Judgment Is the Scarce Input
This chapter turns judgment is the scarce input into a concrete operating problem for the judgment economy book.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. Judgment is an abused word. It gets used to mean taste, experience, wisdom, management instinct, executive courage, risk appetite, and sometimes nothing more than "I disagree but do not have a spreadsheet yet." For this book, judgment needs a stricter definition.
Judgment is the accountable selection of action under incomplete information.
That definition has four load-bearing pieces. Selection means alternatives exist. Action means something changes in the world. Incomplete information means the answer is not fully determined by available data. Accountable means someone or some system bears the consequence. If all four are absent, judgment is not the scarce input. If a rule can be applied with complete information and no meaningful consequence, automate it. If an output can be accepted without tradeoff, accept it. If the answer is available from a deterministic calculation, calculate it. But when the organization must choose under uncertainty, judgment appears.
This is why the judgment economy is not a romantic defense of human intuition. It is an economic claim about scarcity. AI makes many acts of production cheaper: draft the response, summarize the transcript, produce the test, generate the campaign, propose the query, build the UI, write the migration script. But every production step that used to implicitly include human interpretation can split into two pieces: machine doing and human or institutional deciding. The doing gets cheaper. The deciding becomes visible.
Frank Knight's old distinction between risk and uncertainty is useful here because it separates measurable probability from situations where the probability structure itself is uncertain. In Risk, Uncertainty and Profit, Knight argued that profit is tied to uncertainty-bearing rather than routine calculation. The book is old, but the distinction is newly operational: AI can help calculate known risks, draft scenarios, and analyze evidence; it does not remove the need to own uncertain commitments (https://oll.libertyfund.org/title/knight-risk-uncertainty-and-profit). A model can estimate churn. A leader still decides whether to offer a concession that changes the customer relationship. A model can summarize a contract. Counsel still decides whether the residual ambiguity is acceptable. A model can generate code. The engineering organization still decides whether the design belongs in the system.
Herbert Simon's bounded rationality adds a second constraint. Real organizations do not optimize over perfect information; they satisfice under limits of attention, computation, and time. In AI-native organizations, the bounded resource is often not information volume but evaluative attention. The model can produce more alternatives than the organization can inspect. More options do not automatically improve choice when the review system is weak. They can overload the chooser.
This is the paradox: AI expands the option set while making the choice problem harder.
The best way to see judgment economically is to map where it hides. It is rarely a single executive moment. It appears in product specs, pricing exceptions, triage policies, code review comments, customer escalation rules, compliance attestations, labeling rubrics, sales qualification, roadmap prioritization, and incident response. Judgment lives wherever the organization decides that one version of reality should become the version it acts on.
A sales team deciding which generated proposal to send is exercising judgment. A support system deciding whether a refund should be auto-approved is exercising judgment. A product manager deciding whether a generated prototype matches the intended customer job is exercising judgment. A security engineer deciding whether an AI-generated patch reduces risk or introduces a bypass is exercising judgment. An eval suite deciding that a model output fails a policy test is institutionalized judgment.
That last phrase matters. Judgment is not only in humans. It can be encoded into policy, tests, thresholds, workflows, contracts, and pricing. The point of the judgment economy is not that humans manually approve everything. That would be a bottleneck, not an economy. The point is that valuable organizations learn which judgment should remain human, which should be encoded, which should be sampled, and which should be delegated.
A useful taxonomy:
| Judgment type | Human form | System form | Failure if absent |
|---|---|---|---|
| Intent judgment | "What are we trying to achieve?" | Strategy docs, outcome specs, roadmap principles | The machine optimizes the wrong target. |
| Acceptance judgment | "Is this good enough to use?" | Tests, evals, review rubrics, gates | Polished wrong work ships. |
| Risk judgment | "What harm can we tolerate?" | Risk tiers, policy-as-code, escalation rules | Low-risk and high-risk work receive the same treatment. |
| Context judgment | "What local fact changes the answer?" | Metadata, customer state, permissions, source authority | Generic output ignores reality. |
| Economic judgment | "Who pays for this value?" | Pricing metrics, contracts, usage meters | Value is created but not captured. |
| Learning judgment | "What should change after this?" | Feedback loops, incident-to-eval pipelines, training data | The system repeats expensive mistakes. |
The taxonomy reveals why judgment becomes scarce. It is not one skill. It is a set of institutional capacities. A company can have strong context judgment in customer support and weak acceptance judgment in engineering. It can price well but evaluate poorly. It can have rigorous compliance review but poor product taste. AI exposes these uneven capacities because the machine can generate candidate outputs across every function faster than the organization can decide what should happen to them.
The classic labor economics literature on computerization helps prevent overclaiming. Autor, Levy, and Murnane argued that computers substitute for routine tasks that can be described by explicit rules and complement nonroutine problem-solving and complex communication (https://economics.mit.edu/sites/default/files/publications/the%20skill%20content%202003.pdf). Generative AI shifts the boundary because it can perform some tasks that look nonroutine on the surface: drafting, summarizing, coding, classifying. But the broader lesson remains: tasks decompose. Occupations are bundles. The value of a role changes depending on which tasks become cheaper and which tasks become more important around them.
Brynjolfsson, Mitchell, and Rock made a similar point for machine learning: few occupations are fully automatable, and realizing ML's potential typically requires redesigning task content rather than simply replacing workers one-to-one (https://www.aeaweb.org/articles?id=10.1257/pandp.20181019). That is a crucial caution. The judgment economy is not "everyone becomes a manager." It is "the task bundle changes, and the high-value tasks concentrate around decision quality."
The practical implication for leaders is uncomfortable. If judgment is scarce, then many organizations have been underinvesting in the very capacity they now need most. They hired for throughput, staffed for tickets, promoted for heroic execution, and measured activity because activity was visible. They treated review, specification, architecture, risk assessment, customer promise discipline, and pricing design as overhead. AI does not make those overhead functions less important. It turns them into production constraints.
A founder might say, "But our model can make decisions." Sometimes that is true in a narrow domain. Fraud scoring, loan underwriting, ad bidding, routing, and recommendation systems already make or influence decisions at scale. But those systems are valuable when decision boundaries, training signals, thresholds, feedback loops, and accountability are engineered. The decision is not magically removed from the company. It is relocated into data selection, objective design, monitoring, policy, and escalation. A model that decides without an accountable judgment system is not autonomy. It is unowned risk.
The phrase "human judgment" can also mislead. A human can rubber-stamp. A committee can diffuse responsibility. A senior expert can be wrong. A reviewer without context is a decorative control. In the judgment economy, what matters is not that a person touched the output; it is that the system routed the decision to the right judgment mechanism with enough evidence and authority to make the decision meaningful.
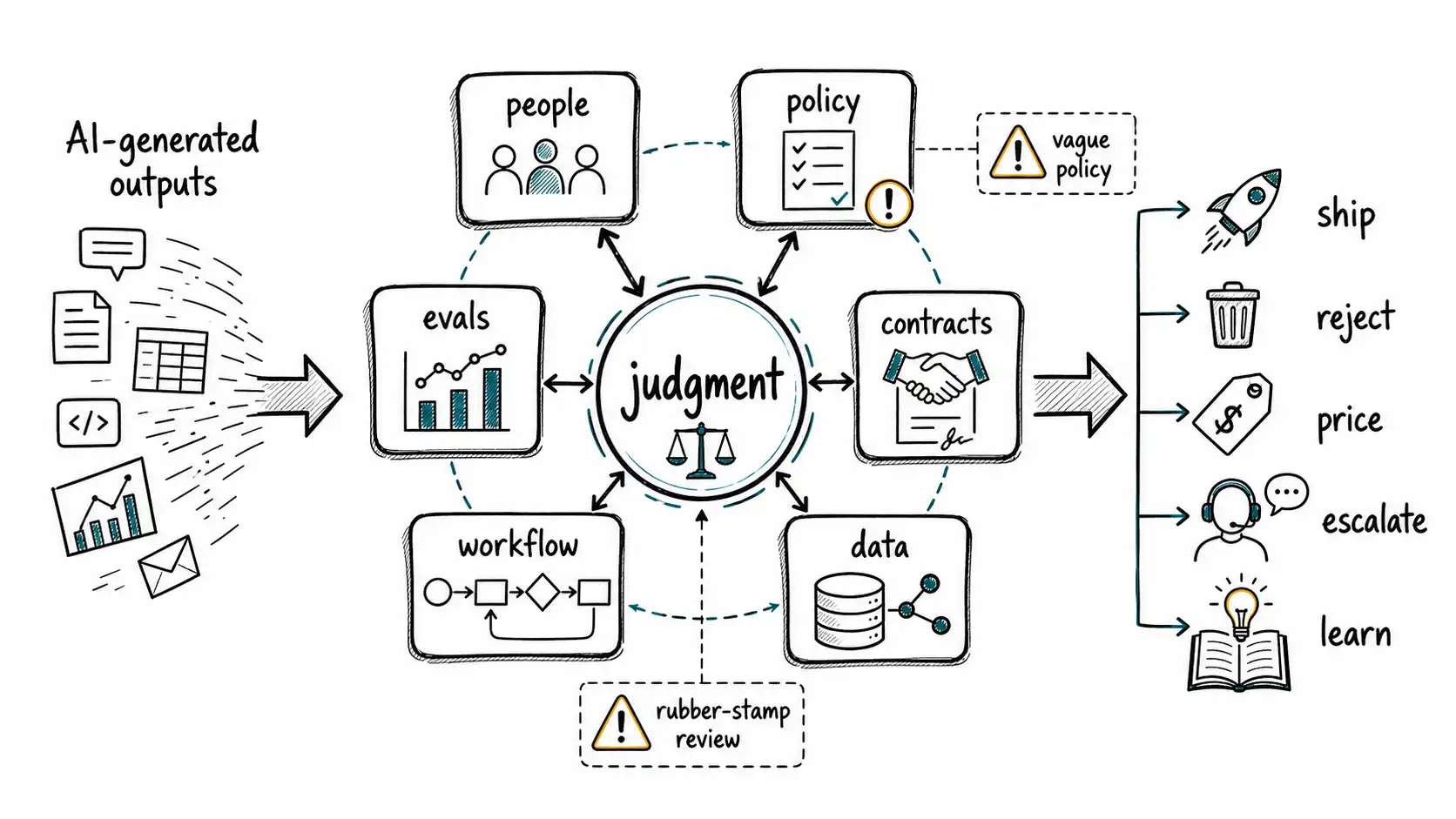
Judgment has four properties that make it scarce.
First, it requires context. Context is not merely more tokens. It is the local, institutional, historical, and relational knowledge that changes what a correct answer means. A generated support response might be technically correct and commercially wrong if the customer is in renewal. A generated code change might pass tests and violate an architectural direction that has not been written down. A generated financial summary might be accurate and still inappropriate to share with a board member because of disclosure timing.
Second, judgment requires consequence awareness. The person or system making the decision must understand what happens if the decision is wrong. A junior analyst can produce a revenue scenario. A CFO must know how the scenario will influence hiring, cash planning, investor communication, and covenant risk. The difference is not intelligence; it is consequence coupling.
Third, judgment requires tradeoff literacy. Most important decisions are not between good and bad. They are between speed and confidence, margin and growth, automation and customer trust, consistency and flexibility, legal conservatism and sales velocity, user delight and operational complexity. AI can list tradeoffs. Judgment chooses which tradeoff the organization will own.
Fourth, judgment requires decision rights. A person can have expertise without authority. A team can have authority without expertise. The productive organization aligns both. The AI-native organization must be especially explicit because machine output creates many plausible opportunities to act. If no one has the right to accept, reject, override, or escalate, generated work accumulates.
A judgment-scarcity scorecard can help diagnose workflows:
| Question | Low scarcity | High scarcity |
|---|---|---|
| Is the decision reversible? | Easy rollback; low customer impact. | Hard to undo; creates commitments. |
| Is quality directly measurable? | Immediate objective signal. | Delayed, subjective, or contested signal. |
| Is context stable? | Same rule across cases. | Customer, domain, legal, or strategic context changes the answer. |
| Is error cost bounded? | Small, local, recoverable. | Expensive, reputational, regulatory, or compounding. |
| Are decision rights clear? | Owner and escalation path known. | Many stakeholders, unclear authority. |
| Can acceptance be encoded? | Tests/rules cover most cases. | Rubric and expert review required. |
The higher the scarcity score, the less the organization should rely on output volume as success. It should invest instead in specifications, evaluation, policy, review design, and pricing discipline. Low-scarcity workflows can be automated aggressively. High-scarcity workflows can still use AI, but the AI should expand the judgment system rather than bypass it.
The best mental model is that AI lowers the cost of candidate action. Judgment determines which candidate action becomes real. Candidate action has option value. Accepted action has consequence. The judgment economy is the study of what happens when option generation becomes abundant and consequence ownership remains scarce.
The chapter's takeaway is not "humans are irreplaceable." That is too comforting and too vague. The sharper claim is: accountability under uncertainty has economic value. Organizations that can route, encode, price, and improve that accountability will outperform organizations that merely generate more artifacts.
Key Takeaways
- This chapter turns judgment is the scarce input into a concrete operating problem for the judgment economy book.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Judgment Economy and the adjacent chapters when you need the wider Judgment Economy and AI Strategy frame.
The difference between expertise and authority
Judgment also requires separating expertise from authority. Expertise answers, "What is probably true?" Authority answers, "What will we do?" In slow organizations, these collapse into politics: the most senior person decides even when the expert knows more, or the expert is blamed for a decision they had no authority to make. AI can worsen this because it produces expert-looking output without authority and sometimes without expertise. The organization must decide who owns the last mile.
A machine-generated risk analysis might be useful expertise-like input. It does not have authority to accept the risk. A model-generated architecture option might summarize tradeoffs. It does not decide the system's long-term shape. A customer-health prediction might identify churn risk. It does not decide whether to discount, escalate, renew, or walk away. Treating AI output as expertise can be productive. Treating it as authority without governance is dangerous.
A mature judgment system makes authority legible. It says: this class of decision can be automated because policy is clear and error cost is bounded; this class requires human review because context is variable; this class requires named executive sign-off because the decision creates a durable commitment. This is not bureaucracy when designed well. It is a routing table for scarce judgment.
The routing table should be visible to the people using the AI system. A support agent should know why one refund was auto-approved and another was escalated. An engineer should know why a generated refactor can be merged after tests but a schema migration requires data-platform review. A salesperson should know which proposal claims are approved, which require legal, and which are forbidden. Visibility prevents both overtrust and learned helplessness. People can cooperate with automation when they understand where their judgment is still expected.
The final distinction is between judgment and preference. A preference says what someone likes. Judgment explains what should be chosen given context, constraints, consequences, and accountability. AI-native organizations should train people to make their judgment inspectable: state the criteria, cite the evidence, name the risk, and describe the alternative rejected. That habit turns individual judgment into organizational learning. Without it, the company remains dependent on private intuition, and private intuition does not scale.