: Qualitative evidence finds the why
Metrics show that users override; interviews and review notes often explain why. In the context of Instrument Behavior and Learn From Contact, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The durable AI product operations argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.