Operating in the Judgment Economy
The judgment economy becomes real only when it changes meetings, dashboards, budgets, hiring, pricing, and product gates. A leadership team can agree intellectually that judgment is scarce and still run the company as if output were the goal.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The judgment economy becomes real only when it changes meetings, dashboards, budgets, hiring, pricing, and product gates. A leadership team can agree intellectually that judgment is scarce and still run the company as if output were the goal. The operating system has to move.
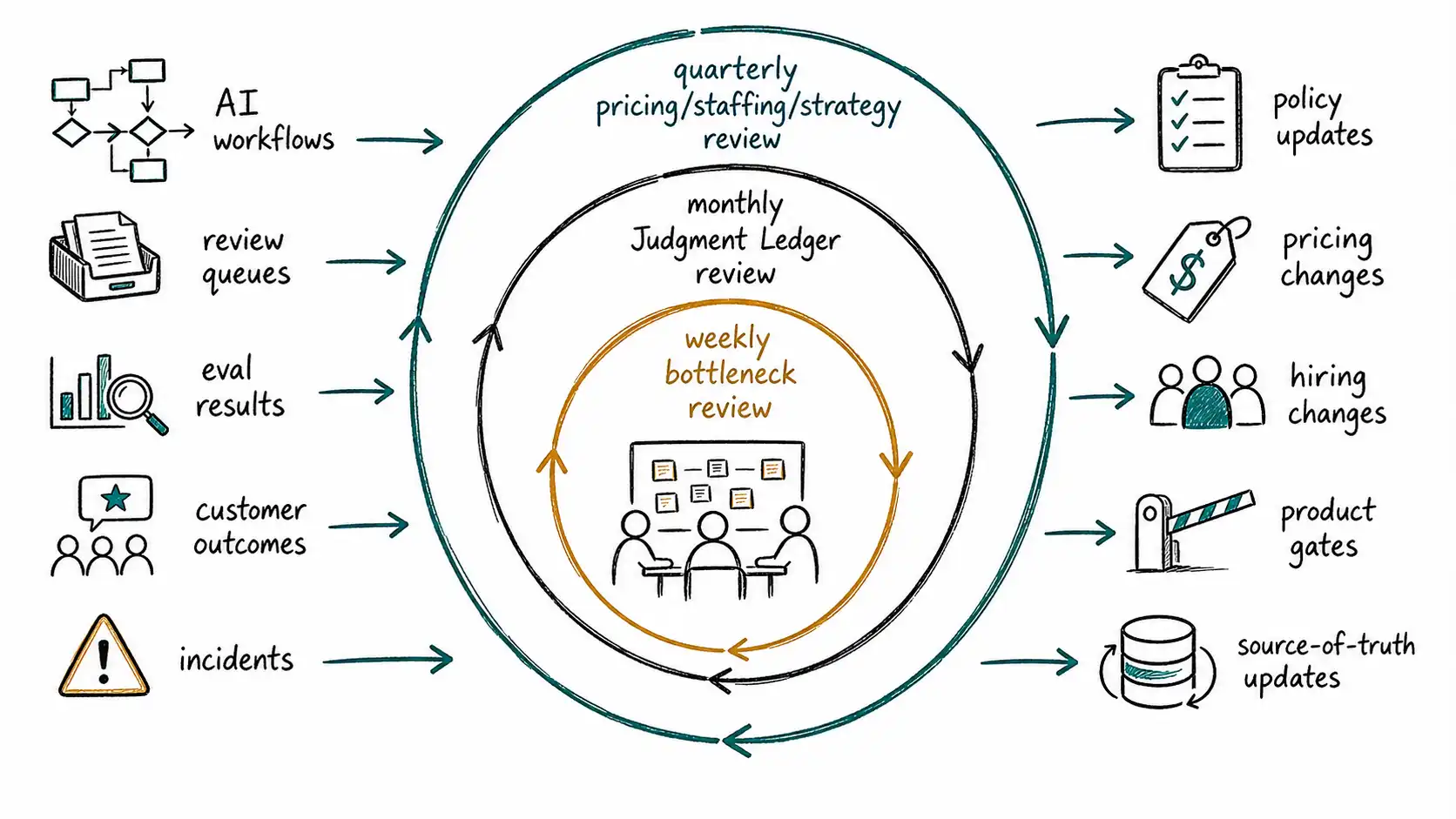
A judgment-native operating cadence starts with a different weekly review. Instead of asking each function how much AI was used or how much content was produced, the team asks where machine-generated work entered consequential decisions. The first metric is generated output, but only as the beginning of a chain. The real dashboard shows reviewed, accepted, value-confirmed, paid, and compounding outputs by workflow and risk tier.
A practical executive dashboard:
| Workflow | Generated | Accepted | Value-confirmed | Error cost | Review cost | Net value | Learning added |
|---|---|---|---|---|---|---|---|
| Support replies | 18,200 | 11,400 | 8,900 resolved | $42k | $61k | Positive | 312 eval cases |
| Sales proposals | 420 | 190 | 44 influenced wins | $18k | $37k | Positive | Claim library updated |
| Code changes | 280 | 96 merged | 83 no-regression | $22k | $49k | Mixed | 41 test additions |
| Finance analyses | 160 | 38 used | 12 board decisions | Unknown | $9k | Unclear | Definitions clarified |
This dashboard is less flattering than an AI adoption dashboard. That is why it is useful. It shows where the company is creating value, where review cost is rising, where error cost is hidden, and where measurement is still too weak to make claims.
The weekly cadence should include a "judgment bottleneck review." Which queues are waiting for senior approval? Which AI workflows are generating more than reviewers can inspect? Which reviewers are being asked to judge without enough context? Which policies are unclear? Which decisions are being escalated repeatedly because the system has not encoded a stable rule? The bottleneck review turns frustration into design work.
The monthly cadence should include a "ledger review" for each major AI workflow. The owner updates the Judgment Ledger: decision point, execution replaced, judgment required, error cost, review cost, reversibility, value capture, and moat potential. Changes matter. A workflow that begins as draft assistance may evolve toward auto-action. The ledger should change when autonomy changes. The company should not discover after an incident that an assistant quietly became an actor.
The quarterly cadence should include pricing and staffing implications. If AI has reduced execution work but increased review work, the hiring plan should move accordingly. If a product now performs measurable work, packaging should be revisited. If a workflow produces proprietary review labels, data strategy should protect and use them. If governance evidence is a sales blocker, risk infrastructure becomes revenue infrastructure.
The operating system also needs decision rights. AI increases the number of plausible actions. Without clear decision rights, organizations either stall or allow unowned decisions to slip through. Every AI workflow should declare:
- who can approve generated output;
- who can change the prompt/spec/policy;
- who can raise autonomy level;
- who can override the system;
- who owns incidents;
- who signs off on pricing claims;
- who decides when the workflow should stop.
Decision rights should be tied to consequence, not org-chart convenience. A customer-facing automated refund policy needs finance, support, and product ownership. A code-generation workflow needs engineering ownership and security constraints. A legal-summary system needs counsel ownership. A marketing content system needs brand and legal claim controls. AI workflow ownership is cross-functional because judgment is cross-functional.
A simple decision-rights table:
| Decision | Owner | Consulted | Evidence required |
|---|---|---|---|
| Move support replies from draft to auto-send for low-risk cases | VP Support | Legal, Product, Trust | Eval pass, sample review, escalation policy |
| Allow coding agent to open PRs automatically | VP Engineering | Security, Platform | Test coverage, sandbox policy, review rubric |
| Charge for resolved outcomes | CRO/CFO | Product, Legal, CS | Baseline, attribution method, quality definition |
| Use customer data for workflow improvement | Data/Privacy owner | Product, Legal | Consent basis, retention policy, deletion process |
| Retire human review for tier | Workflow owner | Risk/compliance | Error history, sample plan, rollback path |
The budget model must also change. AI initiatives often get funded as tools, but the real cost is system redesign. Budget should include integration, evals, review operations, governance, data instrumentation, process redesign, training, and pricing experimentation. A $100k model/tool line item may require $400k of surrounding operational work to produce reliable value. That does not make the initiative bad. It makes the accounting honest.
A judgment-economy business case should have this shape:
Baseline cost and value:
- Human execution cost
- Current outcome quality
- Current error/rework cost
- Current cycle time
- Current value capture
AI system economics:
- Generation cost
- Integration and tooling cost
- Review cost
- Eval/governance cost
- Expected accepted output volume
- Expected error cost
- Expected customer-valued outcome
Compounding assets:
- Review labels captured
- Outcome data joined
- Evals added
- Policies improved
- Customer trust or distribution deepened
- Pricing power createdThis is slower than a toy ROI calculation but far faster than cleaning up a failed rollout.
The company should also maintain a "judgment debt register." Technical debt is familiar: shortcuts that make future engineering slower or riskier. Judgment debt is the accumulation of unclear acceptance criteria, hidden review queues, unpriced risk, unowned decisions, missing source authority, vague policies, and dashboards that count output instead of value. It is the debt AI creates when generation outruns governance.
Examples of judgment debt:
| Debt item | Symptom | Paydown |
|---|---|---|
| Vague acceptance | Reviewers disagree constantly | Write rubric, examples, counterexamples |
| Hidden review cost | Senior people complain of AI fatigue | Track review minutes and route by risk |
| Unpriced value | Customers use AI heavily but expansion stalls | Revisit value metric and packaging |
| Missing evidence | Buyers ask for auditability and sales stalls | Add trace logs, evals, policy docs |
| Apprenticeship gap | Juniors use AI but do not improve judgment | Design review training loops |
| Output dashboard | Leadership celebrates volume despite no outcome lift | Move to accepted/value-confirmed metrics |
The judgment debt register belongs in the same operating review as roadmap risk because it affects delivery, revenue, and trust.
The final practice is narrative discipline. Leaders should stop saying "AI did the work" when what they mean is "AI produced a candidate artifact." They should say "the system accepted the output," "the workflow resolved the case," "the reviewer rejected the recommendation," or "the policy allowed auto-action." Precise language creates precise accountability. Vague language lets unowned risk hide inside magic.
The conclusion of this book is therefore practical. In the judgment economy, doing becomes cheap, but deciding does not disappear. It becomes more explicit, more valuable, and more dangerous to ignore. The winners will not be the organizations that generate the most. They will be the organizations that know which generated work deserves to become a shipment, a price, a decision, a customer promise, or a learning loop.
Key Takeaways
- Operating in the Judgment Economy names the operating decision a team has to make before it accepts the work.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with The Judgment Economy and the adjacent chapters when you need the wider Judgment Economy and AI Strategy frame.
Executive Checklist - Where Is Judgment Scarce?
- Which AI workflows produce more output than the organization can review?
- Where does generated output become a customer promise?
- Which accepted errors would be expensive, reputational, or regulatory?
- Which review queues depend on a few senior people?
- Which workflows have no clear owner for autonomy changes?
- Where is value created but not captured in pricing?
- Which AI metrics count generation rather than accepted outcomes?
- Which review decisions are not captured as data?
- Which junior learning loops were removed by automation?
- Which governance artifacts could become buyer trust and pricing power?
The companies that answer these questions honestly will move faster because they will know where speed is safe. They will price better because they will know what value they stand behind. They will hire better because they will know where judgment, not throughput, is scarce. And they will build stronger moats because their systems will learn from the decisions competitors do not even measure.
The first ninety days
For a leadership team starting from ordinary AI adoption, the first ninety days should not be a giant transformation program. It should be a measurement correction.
In the first thirty days, inventory the ten highest-volume AI workflows. For each, record generated output, current review process, decision point, owner, and known incidents. Do not attempt to solve everything. The goal is visibility. Most companies will discover that several workflows have no clear acceptance metric and no named owner for autonomy changes.
In the next thirty days, pick three workflows and build ledgers. Estimate review cost, error cost, reversibility, and value capture. Add at least one accepted-outcome metric to each workflow dashboard. Replace at least one output-volume celebration with an accepted-value discussion in the operating review. This creates a new management reflex.
In the final thirty days, redesign one review queue, one pricing/value metric, and one apprenticeship loop. The review redesign proves that judgment can scale. The pricing metric proves that value capture can move. The apprenticeship loop protects future judgment. Together they show the organization that the judgment economy is not a slogan; it is a set of operating changes.
The ninety-day goal is not maturity. It is honesty. Once honest metrics exist, the organization can decide where to automate aggressively, where to gate, where to invest in evals, where to change pricing, and where to stop. Honesty is the first moat because it lets the company learn from reality faster than competitors learn from dashboards.
One final habit matters: stop approving AI projects without a named kill condition. A workflow should define not only what success looks like but what evidence would cause the company to pause, narrow, or stop it. Kill conditions might include accepted error above threshold, review cost exceeding value, reviewer disagreement that does not improve, customer trust decline, pricing metric failure, or inability to join outcomes back to outputs. This protects the organization from sunk-cost automation.
The judgment economy rewards companies that can change their mind. If a workflow is low-risk and high-value, scale it. If it creates noise, narrow it. If it reveals valuable but expensive human judgment, price it or staff it. If it produces no compounding asset, treat it as efficiency rather than strategy. The point is not to worship judgment; it is to allocate judgment where it earns its keep.
The practical end state is an organization with fewer illusions. Leaders know where doing has become cheap. They know where deciding is still scarce. They know what review costs. They know which outcomes customers value. They know where trust can be converted into pricing power. That knowledge is itself an advantage because most organizations will still be celebrating the size of the pile on the left side of the funnel.
The final management rule is simple: no output metric without an acceptance metric beside it. If a dashboard says drafts generated, it must also say drafts accepted. If it says code written, it must say code merged and regression-free. If it says cases touched, it must say cases resolved and reopened. If it says analyses produced, it must say decisions supported. Pairing these metrics changes behavior immediately because it makes empty volume visible.
A leadership team that adopts this rule becomes harder to fool. It can still celebrate speed, but only when speed survives acceptance. It can still invest in automation, but only when automation survives value capture. That is the minimum discipline required when doing is cheap and deciding is everything. Measure accepted value relentlessly.