Review Cost Is Production Cost
The most dangerous number in an AI automation business case is the cost per generated output.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The most dangerous number in an AI automation business case is the cost per generated output.
It is attractive because it is easy to calculate. A model call costs a few cents. A human task costs several dollars. The difference looks like margin. A slide appears: "AI reduces task cost by 98%." The room feels rational. The procurement request is approved.
Then review arrives.
Review is not a side activity. In AI-native work, review is often the new production cost. When the machine can generate an output cheaply, the expensive question becomes whether the output is good enough to accept. That cost includes human time, tooling, tests, eval runs, sampling, escalation, rework, incident handling, customer trust loss, and governance evidence. If the business case ignores review, it is not a business case. It is a token invoice.
Let us build a simple calculation. A company generates weekly renewal-risk summaries for customer success managers. Before AI, a CSM wrote 300 summaries per week across the team. Each took 25 minutes. After AI, the system can generate 5,000 summaries per week at a model cost of $0.04 each. The CFO sees $200 of generation cost for work that previously required 2,083 human hours monthly. That looks miraculous.
But the system is only useful if summaries are reviewed or routed appropriately.
Assume:
Generated summaries per week = 5,000
CSM review capacity = 1,200 summaries per week
Average review time = 4 minutes
Serious error rate before review = 3%
Serious errors caught in review = 80%
Cost per serious accepted error = $3,500
Value per accurate accepted summary = $45
Model cost per generated summary = $0.04
Reviewer loaded cost = $75/hourNaive generation cost:
5,000 * $0.04 = $200/weekActual review cost if all 5,000 are reviewed:
5,000 * 4 minutes = 20,000 minutes = 333.3 hours
333.3 * $75 = $24,997.50/weekBut capacity is only 1,200. If the company reviews 1,200 and sends all 5,000, the serious accepted errors are:
Reviewed serious errors:
1,200 * 3% = 36 potential errors
80% caught = 28.8 caught
7.2 accepted serious errors
Unreviewed serious errors:
3,800 * 3% = 114 accepted serious errors
Total serious accepted errors = 121.2
Error cost = 121.2 * $3,500 = $424,200/weekThe model cost is irrelevant next to error cost.
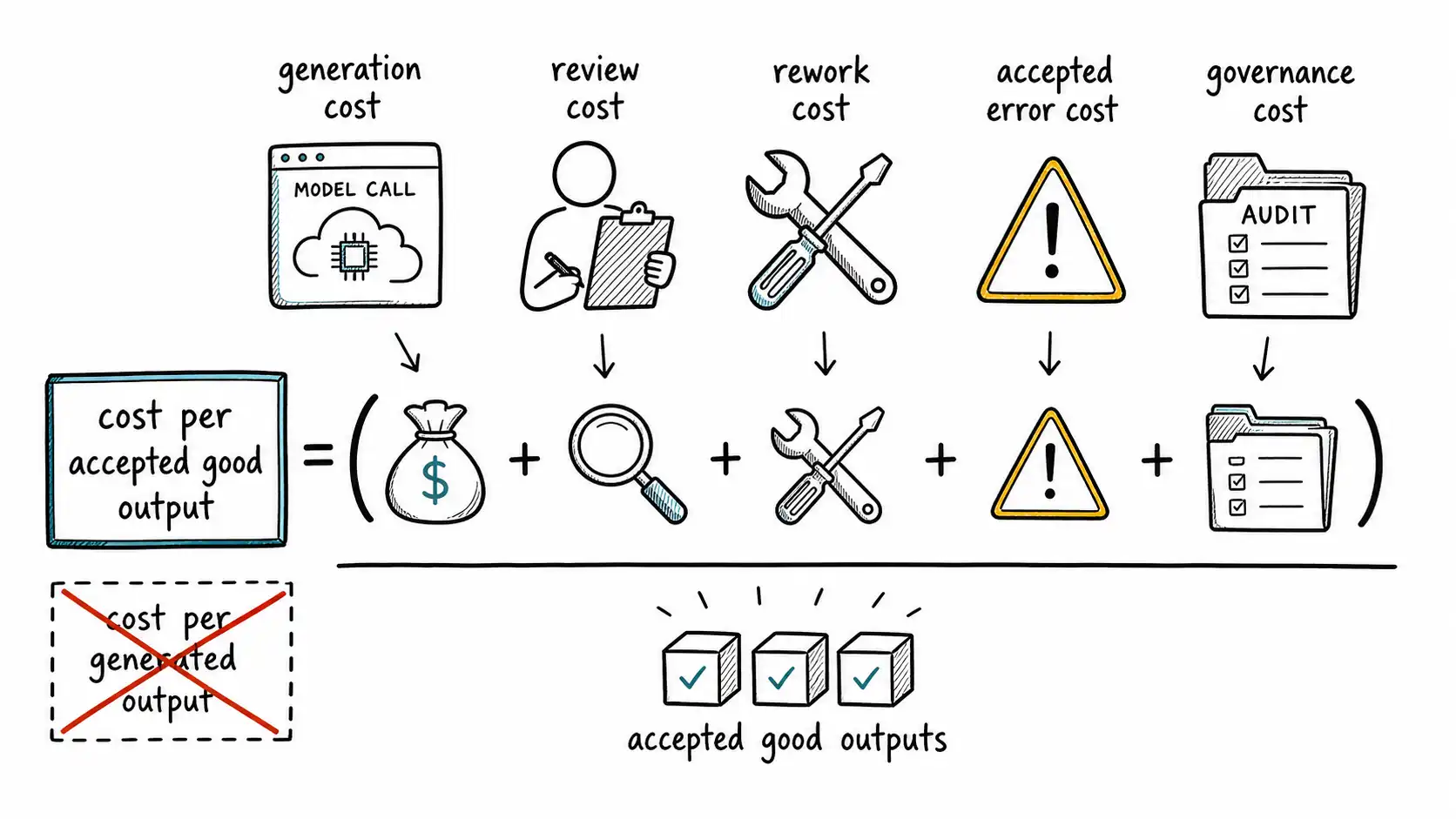
The calculation is intentionally blunt. Real error rates vary. Error costs are hard to estimate. Review can be better designed. But the logic is durable: cost per generated output is not the economic unit. Cost per accepted good output is the economic unit.
A better calculation:
Cost per accepted good output =
(generation cost + review cost + rework cost + accepted error cost + monitoring/governance cost)
/ accepted good outputsThis equation should be printed on the wall of every AI steering committee.
The review burden is why the "10x output" story can create negative value. Imagine the same renewal summary system with three deployment designs.
| Design | Generated | Reviewed | Sent | Good sent | Serious accepted errors | Net value |
|---|---|---|---|---|---|---|
| Human baseline | 300 | 300 | 280 | 270 | 1 | Moderate |
| Naive AI blast | 5,000 | 1,200 | 5,000 | 4,850 | 121 | Negative after error cost |
| Risk-tiered AI | 2,000 targeted | 700 high-risk + sample | 1,600 | 1,560 | 6 | Strong positive |
The best design generates less than the naive design. It wins because it routes judgment.
This is consistent with the "jagged technological frontier" observed by Dell'Acqua and colleagues in the BCG field experiment: AI improved performance on tasks within the frontier and could harm performance when applied outside it (https://www.hbs.edu/faculty/Pages/item.aspx?num=64700). The review-cost lesson is the operating version of that frontier. You cannot average your way across uneven capability. You must know where the model is reliable enough to pass, where it needs sampling, and where it requires expert review.
Review cost has several forms.
First is direct review labor. Someone reads, tests, verifies, approves, edits, or rejects the output. This is easy to measure but often underestimated because review is fragmented across roles. A senior engineer spends ten minutes understanding a machine-authored diff. A product manager spends twelve minutes checking whether a generated spec matches intent. A legal reviewer spends six minutes verifying whether a clause summary omitted a carve-out. Each minute is small. At scale, review becomes the new factory floor.
Second is context reconstruction. Reviewers often need to recover context the model used or should have used: source documents, customer history, codebase constraints, policy version, prior decisions, pricing exceptions. A bad AI system hands the reviewer a final answer. A good AI system hands the reviewer an evidence packet. The difference shows up in review time and review quality.
Third is rework. A wrong output is not simply rejected. It consumes attention, creates confusion, sometimes contaminates downstream artifacts, and may require undoing. Generated code that is directionally plausible but architecturally wrong can take longer to review than a human-written diff because the reviewer must infer the missing intent.
Fourth is accepted error cost. This is the cost that actually matters but is most often excluded because it is difficult to price. A bad support response can lose a customer. A bad legal summary can create liability. A bad pricing recommendation can destroy margin. A bad code change can create an incident. A bad recruiting screen can create legal and ethical harm. The model's cost is almost never the binding cost in these cases.
Fifth is governance overhead. In high-stakes contexts, the company must prove that decisions were controlled. NIST's AI Risk Management Framework treats risk management as a socio-technical process across governance, mapping, measurement, and management (https://www.nist.gov/itl/ai-risk-management-framework). That means review evidence, policy, traceability, and monitoring are not optional extras. They are part of production.
The practical response is not to review everything. Reviewing everything is often economically impossible and cognitively ineffective. Bainbridge's "ironies of automation" warned that automation can leave humans with the most difficult monitoring and intervention tasks, often after their skills and attention have been eroded (https://davidjusth.com/s/Ironies-of-Automation_Bainbridge_1983.pdf). A reviewer forced to inspect thousands of low-risk machine outputs becomes less capable of catching the rare severe error. The solution is review design.
A review system has five levers:
- Risk tiering: classify outputs by consequence and reversibility.
- Confidence and uncertainty bands: treat low-confidence or out-of-distribution cases differently.
- Sampling: review a statistically meaningful slice of low-risk output to detect drift.
- Escalation: route high-risk or ambiguous cases to the right expert with context.
- Feedback conversion: turn review outcomes into eval cases, policy updates, or training data.
Consider support replies:
| Tier | Condition | Review action | Why |
|---|---|---|---|
| Auto-send + sample | Known issue, low-value account, high retrieval confidence, no refund | Send automatically; sample 5% | Low error cost and reversible. |
| Human review | Billing dispute, moderate account value, generated answer cites policy | Review with policy evidence | Error cost moderate; context matters. |
| Expert escalation | Enterprise renewal, legal threat, data-loss claim | Escalate to named owner | Error cost high and relationship-sensitive. |
| Block | Missing source, policy conflict, hallucinated procedure | Do not send | Output failed acceptance criteria. |
This design reduces review volume while improving review quality. It also creates data. The sampled cases reveal broad drift. Human-reviewed cases create labels. Escalated cases reveal policy gaps. Blocked cases become eval tests.
The review-cost equation can also guide product design. If review cost is high because reviewers lack context, invest in traceability. If review cost is high because outputs are too broad, narrow the task. If review cost is high because risk is mixed, separate workflows by tier. If review cost is high because acceptance criteria are vague, improve specs and rubrics. If review cost is high because the model is unreliable on edge cases, add retrieval, tools, fine-tuning, or a different model. If review cost is high because the task should not be automated, stop.
The hardest executive lesson is that some AI workflows look inefficient because they are honest. A workflow that generates fewer outputs but attaches evidence, routes risk, measures accepted error, and updates evals may have less impressive activity metrics than a system that floods the company with polished drafts. The honest workflow is the one that can scale.
A CFO should ask for three cost curves:
| Curve | What it shows |
|---|---|
| Generation cost curve | Cost to produce candidate outputs. Usually falls quickly. |
| Review cost curve | Cost to accept or reject outputs at target quality. Often becomes dominant. |
| Error cost curve | Cost of accepted failures as volume and autonomy increase. Can be nonlinear. |
The nonlinear part matters. Error cost does not scale politely. One bad generated email may be harmless. One bad generated legal commitment in an enterprise proposal may cost months. One bad automated clinical instruction may be catastrophic. When error costs have fat tails, average accuracy is a weak business metric.
The organization should therefore track cost per accepted good output at each risk tier, not only in aggregate:
Low-risk accepted good output cost = low generation + sampling + low error exposure
Medium-risk accepted good output cost = generation + human review + rework + moderate error exposure
High-risk accepted good output cost = generation + expert review + evidence + audit + high error exposureA single blended ROI number hides the economics.
This chapter also explains why outcome pricing is hard. If a vendor wants to charge for resolved support cases, it must know how many generated replies become resolved cases after review and error adjustment. If a vendor wants to charge for qualified leads, it must know how many AI-generated leads survive sales judgment and close. If a coding vendor wants to charge for accepted pull requests, it must account for review burden and incident risk. The pricing metric must align with accepted good output, not generated output.
The review-cost equation is not anti-AI. It is the reason serious AI products can command serious prices. A product that merely generates drafts competes on generation cost. A product that reduces review cost, lowers accepted error, and improves value capture can price against the economic bottleneck. That is a much better business.
The chapter's takeaway: once generation is cheap, production cost moves to acceptance. Measure it, design for it, and price accordingly.
Key Takeaways
- The most dangerous number in an AI automation business case is the cost per generated output.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Judgment Economy and the adjacent chapters when you need the wider Judgment Economy and AI Strategy frame.
Designing for lower review cost without hiding risk
The best way to reduce review cost is not to pressure reviewers to move faster. It is to design outputs that are easier to judge. That means the AI system should expose sources, assumptions, confidence signals, policy references, diffs, tests, and known limitations at the moment of review. A reviewer should not have to become a detective.
For a generated contract summary, the review packet should show the clause text, the extracted interpretation, the risk category, the policy used, and the sections the model considered relevant. For a generated code change, the review packet should show the spec, affected files, tests added, test results, dependency changes, security-sensitive paths, and rollback plan. For a support response, the packet should show the customer's issue, retrieved sources, account status, entitlement, prior attempts, policy constraints, and proposed action. The output should be designed for acceptance, not admiration.
There is an important product lesson here. Many AI interfaces optimize the generated artifact because that is what users notice first. Serious AI-native systems optimize the review surface because that is where economic conversion happens. The review surface is where generated work becomes accepted work. Poor review UX is a margin leak.
Reducing review cost also requires narrowing the task. A broad instruction such as "analyze this account and recommend next steps" may require extensive review because the model could touch commercial, legal, product, and relationship dimensions. A narrower instruction such as "classify whether this account matches one of five renewal risk patterns and cite evidence" is easier to verify, easier to evaluate, and easier to route. Narrow autonomy often beats broad assistance because it creates lower review cost per accepted outcome.
Finally, track reviewer disagreement. If reviewers disagree often, the issue may not be model quality. It may be that the organization has not defined acceptance. Disagreement is expensive, but it is also information. A mature system converts reviewer disagreement into clearer rubrics, examples, thresholds, and policies. Review cost falls when judgment becomes more explicit.