Release, Observability, Rollback, and Incident Learning
The change looked small enough to ship without a feature flag. It had been generated, reviewed, tested, and merged.

AI-native release is complete only when generated behavior can be observed, explained, isolated, rolled back, and converted into a better lifecycle gate after production contact.
The change looked small enough to ship without a feature flag. It had been generated, reviewed, tested, and merged. The incident was not catastrophic, but the recovery was slow because nobody could isolate which generated behavior caused the regression. The release had evidence before deployment and almost no trace after deployment.
The AI-native SDLC must continue into production.
Release discipline becomes more important when change generation accelerates. AI-native teams need feature flags, staged rollout, behavior dashboards, prompt/spec version tracing, rollback rehearsals, and incident reviews that update the lifecycle artifacts. Production is where generated assumptions meet real users.
Key Takeaways
- Merge is not the finish line for generated behavior; production traceability is part of the SDLC.
- Feature flags and staged rollout limit blast radius and make generated changes easier to isolate.
- Dashboards should connect symptoms back to spec, prompt, context, commit, owner, and release evidence.
- Incident reviews should edit specs, evals, tests, prompts, risk triggers, or observability, not merely produce notes.
Research spine
This chapter uses: Google SRE Book; DORA, State of AI-assisted Software Development 2025; NIST AI Risk Management Framework; OpenAI Evals.
Staged release for generated behavior
A generated code path should be released like any consequential behavior change: behind a flag, through canary or progressive rollout where appropriate, and with clear owner and rollback. This matters especially when AI-assisted changes are numerous. The team needs to separate which change caused which production effect.
Feature flags are not merely product tools. They are observability and recovery tools.
Traceability after merge
Observability should link production behavior back to spec, prompt, context, model configuration, commit, feature flag, and owner where possible. This does not mean every log line carries the entire lifecycle. It means dashboards and incident tools can answer: what version of behavior was active, who owned it, what evidence approved it, and how do we turn it off?
Incident learning
An AI-native incident review should update the lifecycle. Did the spec miss a constraint? Did the prompt encourage an unsafe pattern? Did the context bundle omit a critical doc? Did CI lack a risk trigger? Did review miss a domain invariant? Did observability fail to connect behavior to change? Each answer should become a new artifact or gate.
Operating table
| Production practice | AI-native reason | Artifact |
|---|---|---|
| Feature flag | Isolates generated behavior | Flag owner and rollback note |
| Canary rollout | Limits blast radius | Rollout plan |
| Behavior dashboard | Shows real-world effect | Metric map |
| Traceability link | Connects behavior to provenance | Spec/prompt/commit references |
| Incident artifact update | Prevents repeat failure | Eval, test, rubric, or policy change |
Artifact example: release trace metadata for AI-assisted behavior
release_trace:
feature_flag: "checkout_tax_agent_v3"
spec: "SPEC-920"
prompt_hash: "sha256:18f9..."
model_config: "code-agent-2026-05"
risk_class: "class_3"
rollout:
stage: "canary"
traffic_percent: 5
dashboards:
- "checkout/tax_errors"
- "checkout/manual_overrides"
rollback:
owner: "payments-oncall"
command: "flags disable checkout_tax_agent_v3"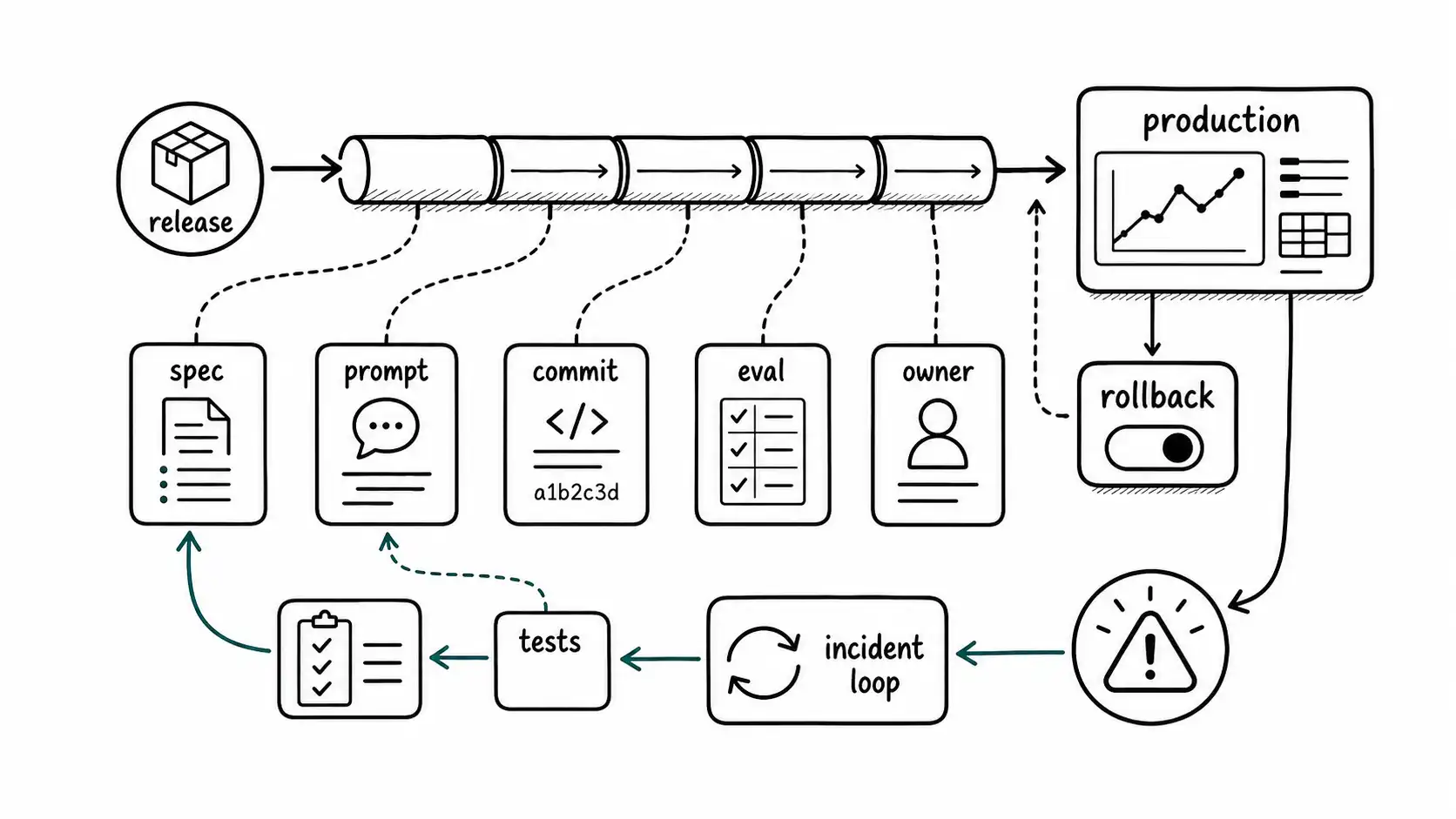
Checklist
- Use feature flags for consequential generated behavior.
- Link production dashboards to spec and change metadata.
- Rehearse rollback for high-risk AI-assisted changes.
- Turn incidents into lifecycle artifact updates.
- Track behavior, not just deployment success.
Takeaway
AI-native release is complete only when generated behavior can be observed, explained, and reversed in production.
Operational note: Merge is not the finish line
The real test of generated behavior is contact with production context. In the context of Release, Observability, Rollback, and Incident Learning, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Field expansion: Traceability reduces incident time
A team that can link a symptom to a generated change recovers faster. In the context of Release, Observability, Rollback, and Incident Learning, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Design consequence: Incident reviews should edit the system
A postmortem that does not change specs, tests, evals, or gates is only documentation. In the context of Release, Observability, Rollback, and Incident Learning, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Managerial implication: Merge is not the finish line
The real test of generated behavior is contact with production context. In the context of Release, Observability, Rollback, and Incident Learning, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Production implication: Traceability reduces incident time
A team that can link a symptom to a generated change recovers faster. In the context of Release, Observability, Rollback, and Incident Learning, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Operational note: Incident reviews should edit the system
A postmortem that does not change specs, tests, evals, or gates is only documentation. In the context of Release, Observability, Rollback, and Incident Learning, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.