Pricing Work, Not Access
Traditional SaaS pricing assumes software gives humans access to capability. Users log in.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. Traditional SaaS pricing assumes software gives humans access to capability. Users log in. Users do the work. The vendor charges per seat, tier, feature bundle, usage unit, or enterprise contract. The logic is not perfect, but it is familiar: more users and more usage suggest more value.
AI-native software complicates that logic because the software increasingly performs work. It drafts the email, resolves the ticket, classifies the invoice, writes the test, extracts the clause, reconciles the record, books the meeting, prioritizes the queue, or recommends the action. When software does work, customers start asking a different question: why am I paying for access rather than outcome?
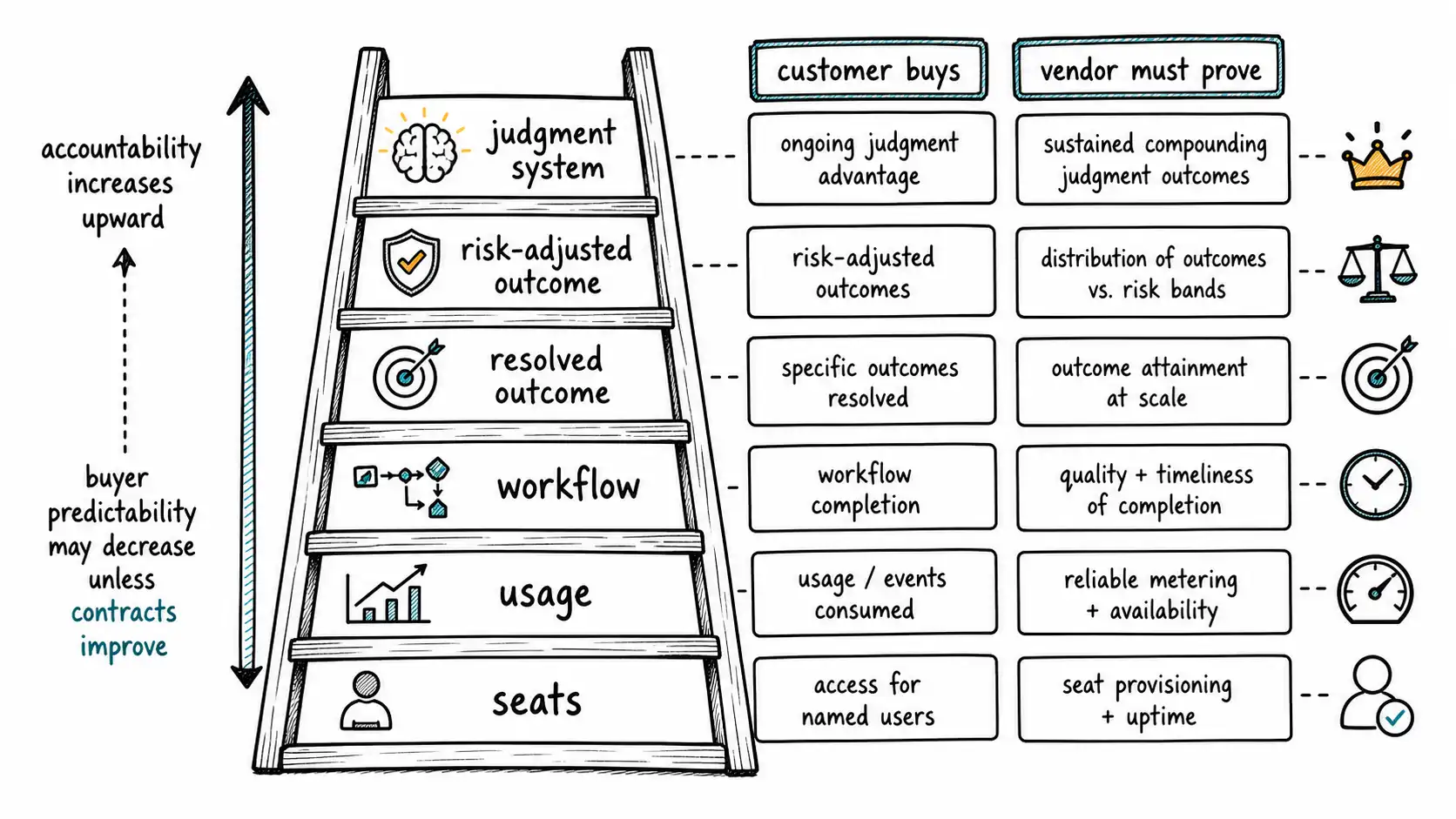
This does not mean every AI company should use outcome pricing. It means every AI company must justify its pricing metric against the unit of value. Seat pricing can still work when human users remain the primary locus of value. Usage pricing can work when consumption correlates with value and is predictable enough for buyers to control. Workflow pricing can work when the product owns a process. Outcome pricing can work when attribution, risk sharing, and trust are strong. Judgment pricing can work when customers pay for a decision they can rely on.
The shift is visible in contemporary pricing discussions. Stripe's pricing materials describe usage-based pricing as charging according to consumption rather than a flat subscription, and they emphasize the importance of choosing a value metric customers can understand and control (https://stripe.com/resources/more/usage-based-pricing-for-saas-how-to-make-the-most-of-this-pricing-model). Bessemer's AI pricing playbook argues that AI products increasingly resemble productive teammates and that pricing is moving from access toward work and outcomes (https://www.bvp.com/atlas/the-ai-pricing-and-monetization-playbook). Those are market observations, not laws. The judgment economy adds the operating reason: customers pay when machine output becomes accepted, valuable, and accountable work.
A pricing ladder:
| Pricing model | Customer buys | Best when | Main risk |
|---|---|---|---|
| Seat | Access for users | Human remains central worker; value scales with seats | AI reduces seats and compresses expansion path |
| Usage | Consumption units | Usage correlates with value; cost scales with usage | Buyer fears unpredictability; usage may not equal outcome |
| Workflow | A process capability | Vendor owns a recurring workflow | Must prove workflow adoption and integration depth |
| Resolved outcome | Completed work | Outcome is measurable and attributable | Disputes over causality, quality, and exceptions |
| Risk-adjusted outcome | Accountable decision or result | High-value domain with strong trust and governance | Vendor assumes meaningful liability or performance risk |
| Judgment system | Improved decision quality | Customer values acceptance, control, audit, learning | Harder to explain; requires executive buyer |
Most AI pricing failures happen when the model is on one rung and the value is on another. A support assistant priced per seat may be underpriced if it resolves thousands of cases with fewer agents. It may be overpriced if agents still review every answer and resolution does not improve. A coding assistant priced per developer may work for broad adoption, but if the tool becomes an autonomous agent that completes backlog items, buyers may compare it to contractor capacity or accepted PRs. A legal AI tool priced by document count may not capture value if the real value is risk-reduced review by counsel.
Pricing is not only monetization. It is a claim about accountability.
If you charge for access, you are saying: the customer owns the work. If you charge for usage, you are saying: the customer owns the outcome, but consumption is a fair proxy. If you charge for resolved outcomes, you are saying: the product's work can be measured and trusted. If you charge for risk-adjusted outcomes, you are saying: the vendor shares responsibility. The stronger the pricing claim, the stronger the evaluation, evidence, governance, and contract design must be.
A calculation shows the difference.
Suppose an AI support product helps a company resolve billing tickets. The vendor considers three pricing models:
Customer baseline:
Agents = 40
Loaded cost per agent = $85,000/year
Tickets per month = 80,000
Baseline resolution rate = 72%
Average fully loaded cost per human-handled ticket = $3.50
Estimated value per resolved ticket = $6.00 in saved cost and retention impact
AI system COGS per ticket touched = $0.18
Implementation/support cost = $25,000/monthSeat pricing:
40 seats * $120/month = $4,800/month
Vendor captures small value regardless of automation impact.
Customer may reduce seats, shrinking expansion.Usage pricing:
80,000 tickets * $0.12 = $9,600/month
Vendor revenue scales with volume.
Customer asks whether ticket touches equal value.Resolved outcome pricing:
Incremental resolved tickets:
AI-assisted resolution rate = 79%
Incremental resolutions = 80,000 * 7% = 5,600
Price per incremental resolution = $1.50
Revenue = $8,400/monthWorkflow pricing:
Base platform = $20,000/month
Included tickets = 60,000
Overage = $0.08 per ticket beyond included
Revenue = $21,600/monthRisk-adjusted pricing:
Vendor charges $1.25 per verified resolution plus SLA credits for policy violations.
Revenue depends on evaluation and dispute rules.
Higher trust, higher operational burden.The "best" model depends on value proof, buyer preference, gross margin, and trust. Outcome pricing sounds attractive, but if attribution is weak, it becomes a dispute engine. Seat pricing sounds old-fashioned, but if the product is a copilot used by many humans across varied tasks, it may remain practical. Hybrid models are often necessary because enterprise buyers want predictability while vendors need upside.
The judgment economy reframes pricing around accepted work. A pricing metric should pass five tests:
- Value correlation: Does the metric rise when customer value rises?
- Customer controllability: Can the customer understand and influence the metric?
- Cost alignment: Does the metric cover variable AI and support cost?
- Quality protection: Does the metric discourage low-quality volume inflation?
- Dispute resilience: Can both parties agree when value occurred?
"Tokens consumed" often fails value correlation. "AI actions taken" may fail quality protection. "Tickets deflected" can fail customer value if deflection means users gave up. "Resolved tickets" is better but requires a definition of resolution. "Qualified meetings booked" is better than emails sent but requires qualification criteria. "Accepted pull requests" is better than generated lines of code but requires review and incident adjustment.
A practical value-capture matrix:
| Workflow | Bad metric | Better metric | Judgment needed |
|---|---|---|---|
| Support automation | Replies generated | Verified resolutions without reopen | Resolution definition, sampling, escalation |
| Sales outreach | Emails sent | Qualified opportunities influenced | Attribution, ICP fit, message approval |
| Legal review | Pages summarized | Issues correctly identified and reviewed | Counsel rubric, risk class, source evidence |
| Coding agent | Lines generated | Accepted changes without regression | Test suite, code review, incident monitoring |
| Analytics assistant | Reports generated | Decisions improved or analyst time saved | Definition authority, decision trace |
| Recruiting screen | Candidates ranked | Qualified candidates fairly advanced | Bias audit, role criteria, human override |
Pricing should not reward the bad metric. If it does, the product will be tuned toward economic noise.
The pricing conversation also exposes who owns judgment. In a seat model, judgment remains with the customer's users. In a workflow model, judgment is shared between product design and customer configuration. In an outcome model, judgment must be contractually specified: what counts as a resolution, a qualified lead, a valid claim, an accepted task, a successful intervention. The vendor cannot simply say "AI did work." It must define the work as the customer experiences it.
This creates opportunity for companies that build governance and evaluation as product features. A vendor that can show traceable evidence, acceptance rates, error categories, review outcomes, and ROI by risk tier can sell on trust. A vendor that cannot will be pushed toward cheaper access pricing because customers will not pay outcome prices for unverified claims.
Outcome pricing has three hard problems.
First is attribution. Did the AI cause the outcome, or would it have happened anyway? A support case might have resolved with a human agent. A sales opportunity might have advanced because of an existing relationship. A coding task might have been completed by the engineer without the tool. Without a credible baseline, outcome pricing becomes negotiation theater.
Second is quality. An outcome can be counted and still be bad. A "resolved" ticket that causes a customer to churn is not resolved economically. A "booked meeting" with a poor-fit prospect wastes sales time. A "merged PR" that creates maintenance debt is not pure value. The metric must include quality adjustment.
Third is risk allocation. If the vendor charges for outcomes, the buyer may expect the vendor to absorb failure risk. That can be good business in domains where the vendor has strong control and evidence. It can be catastrophic if the vendor depends on messy customer data, weak processes, or human behavior outside its control.
This is why many AI products will land on hybrid pricing: base platform fee for access and trust infrastructure, usage for variable cost, and success fee for measurable incremental outcomes. Hybrid pricing is less elegant than a pure outcome story, but enterprise economics often prefer controlled complexity over beautiful fragility.
A simple hybrid example:
Base platform fee: $30,000/month
Included volume: 100,000 workflow events
Usage overage: $0.05/event
Verified outcome fee: $0.75/resolution above baseline
Quality guardrail: no outcome fee for cases reopened within 14 days
Risk credit: service credit for policy-violating automated responses above thresholdThis design charges for platform value, covers usage, captures upside, and protects against low-quality volume. It requires measurement. That is the point.
The chapter's warning is that AI companies can destroy their own pricing power by selling generated work too cheaply. If the product is positioned as "draft more faster," the buyer compares it to cheap labor and model access. If the product is positioned as "make this workflow produce accepted, auditable, value-bearing outcomes," the buyer compares it to operational results. The second position requires more product discipline but creates better economics.
Pricing software that thinks is not just about billing. It is about deciding which work the company is willing to stand behind. In the judgment economy, price is a map of responsibility.
Key Takeaways
- Traditional SaaS pricing assumes software gives humans access to capability. Users log in.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Judgment Economy and the adjacent chapters when you need the wider Judgment Economy and AI Strategy frame.
The buyer's fear of unpredictable intelligence
AI pricing fails when it ignores buyer anxiety. Buyers do not merely ask, "What is the value?" They ask, "Can I predict the bill, defend the purchase, control usage, prove ROI, and avoid paying for bad output?" Usage and outcome pricing are attractive to vendors because they capture upside. They can be frightening to customers because the product's behavior is probabilistic and the cost of usage may be harder to forecast than seat count.
This is why pricing architecture needs controls. A usage-priced AI product should include budgets, alerts, caps, tiered model policies, and reporting by workflow. An outcome-priced product should include definitions, exclusions, dispute mechanisms, quality guardrails, and baseline methodology. A risk-adjusted product should include liability boundaries. Without these, the pricing model can become a source of distrust even when the product works.
Good pricing also distinguishes between customer-visible value and vendor-incurred cost. Tokens, GPU time, and model calls matter to gross margin, but customers rarely want to buy them directly unless they are technical buyers building infrastructure. A customer-support VP does not want to buy tokens; they want resolved cases, lower reopen rates, faster time to resolution, and better customer satisfaction. A CFO does not want to buy generations; they want close process speed, fewer errors, and defensible numbers. The vendor must translate internal cost metrics into buyer value metrics without losing cost discipline.
The practical compromise is often a pricing stack: platform fee for access and trust infrastructure, usage fee for variable cost, and outcome component for measurable incremental value. The stack should be simple enough to sell and precise enough to protect margin. It should also create the right product incentives. If pricing rewards volume alone, product teams will optimize for volume. If pricing rewards verified outcomes with quality guardrails, product teams will build evals, review loops, and evidence.