Testing Behavior, Not Just Code Paths
The model generated tests for every branch it created. Coverage improved.

Testing behavior means proving that generated code satisfies the product promise, not merely that every branch of the implementation has an assertion attached to it.
The model generated tests for every branch it created. Coverage improved. The feature still failed because none of the tests represented the customer journey that mattered. The team had tested the shape of the implementation and missed the promise of the product.
AI-native testing must focus on behavior.
Generated tests are useful, but they can mirror generated assumptions. A model can write tests that confirm its own interpretation of the problem. The SDLC therefore needs behavior-first test design: scenario tests, contract tests, invariant tests, property tests, regression replays, and production-derived cases.
Key Takeaways
- Generated tests can confirm the model's interpretation instead of the business requirement.
- Independent sources of truth should include specs, incidents, user journeys, contracts, invariants, and production traces.
- Scenario and invariant tests protect meaning better than raw coverage percentages.
- Every production surprise should become a regression test, eval case, lint rule, prompt constraint, or spec clarification.
Research spine
This chapter uses: OpenAI Evals; SWE-bench; NIST SP 800-218, Secure Software Development Framework; DORA, State of AI-assisted Software Development 2025.
The self-confirming test problem
If the same prompt context produces the implementation and the tests, the tests may validate the model's interpretation rather than the business requirement. This is not unique to AI; humans also write shallow tests. AI makes it faster and prettier.
A good test suite must include independent sources of truth: specs, historical incidents, user journeys, contracts, invariants, and production traces. Generated tests should be reviewed against those sources.
Scenario and invariant testing
Scenario tests express meaningful user or system journeys. Invariant tests express rules that must always hold. For example: a finalized invoice total cannot change without a credit note; a deleted user cannot regain access through an old session; an autonomous assistant cannot send a customer-facing promise without an approved source. These tests are more important than line coverage because they protect meaning.
Production-derived evals
AI-native teams should convert incidents, near misses, support tickets, and customer reports into test cases. This is how the lifecycle learns. Each production surprise should ask: should this become a regression test, eval case, lint rule, prompt constraint, or spec clarification?
Operating table
| Test type | Protects | AI-native use |
|---|---|---|
| Unit test | Local logic | Generated quickly but reviewed for meaningful assertions |
| Contract test | Service/API compatibility | Prevents generated changes breaking consumers |
| Invariant/property test | Rules that must always hold | Protects domain semantics |
| Scenario test | User journey | Validates product promise |
| Eval/replay | Historical behavior | Prevents repeated failures |
Artifact example: a property-style test protecting a business invariant
from hypothesis import given, strategies as st
@given(
original_total=st.decimals(min_value=0, max_value=100000),
adjustment=st.decimals(min_value=-100000, max_value=100000)
)
def test_finalized_invoice_total_is_immutable(original_total, adjustment):
invoice = Invoice(total=original_total, status="finalized")
with pytest.raises(InvoiceFinalizedError):
invoice.adjust_total(adjustment)
assert invoice.total == original_total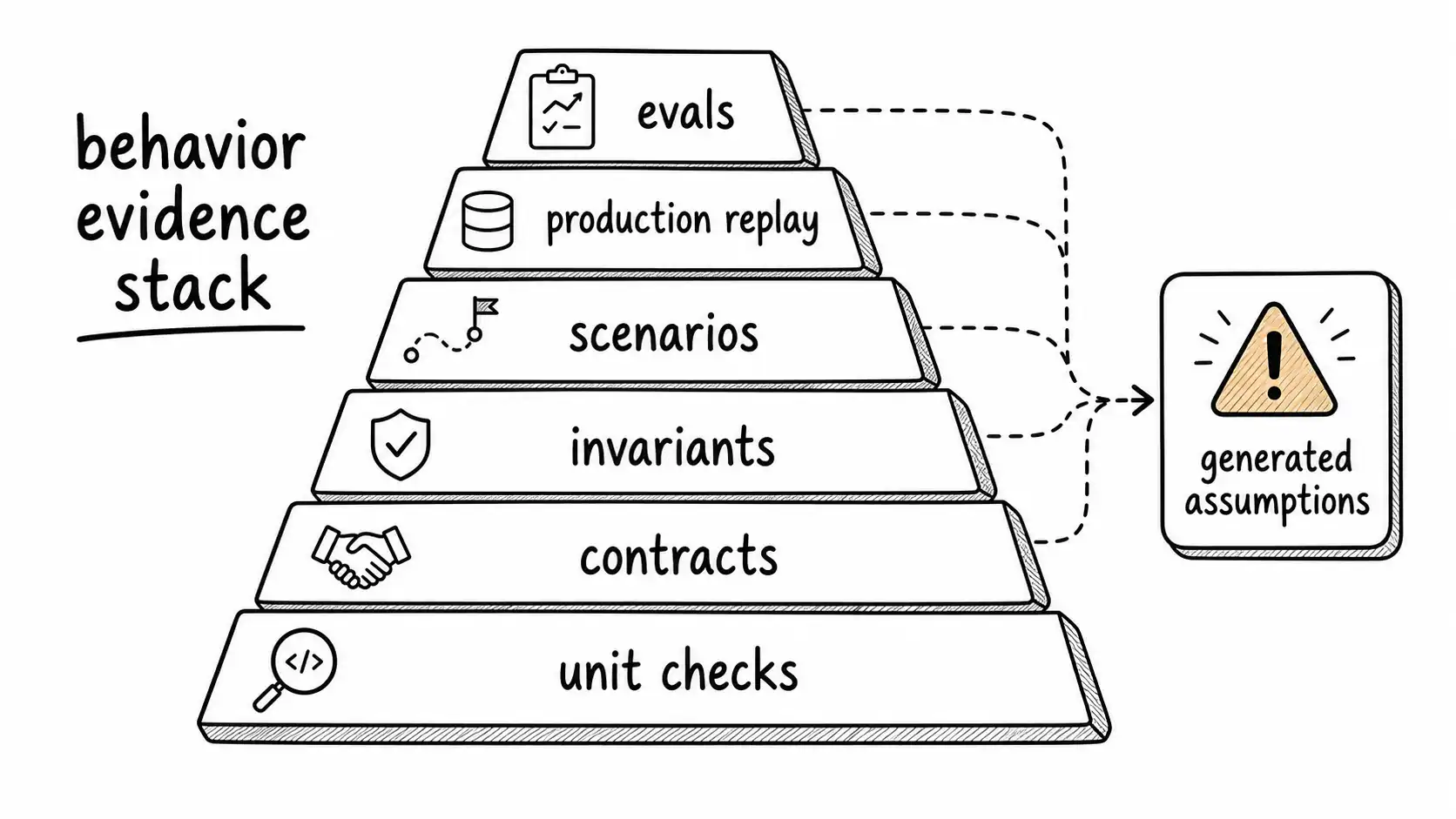
Checklist
- Do not let generated tests be the only evidence for generated code.
- Extract invariants from domain rules and incidents.
- Add production-derived cases to regression suites.
- Measure test usefulness, not only coverage.
- Separate implementation-path tests from behavior tests.
Takeaway
Generated tests are helpful only when they are anchored to independent behavioral truth.
Operational note: Coverage can be a vanity metric
AI can increase coverage while protecting nothing that matters. In the context of Testing Behavior, Not Just Code Paths, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Field expansion: Invariants encode judgment
A good invariant is a small piece of domain knowledge made executable. In the context of Testing Behavior, Not Just Code Paths, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Design consequence: Incidents should harden the suite
Every surprise is a candidate for a future gate. In the context of Testing Behavior, Not Just Code Paths, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Managerial implication: Coverage can be a vanity metric
AI can increase coverage while protecting nothing that matters. In the context of Testing Behavior, Not Just Code Paths, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Production implication: Invariants encode judgment
A good invariant is a small piece of domain knowledge made executable. In the context of Testing Behavior, Not Just Code Paths, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Operational note: Incidents should harden the suite
Every surprise is a candidate for a future gate. In the context of Testing Behavior, Not Just Code Paths, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.