Risk-Classifying Generated Diffs
The small diff touched the pricing calculation. The large diff updated comments and tests.

Generated diffs should be sorted by consequence before they are sorted by size. In an AI-native SDLC, a one-line billing, auth, privacy, or prompt change can deserve more review than a thousand-line documentation update.
The small diff touched the pricing calculation. The large diff updated comments and tests. The code-review tool sorted by lines changed. The staff engineer sorted by consequence. That difference is the beginning of AI-native review.
Generated changes must be classified by risk before they are reviewed by size, convenience, or apparent simplicity.
AI tools can make consequential changes look ordinary. A one-line conditional can alter billing. A small data transformation can leak tenant information. A generated prompt update can change a customer-facing assistant's commitments. Risk classification routes scarce human review to the changes that deserve it.
Key Takeaways
- Risk class should be based on harm, reversibility, visibility, uncertainty, and blast radius.
- Prompt files and model configuration are behavior files and need risk triggers too.
- Automated path and artifact classifiers protect senior review attention.
- Incident reviews should update the classifier so the next generated diff is routed earlier.
Research spine
This chapter uses: NIST SP 800-218, Secure Software Development Framework; NIST AI Risk Management Framework; OWASP Top 10 for Large Language Model Applications; SLSA: Supply-chain Levels for Software Artifacts.
Risk is about consequence
Risk class should be based on potential harm, not size. Important dimensions include customer visibility, financial impact, security exposure, privacy exposure, reversibility, dependency breadth, regulated context, and uncertainty. A change that is easy to write may still be hard to recover from.
The classification should happen early, ideally at spec or branch creation. If classification waits until review, the team may already have generated a large implementation against the wrong control path.
The four classes
A practical scheme has four classes. Class 0: trivial and internal. Class 1: low-risk user experience or maintainability changes. Class 2: medium-risk behavior changes that affect users or internal operations but are reversible and monitored. Class 3: high-risk changes affecting money, security, privacy, legal representation, data integrity, or irreversible action.
Each class gets different gates. The point is not to create bureaucracy. It is to protect attention.
How AI changes the review queue
AI-generated diffs can be large, frequent, and deceptively coherent. Review queues must therefore be shaped by automation. Files, paths, dependency changes, permission changes, database migrations, prompt files, policy documents, and generated test coverage can trigger risk rules. A reviewer should not have to manually discover that a generated diff changed authentication behavior.
Operating table
| Risk class | Examples | Required gates |
|---|---|---|
| 0 | Comments, formatting, generated docs for internal use | CI + owner sample |
| 1 | Low-risk UI text, non-critical refactor | CI + peer review |
| 2 | API behavior, workflow prompt, non-financial data transform | Scenario tests + owner approval |
| 3 | Auth, billing, privacy, security, irreversible customer action | Design review, security review, eval evidence, rollback rehearsal |
Artifact example: a simple risk classifier for changed paths
RISKY_PATHS = {
"billing/": "class_3",
"auth/": "class_3",
"prompts/customer_facing/": "class_2",
"migrations/": "class_2",
"docs/internal/": "class_0",
}
def classify_changed_paths(paths):
score = "class_1"
for path in paths:
for prefix, klass in RISKY_PATHS.items():
if path.startswith(prefix):
if klass > score:
score = klass
return score
print(classify_changed_paths(["billing/invoice_total.ts", "tests/invoice_total.test.ts"]))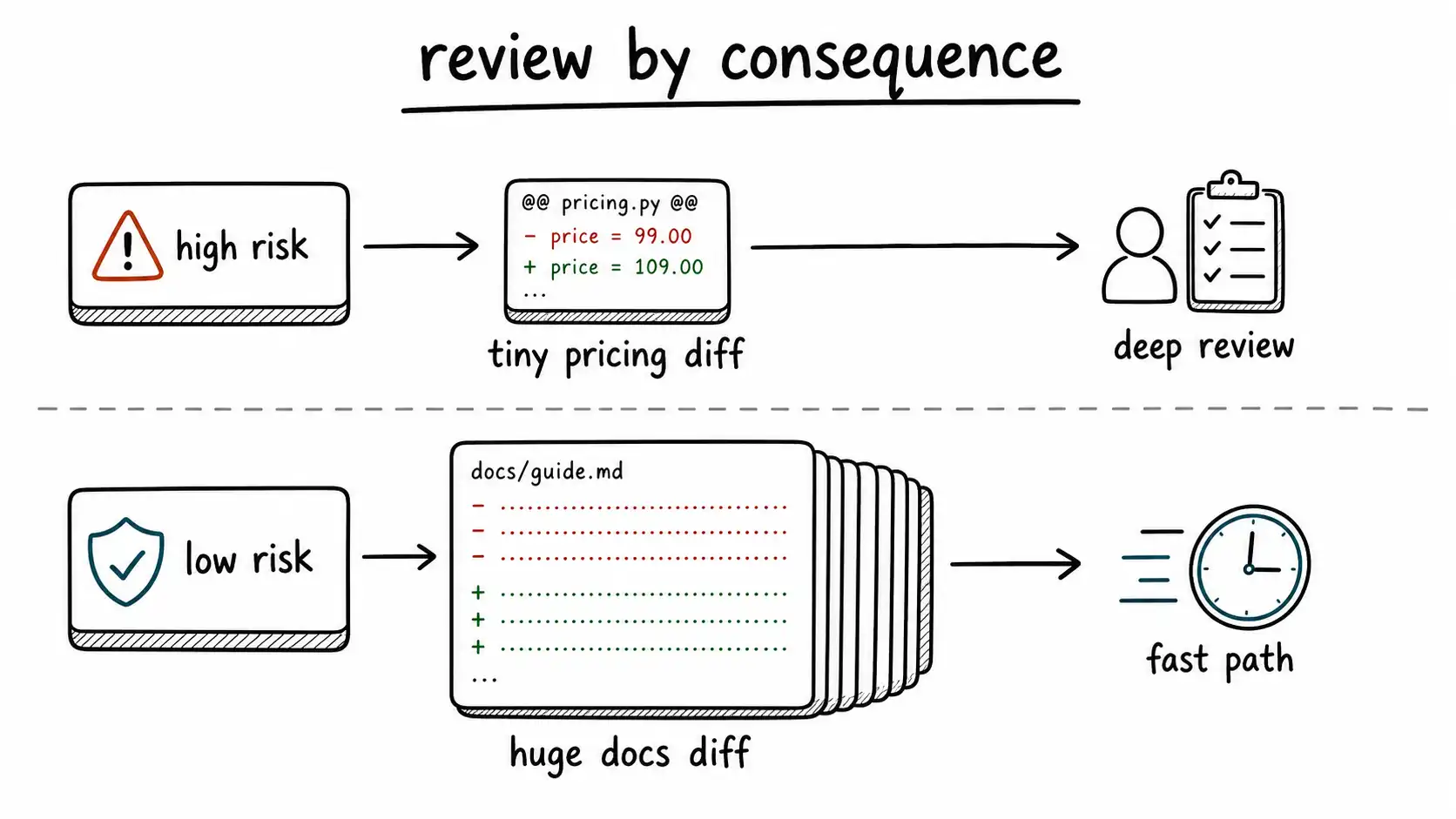
Checklist
- Classify by consequence, not lines changed.
- Create path- and artifact-based risk triggers.
- Require high-risk review before implementation grows.
- Make prompt changes risk-classifiable.
- Track whether incidents came from misclassified changes.
Takeaway
In AI-native review, the smallest diff may deserve the most attention.
Operational note: Risk routing preserves senior judgment
Without routing, senior reviewers spend attention on whatever arrives rather than what can hurt the business. In the context of Risk-Classifying Generated Diffs, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Field expansion: Prompt files are behavior files
A prompt change in an AI feature can be as consequential as application logic. In the context of Risk-Classifying Generated Diffs, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Design consequence: Classification should learn
Every incident should update the rules that classify future generated changes. In the context of Risk-Classifying Generated Diffs, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Managerial implication: Risk routing preserves senior judgment
Without routing, senior reviewers spend attention on whatever arrives rather than what can hurt the business. In the context of Risk-Classifying Generated Diffs, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Production implication: Prompt files are behavior files
A prompt change in an AI feature can be as consequential as application logic. In the context of Risk-Classifying Generated Diffs, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Operational note: Classification should learn
Every incident should update the rules that classify future generated changes. In the context of Risk-Classifying Generated Diffs, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.