Conclusion: The Most Accountable Agent Wins
The best agents are not the most autonomous; they are the most accountable, and the BOUND Checklist is how you ship one.

The Most Accountable Agent Wins because the safest production agent is not the most autonomous one; it is the one whose actions can be bounded, observed, evaluated, stopped, and unwound.
Key Takeaways
- The best agents are not the most autonomous; they are the most accountable. An accountable agent still fails, but it fails in ways you can see, stop, and unwind.
- Autonomy is a liability you take onto your balance sheet, like debt. Account for it: the BOUND Test is the application, the Autonomy Ladder the credit limit, the Tool Trust Contract the terms, the Incident Chain the default scenario.
- Run the BOUND Checklist before any agent acts on its own. Every item has an artifact behind it; a single missing box is your next sprint, not a reason to ship anyway.
- A better model raises the ceiling on what an accountable agent can do but never removes the need for accountability. The smarter the agent, the more its boundaries matter.
- The narrow band where autonomy earns its keep is the set of genuinely open, ambiguous, or changing tasks where you have also done the work to make autonomy accountable. Stay inside it: refuse autonomy where it adds nothing, earn it where it adds everything.
Read this beside the BOUND Test, AI agent evals, and how to build AI agents when you turn the chapter into a production design. For governance language, use NIST AI RMF as the external reference point.
Two years after the demo that lied, I sat in a different room watching a different agent. This one resolved invoice disputes too, the same task that cost us $14,000. The demo was less impressive. It paused twice to escalate cases it could not resolve. It refused to issue a credit on an enterprise account and handed it to a human with a clean summary. One run hit its budget and landed in a graceful escalation. Nobody in the room said "headcount." Somebody said "I trust it," which is a much better thing to hear, and a much rarer one.
The second agent was not smarter than the first. The model was better, marginally, but that was not the difference. The difference was that the second agent was accountable: every decision was traceable, every tool declared its side effects, every irreversible action was gated, every failure landed somewhere safe, and there was a switch that actually worked. The first agent looked autonomous and was a liability. The second agent looked cautious and was an asset. That inversion is the whole book in one comparison, and it points at the claim I have been building toward: the best agents are not the most autonomous. They are the most accountable.
Autonomy was always the liability
The motif of this book has been one sentence: autonomy is not a feature, it is a liability that must earn its place. I want to be precise about what that means now that we have built the whole apparatus, because it is easy to mishear it as "agents are dangerous, avoid them." That is not the claim.
The claim is that autonomy is a thing you take onto your balance sheet, like debt. Debt is not bad; use well, it builds things you could not otherwise afford. But you account for it, you know its terms, you know what happens if you cannot service it, and you do not take on more than the asset can support. Autonomy is the same. The agent that resolves disputes in eleven seconds is use autonomy, and the question is never "is autonomy good?" but "is this much autonomy, on this task, with these tools, supported by these controls, a liability we can service?" The first agent took on autonomy it could not service. The second took on exactly as much as its controls supported, and not a rung more.
Every framework in this book is an accounting discipline for that liability. The BOUND Test is the loan application: five conditions that must hold before you take the autonomy on. The Autonomy Ladder is the credit limit: you raise it on evidence, and you lower it when the evidence turns. The Tool Trust Contract is the terms sheet: exactly what each action can do and how to undo it. The Agent Incident Chain is the default scenario: what happens, link by link, when you cannot service the debt, and where you can intervene. Accountable autonomy is autonomy you have accounted for. That is all "earn its place" ever meant.
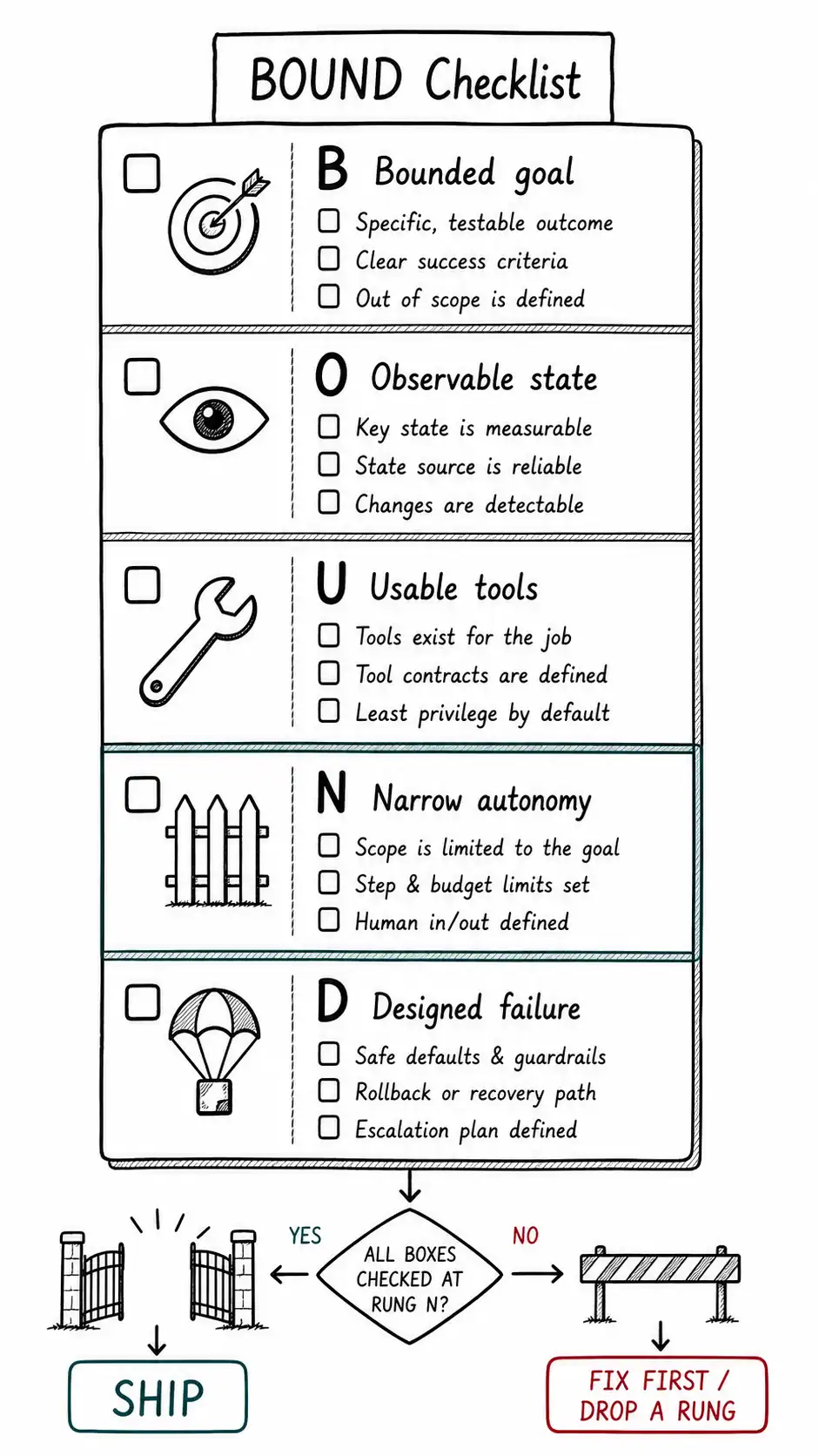
The BOUND Checklist before you ship
Here is the artifact that gathers the whole book into one gate. Run it before any agent crosses the line from copilot to acting on its own. Every item is a yes-or-no with an artifact behind it, and a single no means not yet, here is what to build.
B, Bounded goal.
- The goal is a task contract with machine-checkable success conditions, not a prose objective.
- Scope has an affirmative whitelist and explicit out-of-scope tripwires.
- There are named terminal states and four budget fuses (steps, tool calls, cost, wall clock).
O, Observable state.
- Every run emits a replayable trace recording observation, reasoning, decision, tool call with side-effect class, state checkpoint, and memory reads.
- You can reconstruct any run and answer "where did the plan change?" from data already captured.
- Deterministic and counterfactual replay both work, with WRITEs run against fixtures.
U, Usable tools.
- Every tool has a completed Tool Trust Contract: permission, input schema, side effects, idempotency, rollback, rate limits, audit logging.
- Every tool is classified READ, REVERSIBLE-WRITE, or IRREVERSIBLE-WRITE by its least reversible downstream effect.
- Irreversible writes are removed from the toolbox or gated.
N, Narrow autonomy.
- The toolbox contains only tools the task needs (no excessive functionality).
- The agent acts in the requesting user's context with scoped credentials and cannot escalate its own privileges.
- There is an explicit allow / escalate / never decision list, and the rung on the Autonomy Ladder is chosen as the lowest that delivers the value.
D, Designed failure.
- A failure taxonomy with a safe landing zone per class, defaulting to halt-and-escalate.
- A kill switch that is fast, scoped, dual-mode, automatically triggered, and drilled.
- A rollback path: a saga log and named compensations, so REVERSIBLE-WRITEs auto-undo.
- A postmortem habit that asks the autonomy-demotion question and turns every incident into an eval fixture.
A task that checks every box is ready for an agent at the chosen rung. A task that misses any box is not, and the box it misses is your next sprint. I have never run this checklist and found nothing to fix on the first pass, and I have never regretted the work a failed box forced me to do before launch.
What I am not claiming
Let me be honest about the limits, because a field manual that oversells itself is the same hype I have spent the book arguing against.
I am not claiming this makes agents safe in the absolute. It makes them accountable, which is different and more achievable. An accountable agent still fails; it fails in ways you can see, stop, and unwind, which is the realistic goal. Anyone promising safe is selling the demo that lied.
I am not claiming the frameworks are the only way. The BOUND Test, the Ladder, the Contract, and the Chain are scaffolding for thinking, and you should adapt them to your domain. If your version of designed failure looks different from mine, good, as long as you have one.
And I am not claiming the technology will sit still. The models will get better, the benchmarks will get gamed and replaced, the frameworks will churn. What will not change is the structure of the problem: a system that chooses its own actions at runtime, against real tools, with real side effects, is a system whose autonomy must be accounted for. A better model raises the ceiling on what an accountable agent can do. It does not remove the need for accountability, because a more capable agent with the same missing controls is a larger liability, not a smaller one. The smarter the agent, the more the boundaries matter, not less.
The decision you can make differently tomorrow
If you take one thing from this book into the next planning meeting, make it this reframing. When someone says "let's make it autonomous," do not argue about whether autonomy is good. Ask four questions, and let the answers decide.
Which rung does this task actually need? (Usually lower than the room assumes.) What does the agent do when it is wrong, and where does that land? (If the answer is "we are not sure," you have your first sprint.) For every action it can take unsupervised, can we undo it, and can we see it? (If not, gate it or remove it.) And when it fails in production, which it will, can we stop it in seconds and unwind it cleanly? (If not, you are the logistics company, and you have not had your bad morning yet.)
Those four questions convert an argument about enthusiasm into a decision about accountability. They are the BOUND Test and the Incident Chain in conversational form, and they will route you to the same place every time: build less autonomy than you were asked for, account for the autonomy you build, and ship something you can trust rather than something that demos well.
The narrow band
The subtitle of this book is "the narrow band where autonomy earns its keep," and now I can say plainly what that band is. It is the set of tasks where the path is genuinely open, the input genuinely ambiguous, or the state genuinely changing, so a workflow cannot do the job, and where you have done the work to make autonomy accountable: bounded the goal, contracted the tools, controlled the state, governed the loop, gated the irreversible, measured the runs, traced everything, secured the boundaries, and designed the failure. Inside that band, agents are extraordinary. They do work that no script, workflow, or copilot could touch, and they do it within a structure that makes their power safe to wield.
Outside that band, on one side, are the tasks that never needed an agent, where a workflow would have been cheaper, faster, and calmer. On the other side are the tasks that needed an agent but were given one without the controls, where the demo lied and the $14,000 credit posted. The whole discipline is staying inside the band: refusing autonomy where it adds nothing, and earning it where it adds everything.
The agent in the first demo looked the smartest. It was the least accountable, and it was the one that failed. The agent that resolved disputes two years later looked cautious, paused to escalate, refused some actions, and asked for help. It was the most accountable, and it was the one I trusted with real money and real customers. That is the trade the entire industry keeps getting backwards. Autonomy is not the prize. Accountability is. Build the accountable agent, and the autonomy you can safely grant it will be more than enough.