The Output Trap
The first board update looked like victory.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The first board update looked like victory. The product team had launched an internal AI assistant for account executives, and the dashboard was almost indecently positive: proposals drafted were up 412 percent, account summaries were up 780 percent, competitive battlecards were being generated faster than enablement could review them, and the number of "customer-specific strategic plans" produced per week had jumped from thirty-two to just under five hundred. The CRO put the chart into the Monday operating review. The CTO called it the first visible proof that the company had become AI-native. Finance asked whether the next hiring plan could be reduced.
Then the quarter closed.
Win rate had not moved. Sales cycle had lengthened by four days. Discounting was worse. Customer success complained that promises made during sales calls were less precise, not more. Legal flagged three proposals that used outdated security claims copied from old material. The enablement team stopped reading most generated battlecards because there were too many to inspect and too little variation to trust. The assistant had not made the revenue motion smarter. It had made the organization more verbose.
This is the output trap: mistaking generated work for accepted work, accepted work for useful work, useful work for paid work, and paid work for durable advantage. AI makes the first category cheap. It does not automatically create the other four.
The trap is especially dangerous because the first dashboard is real. Generative systems can produce drafts, summaries, analyses, code changes, presentations, support responses, research notes, and campaign concepts at a pace that old organizations cannot match manually. That matters. A tool that helps a novice support agent resolve more tickets per hour can produce measurable gains; Brynjolfsson, Li, and Raymond's Generative AI at Work found sizable productivity effects in a customer-support deployment, especially for less experienced agents, which is exactly the kind of concrete evidence leaders should take seriously rather than dismissing automation as hype (https://www.nber.org/papers/w31161). But the study is not a license to treat all output as value. It measured a constrained workflow with observable resolutions. The company in our board update measured generated artifacts.
The economic unit changed before the measurement system did.
Before AI, artifact volume was a passable proxy for capacity in many knowledge workflows. A team that produced more support replies usually handled more support. A team that produced more code changes usually shipped more functionality. A team that produced more proposals usually pursued more revenue. The proxy was imperfect, but the cost of creating each artifact was high enough that volume carried information. Once AI lowers generation cost, volume becomes cheap noise unless it is connected to acceptance, outcome, and value capture.
The same pattern shows up in software. A team using coding agents can open more pull requests, but the scarce work may move to understanding the change, reviewing the diff, validating behavior, negotiating product tradeoffs, and paying down design debt. DORA's AI-assisted software development research frames AI not as a universal accelerant but as an amplifier of organizational systems: stronger systems absorb the tool into better delivery, weaker systems amplify ambiguity, handoff friction, and review burden (https://dora.dev/dora-report-2025/). That finding belongs at the center of the judgment economy. The bottleneck does not disappear. It migrates.
In marketing, the same trap appears as campaign inflation. If a team can produce one hundred landing-page variants, the constraint becomes knowing which customer segment each variant serves, which claims legal has approved, which channel the customer actually uses, and whether the testing plan has enough traffic to distinguish signal from randomness. In finance, AI can generate a dozen forecast narratives, but the constraint becomes deciding which assumptions are defensible, what uncertainty should be disclosed, and whether the executive team is willing to act on the forecast. In legal review, AI can summarize contracts quickly, but the constraint becomes knowing which clause is binding, which exception matters, and who owns the risk of relying on the summary.
The output trap is not that AI produces useless work. It is that organizations keep measuring the wrong layer after the cost structure has changed.
Here is the simplest layer model:
| Layer | What it means | Typical dashboard mistake |
|---|---|---|
| Generated output | The machine produced an artifact. | Counting drafts, snippets, summaries, tickets, proposals, or PRs. |
| Reviewed output | A qualified review process inspected it. | Assuming review happened because a human was "in the loop." |
| Accepted output | The organization chose to use it. | Treating approval as a clerical step rather than a decision. |
| Customer-valued output | A customer, user, employee, or regulator benefited. | Mistaking internal productivity for external value. |
| Paid output | Value was captured in price, retention, risk reduction, or margin. | Assuming usage automatically monetizes. |
| Compounding output | The work improves future judgment through data, trust, process, or learning. | Ignoring whether the system gets smarter or merely busier. |
The CEO wants the last four layers. The AI dashboard usually shows the first one.
A good judgment economy starts by refusing to count generation as the victory condition. This is not pedantry. It changes operating behavior. If the metric is generated proposals, the team will generate proposals. If the metric is accepted proposals that improve win rate without increasing discounting or legal risk, the team must design a review gate, a claim library, a pricing policy, and a feedback loop from closed-won and closed-lost analysis. The same AI model might be involved in both systems. Only one system is economically meaningful.
Consider a product analytics team. Before AI, a business stakeholder asked for one analysis, the analyst clarified the question, wrote SQL, produced a chart, and discussed the caveats. With AI, stakeholders can generate their own analyses. In the first month, "analytics delivered" triples. But the company now has twenty versions of revenue, five definitions of active customer, and a graveyard of plausible charts that no one trusts. The scarce input was never the chart. It was the interpretive contract: what question is being answered, what definition is authoritative, what decision the analysis supports, and what caveat prevents misuse.
Hayek's old knowledge problem becomes unexpectedly modern here. In "The Use of Knowledge in Society," he argued that useful knowledge is dispersed, contextual, and often unavailable to a central planner in time to act (https://www.econlib.org/library/Essays/hykKnw.html). AI changes the cost of expressing knowledge-shaped artifacts, but it does not eliminate the dispersed nature of the knowledge that makes those artifacts correct. The account executive knows the customer politics. Legal knows which claim is approved. Support knows which workaround actually resolves the incident. Finance knows which revenue recognition assumption can survive audit. The model can draft. The organization still has to coordinate knowledge.
That coordination is judgment work.
The output trap also creates a psychological hazard. Polished machine output looks more complete than it is. A rough human draft often reveals uncertainty through awkward phrasing, missing sections, and visible TODOs. AI output tends to arrive formatted, confident, and syntactically complete. The reviewer's eye relaxes. A proposal with a clean table, a crisp executive summary, and a professional tone feels more reviewed than a messy one. That feeling is not evidence. It is a risk factor.
The mistake compounds when managers use AI volume to justify headcount reduction before they redesign acceptance. A team that removes junior analysts because AI can draft analysis may discover that it also removed the apprenticeship layer where senior judgment was replicated. A team that reduces QA because AI writes tests may discover that the tests encode the same vague requirement as the generated code. A support organization that celebrates auto-drafted responses may discover that resolution did not improve because the system optimized reply speed rather than problem closure.
The economic question is not "how much work can the machine produce?" It is "which produced work deserves to become an organizational commitment?"
That is why this book uses the language of judgment rather than productivity. Productivity asks how much output is produced per unit input. Judgment asks whether the output should be accepted, priced, shipped, escalated, rejected, or learned from. In a stable factory, the distinction can feel academic. In AI-native knowledge work, it becomes the operating system.
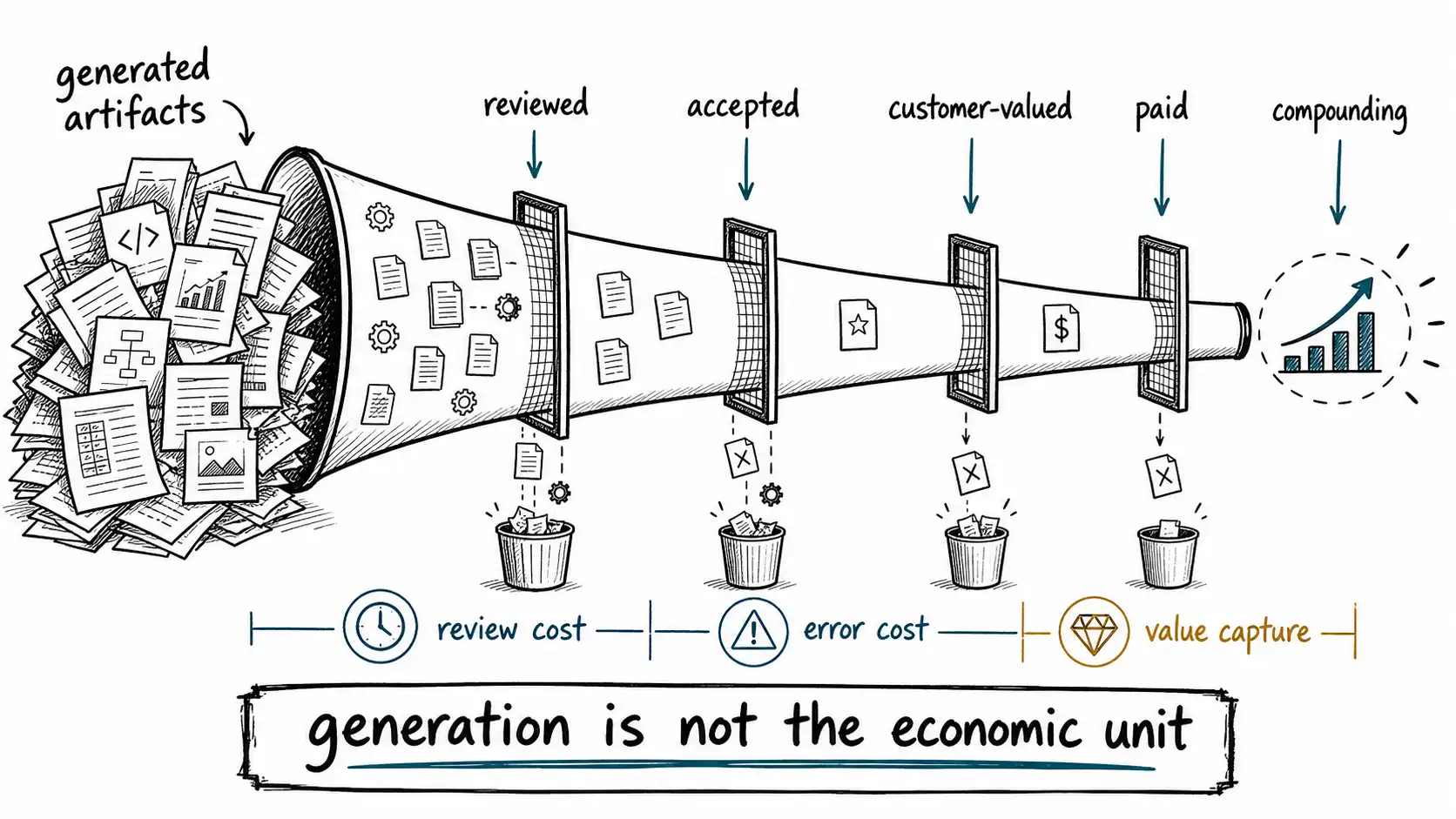
The practical correction is a new ledger. Every AI workflow should report at least five numbers: generated, reviewed, accepted, value-confirmed, and paid. The difference between generated and accepted is review friction. The difference between accepted and value-confirmed is quality uncertainty. The difference between value-confirmed and paid is monetization leakage. The difference between paid and compounding is whether the organization is merely consuming automation or building advantage.
A support example makes the idea concrete:
| Week | AI-drafted replies | Human-reviewed replies | Sent replies | Resolved cases | Paid/retained value |
|---|---|---|---|---|---|
| Before AI | 4,000 | 4,000 | 3,900 | 2,850 | Baseline |
| Month 1 | 11,500 | 5,200 | 4,700 | 2,930 | Slightly positive |
| Month 3 with risk tiers | 8,200 | 2,400 targeted + 600 sample | 5,900 | 3,640 | Materially positive |
The winning month is not the one with the most drafts. It is the one with better routing of judgment. The system learned which cases could be auto-sent, which required expert escalation, which should be sampled for quality, and which should be blocked. AI created optionality; judgment converted it into economics.
The output trap is the opening enemy of this book because it exposes the central shift. AI makes doing cheaper, but the organization is paid for decisions that survive contact with users, customers, regulators, and reality. Once doing is cheap, the cost of being wrong moves closer to the center of the P&L. The companies that win will not simply produce more. They will know what produced work deserves to become a promise.
Key Takeaways
- The first board update looked like victory.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Judgment Economy and the adjacent chapters when you need the wider Judgment Economy and AI Strategy frame.
Field note: the dashboard that lies by omission
A useful way to detect the output trap is to inspect what the dashboard cannot answer. If the dashboard can tell you how many drafts were produced but not how many were used, it is an activity dashboard. If it can tell you how many were used but not how many produced the intended outcome, it is an acceptance dashboard without a value loop. If it can tell you value but not review cost, it is a gross-value dashboard. If it can tell you review cost but not error severity, it is a quality dashboard without risk. The economic dashboard begins only when all of these views are connected.
Leaders often resist this because the first month of AI adoption looks better under activity metrics. That is exactly why the discipline is necessary. A company that changes the metric early may look slower than competitors for a quarter. It may show fewer generated assets, fewer automatic replies, fewer generated code changes, and fewer "AI-touched" opportunities. But internally it will know which machine-produced work is safe, which is profitable, and which is merely noise. In the second and third quarter, that knowledge becomes speed. Teams stop reviewing low-risk work manually. They stop generating artifacts that no one accepts. They strengthen the claim library, test suite, policy base, and review rubric. The metric moves from AI enthusiasm to operational learning.
One practical diagnostic is the "accepted outcome ratio":
accepted outcome ratio = customer-valued outputs / generated outputsA low ratio is not automatically bad. Early exploration can be noisy. But a low ratio that does not improve over time means the system is not learning. A high generated count with a flat accepted outcome ratio is output inflation. A stable generated count with a rising accepted outcome ratio is operational improvement. A falling generated count with a rising paid outcome count may be the best sign of all: the organization has learned to generate less irrelevant work.
The output trap is therefore not solved by telling people to be skeptical. It is solved by changing what gets promoted, funded, and celebrated. The manager who reduces generated volume by improving acceptance quality should be praised. The product team that narrows autonomy because it discovered an error-cost boundary should be trusted. The salesperson who refuses a generated proposal because the customer promise is wrong is protecting margin. In the judgment economy, restraint is sometimes productivity.