Labor Markets After Throughput
The lazy version of the labor market argument says AI replaces workers. The equally lazy counterargument says AI only augments workers. Both are too blunt for operators.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The lazy version of the labor-market argument says AI replaces workers. The equally lazy counterargument says AI only augments workers. Both are too blunt for operators.
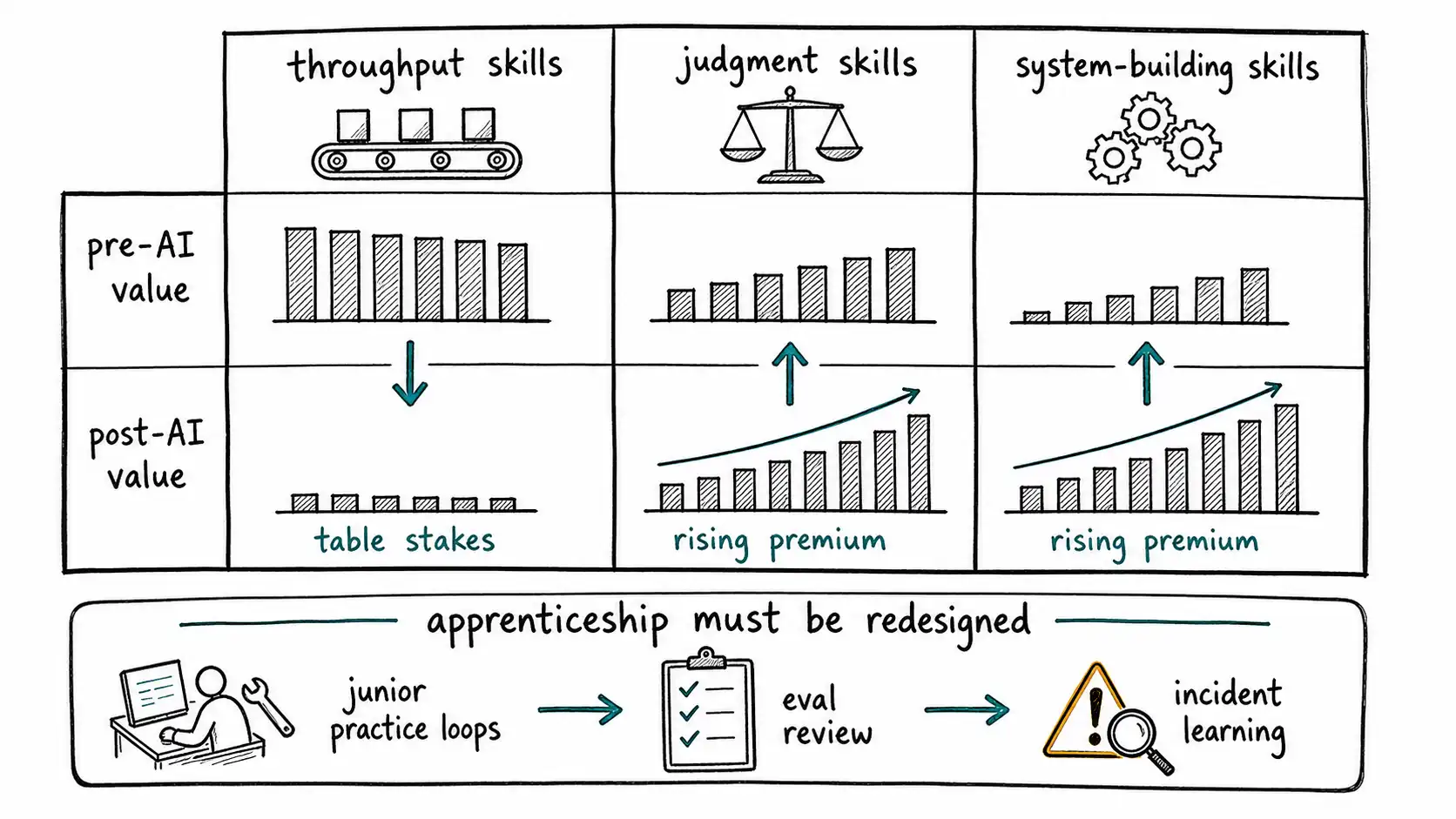
AI changes task bundles. Some tasks become cheaper, some become more valuable, some become exposed to review bottlenecks, and some become necessary but less visible. The labor market then prices roles according to the remaining scarcity, not according to old job titles. The judgment economy is therefore a seniority and apprenticeship problem as much as a headcount problem.
A support agent used to write answers, search policy, calm customers, recognize edge cases, and escalate. An AI assistant may draft answers and retrieve policy. That does not remove the agent's value evenly. It reduces the value of routine phrasing, increases the value of recognizing when the drafted answer is wrong, and changes the training path for new agents. If novices no longer write many answers from scratch, how do they learn the judgment that experienced agents use to catch subtle errors?
The NBER customer-support study is useful again, but not as a slogan. It found the biggest gains among novice and lower-skilled agents, suggesting that generative AI can diffuse aspects of tacit knowledge from stronger workers into assistance for less experienced workers (https://www.nber.org/papers/w31161). That is powerful. It means AI can compress some learning curves. But compression is not replacement of expertise. The same study's heterogeneity implies that organizations must ask which parts of expert performance were captured by the tool and which remain outside it.
The labor-market shift can be described with four task categories:
| Task category | AI effect | Human value moves toward |
|---|---|---|
| Routine production | Strong substitution | Supervising quality and exceptions |
| Structured analysis | Partial automation | Framing questions and interpreting caveats |
| Creative drafting | Abundant first drafts | Taste, positioning, audience fit |
| High-stakes decision | Assistance but not full delegation | Accountability, risk, context, authority |
| Tacit coordination | Weak substitution | Relationship, local knowledge, negotiation |
| Learning/apprenticeship | Disrupted | Designed practice, review, mentorship |
The last row is the hidden issue. Organizations learned to train judgment through doing. Junior lawyers reviewed documents. Junior engineers fixed bugs. Junior analysts prepared models. Support agents handled repetitive tickets. Sales reps wrote follow-ups. Much of that work was inefficient, but it exposed people to examples, errors, and feedback. If AI performs the routine work, the company must design new apprenticeship loops or accept a future shortage of judgment.
This is already visible in engineering. A coding assistant can help produce code faster, but if junior engineers skip the struggle of tracing failure, reading existing systems, and debugging unclear requirements, they may not develop architectural judgment. DORA's AI-assisted software development work warns that returns depend on the organizational system, not tool adoption alone (https://dora.dev/dora-report-2025/). Training, review culture, documentation, and feedback loops matter more when AI changes who touches which parts of the work.
Labor value therefore migrates, but not always upward in title. Some junior roles become more productive and more strategically important because AI lets them handle work previously reserved for experienced staff. Some mid-level throughput roles become squeezed because the machine can perform the visible production while senior people retain acceptance authority. Some senior roles become bottlenecks because every AI output routes to them. Some new roles appear around evals, workflow design, AI operations, policy, and customer trust.
A labor value migration table:
| Old value signal | New risk | New value signal |
|---|---|---|
| Number of artifacts produced | Output inflation | Accepted outcomes improved |
| Speed of completion | Fast wrong work | Quality-adjusted cycle time |
| Fluency in tools | Tool commoditization | Ability to select and govern tools |
| Individual productivity | Review bottleneck | System throughput after judgment |
| Seniority by tenure | Rubber-stamp authority | Calibrated decision quality |
| Junior learning by repetition | Apprenticeship collapse | Designed exposure to edge cases |
| Manager activity tracking | Measurement theater | Decision-right clarity and outcome ownership |
The economics of seniority change in a subtle way. Senior people may become more valuable because they own judgment. They may also become overwhelmed if the organization routes too much review to them. A senior engineer reviewing ten human-authored PRs per week might handle the load. The same engineer reviewing forty AI-authored PRs may become the constraint. If the organization celebrates generated diffs but not review capacity, senior talent becomes the scarce factory machine.
The solution is not to hire only seniors. That is impossible and economically foolish. The solution is to split judgment into layers. Some acceptance can be encoded in tests. Some can be delegated with rubrics. Some can be handled by trained mid-level reviewers. Some can be sampled. Some must go to senior experts. The labor design problem is to create a judgment ladder, not a flat senior-review wall.
Hiring changes accordingly. Companies should not ask only, "Can this person use AI tools?" That skill becomes baseline quickly. They should ask:
- Can this person define acceptance criteria before generation?
- Can they notice when output is plausible but wrong?
- Can they reason about consequence and reversibility?
- Can they turn repeated review findings into policy, tests, or evals?
- Can they communicate uncertainty to customers and executives?
- Can they improve the system rather than only consume it?
For product managers, the premium moves from ticket throughput to specification judgment and outcome selection. For engineers, from typing implementation to architecture, debugging, tests, and review of machine-authored changes. For designers, from producing variations to taste, user research interpretation, and interaction judgment. For sales, from writing personalized emails to account strategy and commercial promise discipline. For finance, from generating scenarios to deciding which assumptions are board-defensible. For legal, from summarizing documents to risk interpretation and clause precedence. For operations, from moving tickets to designing queues, escalation, and measurement.
This creates a different hiring rubric:
| Dimension | Weak signal | Strong signal |
|---|---|---|
| Tool use | "Uses ChatGPT/Copilot daily" | Can explain when not to use it and how to verify outputs |
| Judgment | Has opinions | Makes decisions with criteria, consequences, and evidence |
| Systems thinking | Automates personal tasks | Designs workflow, gates, metrics, and escalation |
| Learning | Consumes AI output | Converts failures into reusable examples and tests |
| Collaboration | Works faster alone | Improves team acceptance quality |
| Commerciality | Saves time | Connects work to margin, risk, trust, or revenue |
The labor market will also create new compensation asymmetries. People who can generate output may face price pressure. People who can own ambiguous decisions may command premiums. But the premium is not for being "strategic" in the abstract. It is for reducing the organization's cost of acceptance. A great AI-native operator can look at a workflow, identify the decision points, tier the risks, build the review system, and connect the output to value capture. That person creates use across many machine workers.
There is also a class implication inside companies. If AI removes low-risk practice work, junior workers may get fewer chances to build judgment. The organization then complains that juniors lack judgment while removing the work that would have taught it. This is a management failure, not a generational flaw. The company must create practice loops deliberately: shadow review, eval labeling, incident reconstruction, edge-case libraries, synthetic scenarios, paired critique, and graduated decision rights.
A designed apprenticeship loop for AI-native work:
- Junior reviews AI output against a rubric.
- Senior reviews the junior's review, not only the AI output.
- Disagreements are logged with rationale.
- Repeated errors become examples in the rubric.
- The junior earns authority for lower-risk decisions.
- The eval suite absorbs stable patterns.
- Senior attention moves to harder cases.
This loop produces judgment instead of merely consuming it.
The same principle applies to management. A manager who uses AI to generate more plans must still decide priorities. If every team now has ten plausible initiatives, portfolio judgment becomes scarce. The manager's value moves from requesting plans to refusing work. AI makes saying yes cheaper. It makes saying no more important.
The chapter's uncomfortable message is that productivity gains can make organizations worse if they devalue the labor that turns output into trusted action. The companies that win will not simply reduce headcount against generated work. They will redesign roles around judgment, protect apprenticeship, and measure accepted outcomes. The human role contracts, but the remaining role is not smaller in responsibility. It is denser.
Key Takeaways
- Labor Markets After Throughput names the operating decision a team has to make before it accepts the work.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Judgment Economy and the adjacent chapters when you need the wider Judgment Economy and AI Strategy frame.
Protecting apprenticeship when the machine does the practice work
A company serious about AI-native labor design should inventory not only tasks but learning pathways. Ask: which repetitive tasks taught people the domain? Which low-risk decisions prepared people for high-risk decisions? Which reviews helped juniors learn quality? Which mistakes were safe enough to be educational? If those tasks are automated, what replaces their learning function?
One replacement is curated review. Juniors can review AI outputs against rubrics, then compare their judgments to senior reviewers. This can be more educational than doing the original task because it exposes them to many examples quickly. But it works only if disagreement is discussed and rationales are captured. Silent approval teaches little.
Another replacement is incident reconstruction. When an AI output fails, juniors should participate in tracing why: missing context, bad retrieval, ambiguous spec, weak policy, inadequate test, reviewer fatigue. This teaches system judgment. It also prevents the old apprenticeship model from shrinking into prompt operation.
A third replacement is graduated autonomy. Give juniors authority over low-risk decisions with clear rollback, then increase scope as calibration improves. Track not only speed but decision quality. The goal is not to keep humans busy with work the machine can do. The goal is to preserve the developmental path into accountable judgment.
This has compensation implications. Organizations may need fewer people whose primary value is routine artifact production, but they will need more people who can teach, calibrate, review, and systematize judgment. Those activities often looked like overhead in old productivity accounting. In an AI-native labor market, they are capacity-building. A company that cuts them too aggressively may enjoy short-term margin and then discover that no one is ready to own the next tier of decisions.
A final labor-market implication is that managers must stop using activity as a proxy for development. In an AI-native team, a junior person may produce impressive artifacts before they understand the domain. That can deceive both the manager and the employee. Development plans should therefore include calibrated judgment milestones: can the person correctly reject bad AI output, explain why a generated answer fails policy, identify missing context, choose an escalation path, and update the system after a failure? These are observable skills. They can be reviewed and coached.
The most valuable workers will combine three capacities: domain judgment, AI fluency, and operating-system thinking. Domain judgment knows what matters. AI fluency knows what the machine can and cannot do. Operating-system thinking turns individual judgment into repeatable workflow: policies, tests, examples, dashboards, and escalation paths. A person with only AI fluency may produce volume. A person with only domain judgment may become a bottleneck. A person with only operating-system thinking may build elegant gates around the wrong work. The premium goes to the combination.
This also changes performance management. A quarterly review that asks only how much a person shipped will over-reward AI-assisted volume and under-reward the quieter work of preventing bad acceptance. Managers should ask for examples of judgment: a generated output rejected for the right reason, a rubric improved, an eval added, a risky automation narrowed, a junior reviewer calibrated, a customer promise corrected before it was sent. Those examples are not soft evidence. They are the evidence that the employee is increasing the organization's acceptance capacity.