The Generated PR That Passed
The pull request was green. Unit tests passed.

A generated PR is safe to merge only when the team can prove intent, provenance, risk class, behavior coverage, ownership, and rollback. Green tests are a starting gate, not proof that machine-authored code belongs in production.
The pull request was green. Unit tests passed. The linter passed. The type checker passed. The code was readable. The AI assistant had implemented the feature in one afternoon, and the engineer who requested it understood enough to explain the happy path. Two weeks later, the team rolled it back after a customer discovered that the new workflow allowed an archived account to be reactivated through a path that the original spec had never mentioned.
The failure was not that the model wrote bad code. The failure was that the lifecycle treated generated code as if it were ordinary code written by an author who fully understood the domain.
AI-assisted coding changes the SDLC because it changes the relationship between author, artifact, and intent. The person submitting the change may not be the line-by-line author. The model may introduce patterns that look conventional but ignore local constraints. The spec may be underspecified because the team relied on the model to infer intent. The review burden increases because the code can be plausible, complete, and wrong in ways that tests do not yet cover.
This chapter names the core problem: generation increases implementation speed before it increases intent clarity or evaluation coverage.
Key Takeaways
- A green build proves known checks passed; it does not prove generated code respects domain intent.
- Generated code changes the author problem because the submitter may not be the line-by-line author.
- Provenance turns prompt, context, model, human owner, and release trace into replayable evidence.
- The review target moves from admiration of code quality to verification of the evidence chain.
Research spine
This chapter uses: Peng et al., The Impact of AI on Developer Productivity: Evidence from GitHub Copilot; GitHub Research, Quantifying GitHub Copilot's impact on developer productivity and happiness; DORA, State of AI-assisted Software Development 2025; NIST SP 800-218, Secure Software Development Framework; SWE-bench.
What passing tests no longer prove
Passing tests have never proved correctness. In an AI-native workflow, the gap becomes more visible. Generated code can optimize for the tests it sees, mimic familiar patterns, and satisfy local checks while violating untested business invariants. The more code a model can produce, the more important it becomes to ask what the tests are actually protecting.
Software teams have always needed requirements, code review, static analysis, and production monitoring. AI does not replace those. It increases the volume of change that reaches them. A green build should be treated as a precondition for review, not a substitute for review.
The author problem
Human authors carry context in their heads. That is a weakness, but it is also a source of tacit constraint. A model does not carry the local history unless the workflow provides it. It may not know that a table is being deprecated, that an integration partner interprets null differently, that a legacy flag cannot be removed until quarter close, or that a regulatory customer has a special path. If the prompt omits the context, the generated code can be locally elegant and globally unsafe.
Therefore the lifecycle must record provenance: what prompt, spec, context files, model, tool, and human review produced the change. Provenance is not for blame. It is for replay. When the incident happens, the team must reconstruct why the change seemed acceptable.
The SDLC moves toward evidence
AI-native software delivery is less about trusting the author and more about trusting the evidence chain. The question becomes: does this change have a clear intent, sufficient context, appropriate risk classification, mechanical checks, behavior evaluation, human ownership, and production traceability? If the answer is no, the lifecycle should reject the change regardless of whether the code looks good.
This shift can feel bureaucratic if implemented poorly. Implemented well, it reduces friction because ordinary low-risk changes move quickly through automation while high-risk changes receive attention before they become large diffs.
Operating table
| Old PR question | AI-native PR question | Reason |
|---|---|---|
| Does the code look correct? | Does the change satisfy traceable intent? | Generated code can be plausible without matching the business need. |
| Did tests pass? | What behavior is not covered by tests? | Green checks expose only known assertions. |
| Who wrote this? | Who owns this? | The machine may draft; a human must accept consequence. |
| Can we merge? | What risk class and rollback path apply? | Review depth should match potential harm. |
Artifact example: metadata attached to an AI-generated pull request
ai_generated_pr_metadata:
intent_id: "SPEC-1842"
model: "coding-assistant"
generation_mode: "agentic_edit"
context_files:
- "specs/account-reactivation.md"
- "docs/archive-policy.md"
- "src/accounts/state_machine.ts"
human_owner: "eng.platform.accounts/alina"
risk_class: "high"
required_gates:
- "state-machine invariant tests"
- "security review"
- "migration rollback plan"
production_trace:
feature_flag: "account_reactivation_v2"
dashboard: "accounts/reactivation"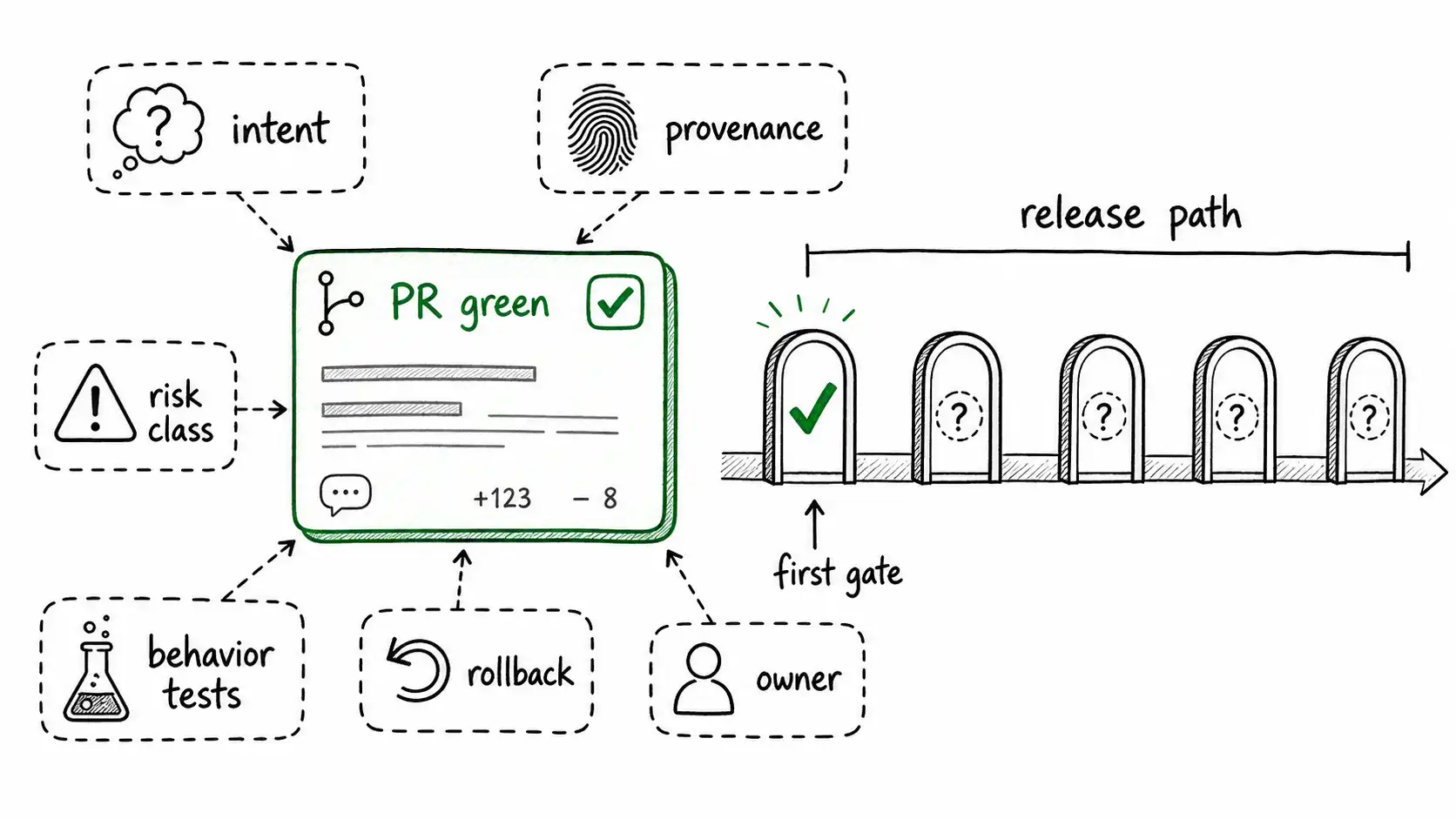
Checklist
- Do not treat a green CI run as proof of domain correctness.
- Attach intent and provenance to AI-assisted changes.
- Risk-classify generated diffs before review.
- Require the human submitter to own the change.
- Ask what untested invariant the generated code might violate.
Takeaway
AI-native SDLC begins when a generated diff is treated as evidence to verify, not work to admire.
Operational note: The model is not an accountable author
A tool can propose implementation, but it cannot attend the incident review or negotiate the customer consequence. In the context of The Generated PR That Passed, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Field expansion: Tests encode known concerns
Generated code exposes gaps in the team's test imagination because it can create paths humans did not anticipate. In the context of The Generated PR That Passed, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Design consequence: Provenance enables replay
Without provenance, the team can see what changed but not why the change seemed reasonable. In the context of The Generated PR That Passed, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Managerial implication: The model is not an accountable author
A tool can propose implementation, but it cannot attend the incident review or negotiate the customer consequence. In the context of The Generated PR That Passed, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Production implication: Tests encode known concerns
Generated code exposes gaps in the team's test imagination because it can create paths humans did not anticipate. In the context of The Generated PR That Passed, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.