AI-Native CI
The team added AI to writing code before it added AI to checking code. That was backwards.

AI-native CI is continuous integration rebuilt for machine-authored change: it still enforces mechanical quality, but it also routes risk, checks provenance, scans AI artifacts, and runs behavior evidence before review.
The team added AI to writing code before it added AI to checking code. That was backwards. Generated changes flowed into a CI pipeline designed for a slower world. The pipeline caught syntax errors and missed intent errors. It scanned dependencies and missed prompt injection paths. It ran unit tests and missed user journeys.
AI-native CI must become a judgment amplifier, not just a build machine.
Continuous integration in an AI-native SDLC has three jobs: enforce mechanical quality, route risk, and generate or select better behavioral evidence. It should remove repetitive review burden without pretending to solve judgment entirely.
Key Takeaways
- AI-native CI should make reviewers smarter before they open the diff.
- Prompt files, eval definitions, model configs, context manifests, and permissions need checks alongside code.
- Behavioral evals in CI prevent known AI feature regressions from repeating.
- CI should summarize risk and provenance, not merely return pass or fail.
Research spine
This chapter uses: NIST SP 800-218, Secure Software Development Framework; SLSA: Supply-chain Levels for Software Artifacts; OWASP LLM01:2025 Prompt Injection; OpenAI Evals; DORA, State of AI-assisted Software Development 2025.
Mechanical checks still matter
Formatting, linting, type checking, static analysis, dependency scanning, secret scanning, and license checks become more important when code generation increases volume. Generated code can introduce dependencies, copy insecure patterns, or create secrets-handling mistakes. CI is the first line of defense against known classes of failure.
The difference is that CI must now understand AI artifacts too: prompt files, eval definitions, context manifests, model configuration, retrieval settings, and tool permission declarations.
Behavioral evidence in CI
CI can run scenario tests, contract tests, property tests, golden-path replays, and regression suites. For AI features, it can run evals over a fixed set of prompts, retrieved documents, or user cases. The point is not to make CI perfectly predict production. The point is to prevent known behavior regressions from slipping through because generated changes were too easy to produce.
CI as reviewer prefilter
A good AI-native CI pipeline tells reviewers where to look. It should summarize changed behavior, highlight risk triggers, flag missing provenance, attach generated test coverage, and compare the change against previous incidents. Reviewers should enter the conversation with a map, not a pile of files.
Operating table
| CI layer | Checks | AI-native extension |
|---|---|---|
| Build hygiene | Compile, lint, types | Generated-code policy checks |
| Security | Secrets, dependencies, SAST | Tool permission and prompt-injection path checks |
| Behavior | Unit, integration, contract | Eval cases, scenario replay, regression traces |
| Review support | Status checks | Risk summary and provenance manifest |
Artifact example: a CI skeleton for AI-native changes
name: ai-native-ci
on: [pull_request]
jobs:
risk:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: classify generated change
run: python tools/classify_risk.py --diff "$GITHUB_SHA"
mechanical_checks:
runs-on: ubuntu-latest
steps:
- run: npm ci
- run: npm run lint
- run: npm test
- run: npm audit --audit-level=high
ai_feature_evals:
if: contains(github.event.pull_request.labels.*.name, 'ai-feature')
runs-on: ubuntu-latest
steps:
- run: python evals/run.py --suite customer_facing_prompts --threshold 0.92
provenance:
runs-on: ubuntu-latest
steps:
- run: python tools/check_provenance.py --required-for medium,high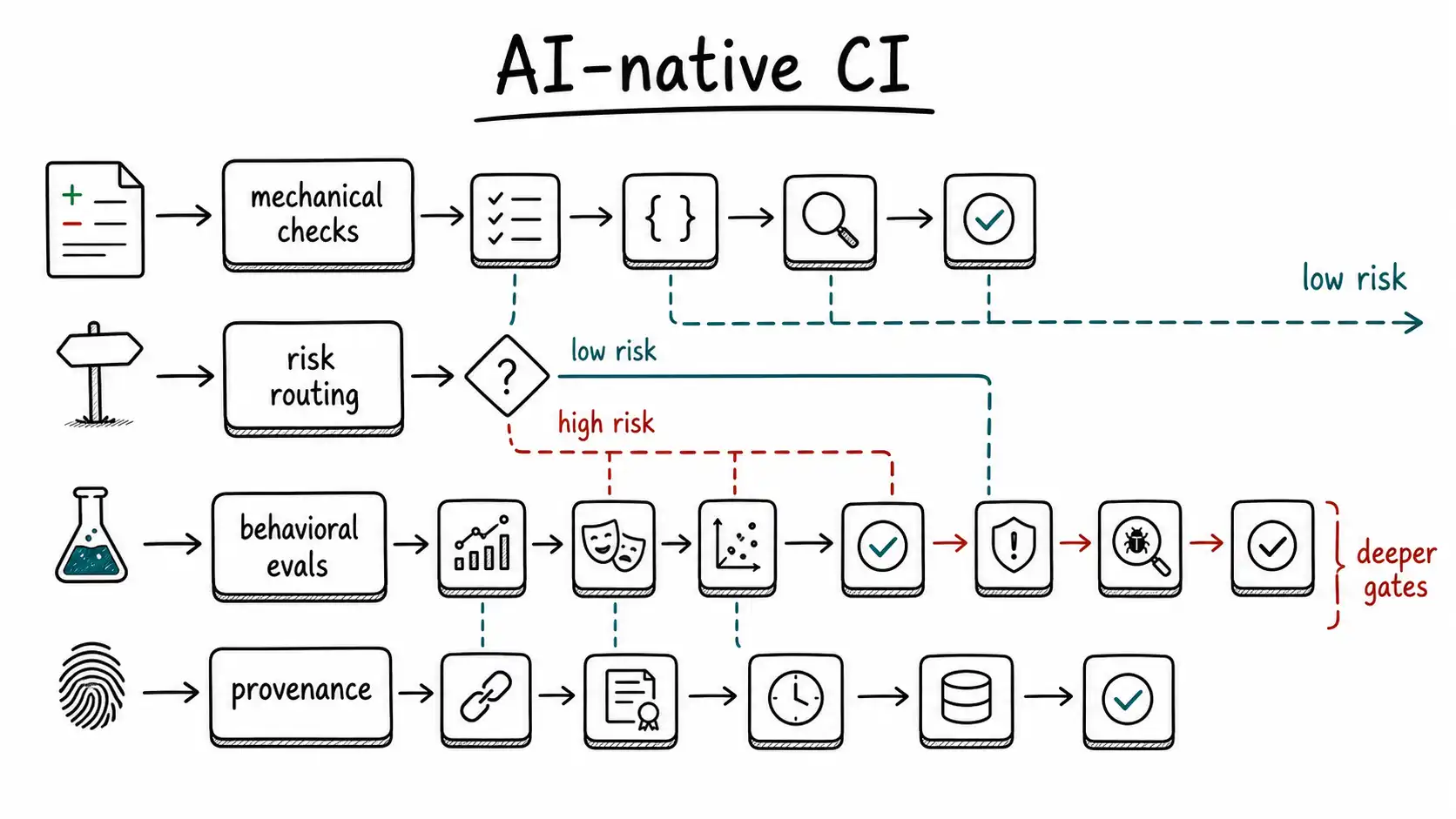
Checklist
- Extend CI to prompt, eval, and model-configuration artifacts.
- Use CI to classify risk and summarize review focus.
- Run behavioral evals for AI features.
- Fail missing provenance for medium/high risk changes.
- Feed incident learnings back into CI gates.
Takeaway
AI-native CI should make reviewers smarter before they open the diff.
Operational note: Generated volume demands automated prefiltering
Human review cannot scale if the pipeline only says pass or fail. In the context of AI-Native CI, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Field expansion: AI artifacts need checks too
Prompt files, tool manifests, and eval definitions influence behavior as directly as code in many systems. In the context of AI-Native CI, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Design consequence: CI is an evidence assembler
The best pipeline assembles evidence for the human decision rather than pretending to replace the decision. In the context of AI-Native CI, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Managerial implication: Generated volume demands automated prefiltering
Human review cannot scale if the pipeline only says pass or fail. In the context of AI-Native CI, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Production implication: AI artifacts need checks too
Prompt files, tool manifests, and eval definitions influence behavior as directly as code in many systems. In the context of AI-Native CI, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Operational note: CI is an evidence assembler
The best pipeline assembles evidence for the human decision rather than pretending to replace the decision. In the context of AI-Native CI, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.