Human Review When the Author Is a Model
The reviewer wrote "looks good" because the code looked good. It used the right abstractions, matched style, and came with tests.

Human review changes when the author is a model: the reviewer must inspect the supervision system around the code, not just the code style, tests, and apparent polish.
The reviewer wrote "looks good" because the code looked good. It used the right abstractions, matched style, and came with tests. The reviewer did not know the engineer had accepted most of it from an AI agent after only checking the happy path. The review was not malicious. It was calibrated to the wrong authorship model.
Review changes when authorship is shared with a machine.
Human review in the AI-native SDLC must inspect intent, context, behavior, and ownership. It should not become a line-by-line attempt to outread the model. The reviewer needs to know where the model was used, what the submitter verified, what risk class applies, and what evidence exists.
Key Takeaways
- Reviewers should review the human supervision of the model output, not only the final diff.
- Generated polish can hide missing domain understanding, so style should be automated out of review.
- Submitters must explain generated changes at the depth required by the risk class.
- Reusable review comments should become standards, prompts, or CI rules.
Research spine
This chapter uses: DORA, State of AI-assisted Software Development 2025; Forsgren et al., The SPACE of Developer Productivity; NIST SP 800-218, Secure Software Development Framework; Anthropic Claude Code Security.
Review the human's supervision
The reviewer is not only reviewing the code; they are reviewing the submitter's supervision of the tool. Did the submitter provide the correct context? Did they inspect generated dependencies? Did they run meaningful tests? Did they understand the change deeply enough to own it? Did they preserve provenance?
A person may submit code they did not manually write, but they should not submit code they cannot explain at the level required by the risk class.
Review at the right layer
Low-level style issues should be automated. Reviewers should focus on architecture, domain invariants, behavior, security, maintainability, and risk. AI-generated code can be syntactically polished, so reviewers must resist being reassured by style. A beautiful solution that ignores a domain invariant is worse than an ugly one that makes the invariant visible.
Commenting for learning
Review comments become training data for humans and potentially for internal assistants. A good review comment should name the principle, not just the local fix. Instead of saying "change this condition," say "billing state transitions must remain monotonic; this condition allows reversal after invoice finalization." That comment teaches the next engineer and improves the next prompt or rule.
Operating table
| Review focus | Question | Evidence |
|---|---|---|
| Intent | What was the change supposed to accomplish? | Spec link and non-goals |
| Supervision | How did the human verify the model output? | Verification notes |
| Behavior | What scenarios prove the invariant? | Tests/evals/replay |
| Risk | What can go wrong and how do we recover? | Risk class and rollback plan |
| Learning | What principle should future work reuse? | Review note or standard update |
Artifact example: a review comment template designed for learning
### AI-assisted change review comment template
- **Concern:** What specific behavior or invariant is at risk?
- **Evidence:** Which line, test, trace, or scenario shows the issue?
- **Principle:** What reusable rule should future generated work follow?
- **Required action:** Revise, add test, update spec, or escalate?
- **Should become a standard?** yes/no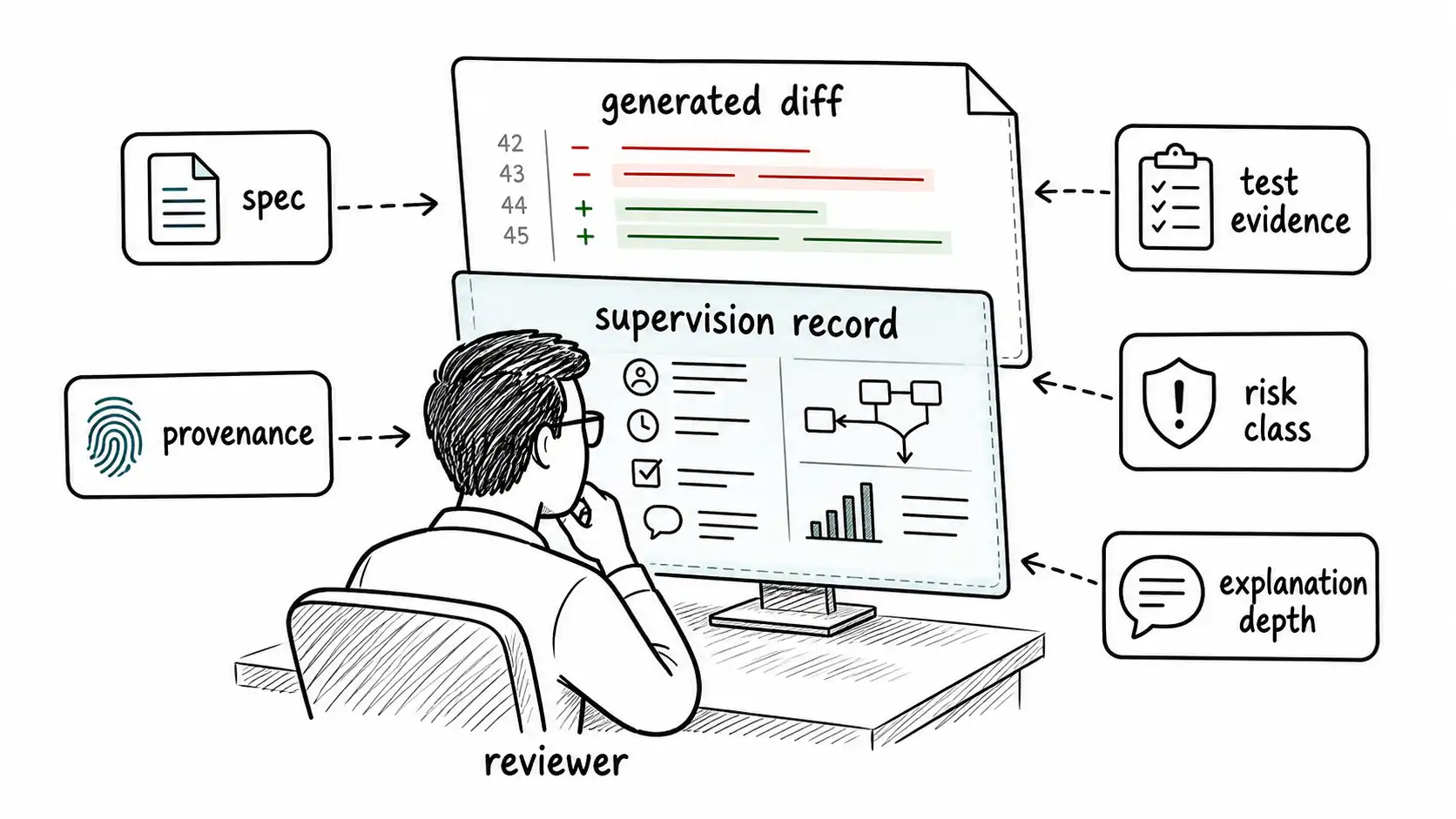
Checklist
- Require submitters to explain generated changes by risk class.
- Review supervision, not only final code.
- Automate style so review can focus on behavior.
- Turn repeated review comments into standards.
- Do not approve code whose owner cannot explain its failure modes.
Takeaway
When the author is a model, the human reviewer must evaluate the supervision system around the code.
Operational note: Review confidence must be recalibrated
Polish used to correlate weakly with care; generated polish can appear without understanding. In the context of Human Review When the Author Is a Model, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Field expansion: The submitter is still accountable
AI assistance does not move ownership to the tool, vendor, or model. In the context of Human Review When the Author Is a Model, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Design consequence: Review comments can compound
A comment that names a reusable principle is an investment in future generated work. In the context of Human Review When the Author Is a Model, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Managerial implication: Review confidence must be recalibrated
Polish used to correlate weakly with care; generated polish can appear without understanding. In the context of Human Review When the Author Is a Model, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Production implication: The submitter is still accountable
AI assistance does not move ownership to the tool, vendor, or model. In the context of Human Review When the Author Is a Model, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.
Operational note: Review comments can compound
A comment that names a reusable principle is an investment in future generated work. In the context of Human Review When the Author Is a Model, the practical danger is not that the team lacks effort; it is that effort is aimed at the wrong scarce resource. The AI-native software delivery argument says that the old visible unit of work is no longer the safest unit of management. A team can produce more drafts, more code, more messages, more analysis, or more tickets while becoming less reliable at the point where the business needs a decision. The fix is to move the management surface away from raw output and toward evidence: what was decided, by whom, from which inputs, against which criteria, with what rollback path.
A mature implementation treats this as an operating-system concern rather than a personal-performance concern. The artifact should make the judgment visible: the rubric, acceptance gate, cost line, risk boundary, owner, and expiry date. When those fields are missing, the model's speed hides organizational ambiguity. When they are present, AI acceleration becomes tractable because the team can see which decisions deserve automation, which deserve human review, and which deserve rejection before execution begins.
The useful test is whether a new teammate can replay the decision two weeks later without interviewing the original author. If replay requires folklore, the process is still human-memory-bound. If replay can be done from the artifact, the team has converted judgment into infrastructure. That conversion is the recurring discipline throughout this book: not replacing human judgment, but making human judgment explicit enough that machines can safely do more of the surrounding work.