The ACCEPT Loop
The team tried to write an AI coding policy and produced a thirty-page document nobody used. The useful version became a loop written on one page: Articulate, Create with provenance, Check mechanically, Evaluate behavior, Prove ownership, Trace in production.

The ACCEPT loop is the operating model for AI-native software delivery: Articulate intent, Create with provenance, Check mechanically, Evaluate behavior, Prove ownership, and Trace in production.
The team tried to write an AI coding policy and produced a thirty-page document nobody used. The useful version became a loop written on one page: Articulate, Create with provenance, Check mechanically, Evaluate behavior, Prove ownership, Trace in production. ACCEPT was not a slogan. It became the lifecycle gate every generated change passed through.
ACCEPT is the operating model for AI-native software delivery. It exists because the old SDLC stages still matter but need to be reweighted. Writing code is not the center. Articulating intent and evaluating behavior are equally central. Provenance and traceability, once reserved for regulated environments or mature supply chains, become everyday delivery practices for teams that generate code quickly.
Key Takeaways
- ACCEPT works because it assigns the right gate to the right risk instead of treating every generated change alike.
- Articulation prevents the model from filling ambiguous product gaps with generic code.
- Mechanical checks absorb repeatable failure classes so senior judgment can focus on behavior and risk.
- Production tracing closes the loop after merge, where generated assumptions meet real users.
Research spine
This chapter uses: DORA, State of AI-assisted Software Development 2025; NIST SP 800-218, Secure Software Development Framework; SLSA: Supply-chain Levels for Software Artifacts; Google SRE Book; OpenAI Evals.
A - Articulate
Articulate the change before asking the model to implement it. The articulation should include desired behavior, non-goals, constraints, risk class, affected users, and observable success. This is not ceremony. It prevents the model from filling ambiguous gaps with generic patterns.
Good articulation also gives reviewers something to review against. Without it, review becomes taste-based.
C - Create with provenance
Creation includes the model, prompt, context, retrieval, tool permissions, and human steering. Provenance lets the team inspect the creation path later. It also deters careless use: when people know the prompt and context may be attached to the change, they behave more deliberately.
Provenance should be proportional. A copy update does not need the same record as a payment-state-machine change.
C - Check mechanically
Static analysis, dependency scanning, type checking, linting, formatting, secret scanning, generated-code policy checks, and test selection all belong here. Mechanical checks should absorb everything that should not require senior judgment. The better the checks, the more senior attention can be reserved for intent and architecture.
Mechanical checks are not a replacement for behavioral evaluation. They are the floor.
E - Evaluate behavior
Behavior evaluation asks whether the system does what the intent requires under normal, edge, adversarial, and historical cases. For AI-native development, behavior evaluation often includes generated test cases, regression replays, property tests, contract tests, and production-like scenario tests.
If the model changed the behavior, the team needs evidence about behavior, not only code style.
P and T - Prove ownership, Trace in production
Proving ownership means the responsible human or team accepts the change, the risk class, the rollback path, and the monitoring. Tracing in production means the team can see whether the change behaves as expected after release. AI-native delivery does not end at merge. It ends after the system has learned from contact with production.
Operating table
| ACCEPT step | Gate question | Typical artifacts |
|---|---|---|
| Articulate | What should this change mean? | Spec, risk class, constraints |
| Create with provenance | How was it produced? | Prompt, model, context references |
| Check mechanically | Does it meet known mechanical standards? | CI, scanners, linters, policy checks |
| Evaluate behavior | Does it behave correctly? | Scenario tests, evals, regression replay |
| Prove ownership | Who accepts consequence? | Approvals, rollback owner |
| Trace in production | Can we observe real behavior? | Dashboards, logs, flags, incident links |
Artifact example: an ACCEPT gate configuration
accept_gate:
articulate:
required: ["intent_id", "risk_class", "non_goals", "success_signal"]
create_with_provenance:
required_for_risk: ["medium", "high"]
capture: ["model", "prompt_hash", "context_refs", "tool_permissions"]
check_mechanically:
required: ["tests", "static_analysis", "dependency_scan", "secret_scan"]
evaluate_behavior:
required_for_risk:
medium: ["scenario_tests"]
high: ["scenario_tests", "regression_replay", "owner_review"]
prove_ownership:
required: ["human_owner", "rollback_plan"]
trace_in_production:
required: ["feature_flag", "dashboard", "alert_owner"]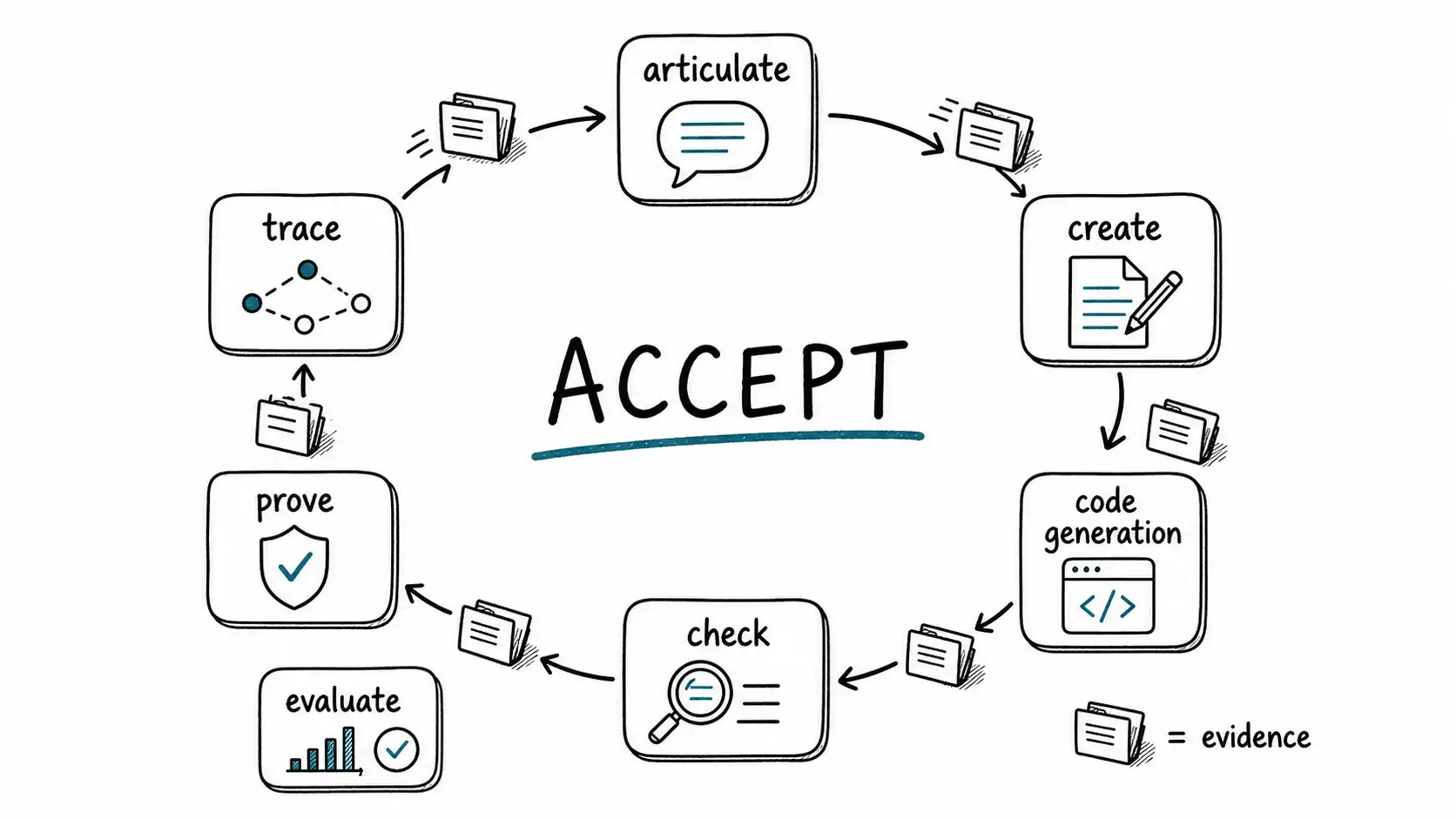
Checklist
- Apply ACCEPT to one generated-code workflow.
- Make risk class determine how much provenance is required.
- Automate mechanical checks before expanding AI usage.
- Treat behavior evaluation as a release gate.
- Attach production tracing to consequential changes.
Takeaway
The AI-native SDLC is not faster because it skips gates; it is faster because the right gates handle the right risks.
Operational note: A loop beats a policy PDF
A concise operational loop is more likely to change daily engineering behavior than a broad AI policy. In the context of The ACCEPT Loop, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Field expansion: Risk proportionality prevents theater
If every change requires maximum evidence, people route around the process; if no change does, incidents multiply. In the context of The ACCEPT Loop, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Design consequence: Production closes the lifecycle
Generated code cannot be considered safe until its behavior is observable where users and systems actually interact with it. In the context of The ACCEPT Loop, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Managerial implication: A loop beats a policy PDF
A concise operational loop is more likely to change daily engineering behavior than a broad AI policy. In the context of The ACCEPT Loop, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Production implication: Risk proportionality prevents theater
If every change requires maximum evidence, people route around the process; if no change does, incidents multiply. In the context of The ACCEPT Loop, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.