The Judgment Ledger
The Judgment Ledger is the central worksheet of this book. It exists because most AI business cases count the wrong thing.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The Judgment Ledger is the central worksheet of this book. It exists because most AI business cases count the wrong thing. They start with labor minutes saved, multiply by loaded cost, subtract model spend, and call the remainder ROI. Sometimes that calculation is useful. Often it is dangerously incomplete.
A proper AI-native business case must account for the decision that the machine output enters. The machine may replace execution, but the workflow still contains a point where someone or something accepts risk, commits the organization, and captures value. The Judgment Ledger makes that point explicit.
Here is the basic ledger:
| Field | Question |
|---|---|
| Decision Point | What decision must be made before the output changes reality? |
| Execution Replaced | What doing became cheaper or faster? |
| Judgment Required | What context, authority, or expertise remains necessary? |
| Error Cost | What happens if the decision is wrong? |
| Review Cost | What does it cost to know whether the output is good enough? |
| Reversibility | Can the decision be undone, and at what cost? |
| Value Capture | Who pays for the outcome, saving, risk reduction, or speed? |
| Moat Potential | Does the workflow improve future advantage through data, trust, distribution, compliance, or learning? |
The ledger is deliberately economic rather than technical. It does not ask first which model to use, which vendor to select, or how many tokens the workflow consumes. Those questions matter later. The first question is where the scarce decision sits.
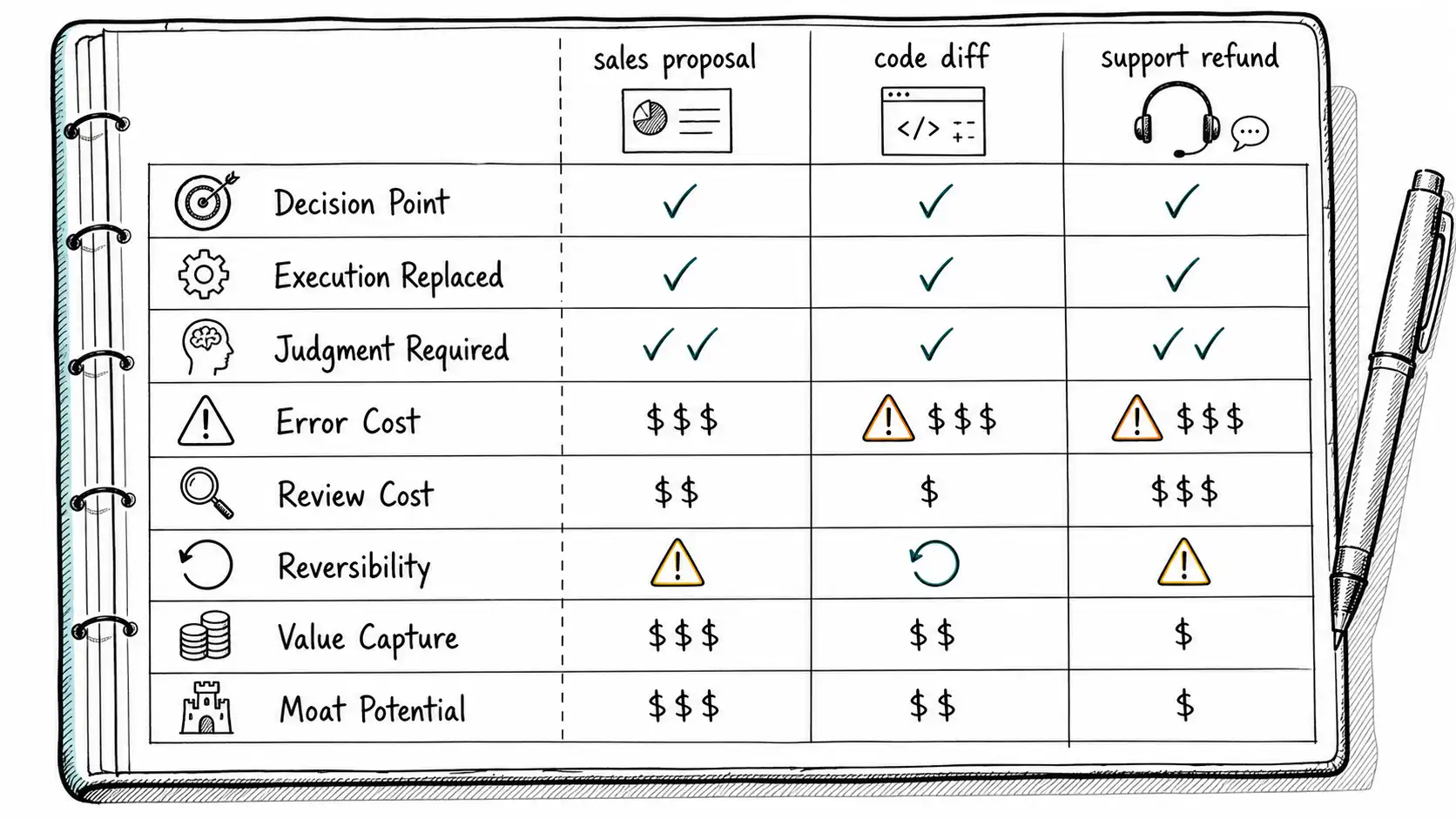
Take an AI sales proposal generator. The naive business case says an account executive used to spend two hours drafting a proposal and now spends twenty minutes, saving one hour and forty minutes. The Judgment Ledger changes the analysis:
| Ledger field | Sales proposal example |
|---|---|
| Decision Point | Should this proposal be sent to this customer with these claims, price terms, and obligations? |
| Execution Replaced | Drafting structure, summarizing discovery notes, inserting product language. |
| Judgment Required | Customer politics, approved claims, pricing strategy, legal terms, competitive context. |
| Error Cost | Discount leakage, legal exposure, broken trust, longer sales cycle. |
| Review Cost | AE review, legal/commercial approval for nonstandard terms, enablement review of claims. |
| Reversibility | Low after customer receives it; corrections look unprofessional. |
| Value Capture | Higher win rate, faster cycle, better expansion, lower sales support cost. |
| Moat Potential | Strong if proposal outcomes feed back into segment-specific messaging and pricing judgment. |
The output is not the proposal. The output is the customer promise. The ledger forces that distinction.
Now take an AI code-generation agent. The naive business case says the tool produces code faster. The Judgment Ledger asks what decision the diff enters:
| Ledger field | Code-generation example |
|---|---|
| Decision Point | Should this machine-authored change enter the maintained system? |
| Execution Replaced | Boilerplate, test scaffolding, migration code, refactor mechanics. |
| Judgment Required | Architecture fit, backward compatibility, security implications, maintainability. |
| Error Cost | Incidents, vulnerabilities, debugging time, long-term complexity. |
| Review Cost | Code review, test execution, threat modeling, staging observation. |
| Reversibility | Medium for isolated features; low for data migrations or public API contracts. |
| Value Capture | Faster delivery, reduced toil, more experiments, lower engineering cost if review does not grow faster. |
| Moat Potential | Strong if code, tests, incident learning, and specs compound into a better internal delivery system. |
This ledger changes how the CTO should buy and deploy coding tools. A tool that generates more code but doubles review cost is not obviously a win. A tool that generates less glamorous scaffolding but improves test coverage, documentation, and spec traceability may have better economics.
Ronald Coase's theory of the firm belongs in this discussion because the firm exists partly to reduce the transaction costs of coordinating work compared with market exchange (https://onlinelibrary.wiley.com/doi/full/10.1111/j.1468-0335.1937.tb00002.x). AI changes internal transaction costs. Drafting, translating, summarizing, and proposing become cheaper. But acceptance, escalation, audit, and responsibility may become more expensive unless redesigned. The boundary of the firm does not change simply because the model can perform a task; it changes when the cost of coordinating and trusting that task changes.
The Judgment Ledger helps leaders see whether AI reduces coordination cost or merely relocates it.
A support automation example is instructive. Suppose an AI assistant drafts responses for billing tickets. On the surface, this is low-risk. It uses policy articles, account state, and a response template. But the ledger reveals several decision points: whether the customer is entitled to a refund, whether the tone should acknowledge prior service failure, whether the ticket indicates churn risk, and whether a policy exception should be escalated. If the AI simply drafts, humans must inspect each response. If the AI is allowed to approve small refunds under clear thresholds, the decision point moves into a policy. If high-value accounts route to customer success, context is added outside the model. The economics depend on workflow design, not the existence of AI.
The ledger has a second use: it reveals where judgment can be scaled. Once the decision point is explicit, the organization can ask what form of judgment should handle it.
Some decisions should remain expert-human. A legal interpretation with high liability and ambiguous language may require counsel. Some should become policy. Refunds under $50 for customers below risk thresholds can be auto-approved. Some should become tests. A generated API change can be checked against schema compatibility and contract tests. Some should become evals. A support response can be evaluated for policy compliance, factual grounding, and tone before a human samples it. Some should become pricing logic. A support resolution that saves measurable human labor may justify outcome-based pricing if attribution is strong enough.
Judgment scaling options:
| Decision shape | Best judgment mechanism |
|---|---|
| High consequence, ambiguous, irreversible | Expert review with evidence packet. |
| Low consequence, repetitive, clear policy | Automated rule or policy-as-code. |
| Behavioral correctness in software | Tests, contracts, properties, staged rollout. |
| Language quality with known criteria | Rubric-based eval plus sampling. |
| Customer-specific tradeoff | Human owner assisted by AI-prepared context. |
| Emerging failure pattern | Incident-to-eval conversion and policy update. |
| Pricing/value capture | Contract metric, usage meter, outcome definition. |
This is how the ledger prevents the false binary of "automate" versus "human in the loop." It asks which decision is being made, what risk it carries, and what judgment mechanism fits.
The ledger also exposes economic leakage. A workflow may save internal execution cost but fail to capture value. Imagine an AI research assistant that helps consultants produce client-ready analysis faster. If the firm bills by hour, the tool reduces billable hours unless pricing changes. If the firm prices by project value, the tool increases margin. If the firm prices by outcome, the tool can support higher upside but also higher accountability. The same operational improvement has different economics depending on value capture.
This is why pricing belongs inside the judgment economy rather than after it. A company that automates work but keeps charging for access may train customers to expect lower prices. A company that automates work and charges for resolved outcomes must prove that outcomes are real, attributable, and risk-adjusted. The pricing model is a judgment artifact because it declares what the company is willing to be accountable for.
The ledger's final field, moat potential, prevents short-term automation from masquerading as durable advantage. Model access alone rarely compounds if every competitor can buy similar capability. What compounds is the workflow's ability to improve future decisions: proprietary data from real usage, review labels, customer context, policy refinement, distribution, trust, compliance certification, and the organizational habit of turning failures into better evals. A company that uses AI to draft more support replies may have no moat. A company that uses support interactions to build the best issue taxonomy, escalation policy, resolution evals, and product feedback loop in its category may have a moat.
The ledger should be filled out before procurement, not after deployment. A practical version for executives:
- Identify the AI workflow.
- Write the decision point in one sentence.
- State the artifact the AI produces.
- State what acceptance means.
- Estimate error cost.
- Estimate review cost.
- Rate reversibility.
- Name the value metric.
- Name the compounding asset.
- Decide whether to automate, assist, gate, sample, or block.
Here is a compact worksheet:
| Workflow | Decision point | Error cost | Review cost | Reversibility | Value metric | Judgment mechanism |
|---|---|---|---|---|---|---|
| Tier-1 support reply | Send answer to customer | Medium | Low/medium | Medium | Resolved case | Auto-send low risk, sample, escalate exceptions |
| Enterprise proposal | Send commercial promise | High | High | Low | Win rate/gross margin | AE + legal review with claim library |
| Code refactor | Merge diff | Medium/high | Medium | Medium | Cycle time without incidents | Tests + reviewer + canary |
| Invoice anomaly | Approve payment | High | Medium | Low | Fraud loss avoided | Rule + human finance approval |
| Product research summary | Influence roadmap | Medium | Low | Medium | Decision quality | PM review + source trace |
The ledger changes leadership conversations. Instead of asking "How many jobs can AI replace?" the company asks "Which execution costs fall, which judgment costs rise, and where do we capture the difference?" Instead of asking "Can the model do this?" the company asks "Can the system accept the model's output safely and profitably?" Instead of asking "What is the automation rate?" the company asks "What is the accepted-outcome rate after review and error cost?"
The ledger is also a political tool. It makes invisible work visible. Reviewers, senior engineers, compliance teams, customer success managers, and product leaders often carry judgment work without having it counted. When AI volume increases, their work becomes the bottleneck. The ledger gives them language to say: generation is not free if acceptance is expensive.
A mature organization can attach ledger fields to actual telemetry. Decision point becomes workflow ID. Execution replaced becomes baseline time. Judgment required becomes review type. Error cost becomes severity class. Review cost becomes minutes and role. Reversibility becomes rollback class. Value capture becomes revenue or savings metric. Moat potential becomes data asset or feedback loop. This turns judgment from philosophy into operations.
The chapter's practical claim is simple: every AI workflow needs a ledger because every AI workflow enters a decision. If you cannot name the decision, you cannot know whether automation created value or merely produced more things to worry about.
Key Takeaways
- The Judgment Ledger is the central worksheet of this book. It exists because most AI business cases count the wrong thing.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Judgment Economy and the adjacent chapters when you need the wider Judgment Economy and AI Strategy frame.
How to use the ledger in an investment review
The ledger is most valuable when used before money is committed. In an investment review, the sponsor should bring a one-page ledger rather than a tool demo. The demo shows possibility; the ledger shows economics. The executive team should challenge every field.
For the decision point, ask whether the wording names a real commitment. "Generate renewal emails" is not a decision point. "Send a renewal email that offers a pricing concession and commits to a support package" is. For execution replaced, ask whether the current human work is truly execution or whether it contains hidden judgment. Many tasks described as "drafting" also include deciding what not to say. For judgment required, ask which facts the model does not naturally have: customer politics, legal status, product roadmap, policy version, brand risk, architectural direction. For error cost, ask for severity classes rather than one average. Average error cost hides the rare event that changes the entire decision.
For review cost, insist on role-specific estimates. Four minutes from a support lead is not the same economic cost as four minutes from a lawyer, security architect, or executive sponsor. For reversibility, ask what rollback actually means. You can retract an internal summary. You cannot easily retract a customer promise, a published financial claim, a shipped migration, or an automated denial. For value capture, ask whether the company captures the value under the current business model. If AI saves customer labor but the vendor charges per seat, the value may leak to the customer in the form of seat reduction. That can be strategically acceptable, but it should be deliberate. For moat potential, ask what proprietary asset exists after the workflow runs for six months. If the answer is "we will have used the model a lot," the moat is weak.
This process turns AI investment from theater into management. It also prevents one of the most common errors: buying a tool because it performs the visible execution step while ignoring the invisible judgment system required around it. A weak ledger does not always mean reject the project. It may mean start with a narrower scope, build evals first, price differently, or redesign review before increasing output.