Tools, Permissions, and Side Effects
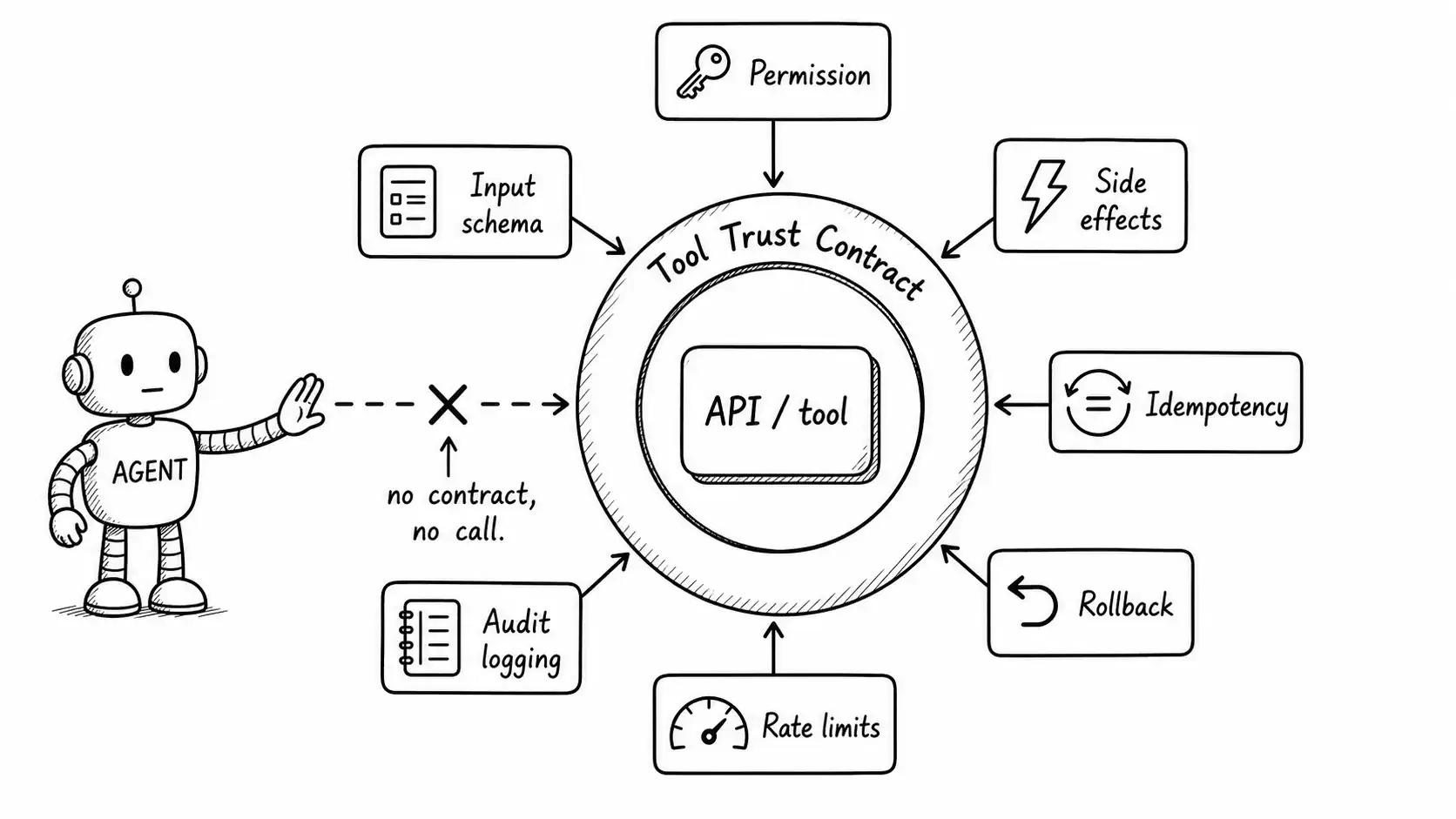
The Tool Trust Contract: the seven properties every tool must declare before an agent is allowed to call it.

Tools, Permissions, and Side Effects are the production boundary of agent design because every exposed tool becomes part of the agent's blast radius.
Key Takeaways
- Function-call schemas capture when to call a tool and nothing about what you expose by allowing it. The Tool Trust Contract closes that gap with seven declared properties: permission, input schema, side effects, idempotency, rollback, rate limits, audit logging.
- Classify every tool by its least reversible downstream effect into READ, REVERSIBLE-WRITE, or IRREVERSIBLE-WRITE. Classify by walking the full blast radius, as a review, not the author's one-line guess.
- Idempotency keys, named rollback mechanisms, and rate limits are not optional polish. They are what make retries, replays, and constrained autonomy safe.
- Tool errors and nulls are typed observations the agent must handle, governed by an output contract, not exceptions to swallow. The
nullthat became "null" was a missing output contract, not a model failure.- The permissions matrix makes excessive agency visible and bounds what a prompt injection can achieve. The cheapest security control is the tool you never registered.
Read this beside security boundaries for tool-using systems, human handoffs and approvals, and how to build AI agents when you turn the chapter into a production design.
The most dangerous line in any agent codebase is the one that registers a tool. It usually looks innocent: a function name, a description, a JSON schema for the arguments. The description is written for the model ("issues a credit to a customer account"). What it never says, because the schema format has no field for it, is the thing that actually matters: what happens to the world when this gets called, whether calling it twice does it twice, and whether you can undo it.
When Toolformer showed that models could teach themselves to call APIs, and when function calling became a first-class feature in every major model API, the industry got very good at the easy half of tool use: getting the model to emit a well-formed call. The hard half, the half that decides whether your agent survives production, is everything the function-call schema does not capture. A tool description tells the model when to call a tool. It tells you nothing about what you are exposing when you let it.
This chapter is about closing that gap with a single artifact: the Tool Trust Contract. Before an agent is permitted to call a tool, that tool declares seven properties. No declaration, no access. The contract is the U gate of the BOUND Test, and it is the difference between a tool the agent can use and a tool that exists.
The seven properties
1. Permission. Who is this tool acting as, and what is it allowed to touch? A tool should run with the narrowest credentials that let it do its job, in the security context of the actual user or task, never with a god-mode service account because that was easier. This is least privilege at the credential layer. If the refund tool can technically refund any account because it holds an admin token, the agent's blast radius is every account, regardless of what the task contract says.
2. Input schema. The typed, validated shape of the arguments, with constraints, not just types. amount: number is a type. amount: number, min 0, max 5000, currency in {USD, EUR} is a constraint. The constraints are where you stop the agent from passing the full invoice total into a credit field. Validate at the boundary, reject malformed or out-of-range arguments before they reach the side-effecting code, and treat a validation failure as a tool error the agent must handle, not a crash.
3. Side effects. The property that the function-call schema forgets and the one that ends the most incidents. Every tool must be classified into exactly one of three side-effect classes:
- READ: observes state, changes nothing. Safe to call freely, safe to retry, safe to run speculatively.
- REVERSIBLE-WRITE: changes state in a way you can fully undo within a known window by a known mechanism. Issuing a draft, setting a flag you can unset, creating a record you can delete.
- IRREVERSIBLE-WRITE: changes state you cannot fully undo. Sending an email to a customer, moving money in a way the payment provider will not reverse, deleting data with no backup, calling a third party that takes external action.
This classification is the load-bearing wall of the whole discipline. An agent should call READ tools freely, call REVERSIBLE-WRITE tools within its autonomy grant, and never call IRREVERSIBLE-WRITE tools without either an approval gate or a constrained-agent envelope that makes the specific action effectively reversible (a refund under $50 that the provider reverses within 24 hours).
4. Idempotency. Does calling this twice with the same arguments do it once or twice? Agents retry. Networks fail. Orchestration layers replay. If a tool is not idempotent, every one of those normal events can double the side effect, which is exactly how applyCredit turned a retry into a duplicate credit. A tool is either naturally idempotent, made idempotent with an idempotency key (the tool deduplicates on a client-supplied token, the pattern every serious payments API uses), or explicitly flagged not idempotent so the orchestration layer knows it must never retry it blindly.
5. Rollback. For REVERSIBLE-WRITE tools, what is the exact mechanism and window to undo? Not "we could probably undo it." The specific compensating action: the tool name, the arguments, the time window in which it works, and what state it restores. This is the saga pattern from distributed systems applied to agent actions: every write has a paired compensation, and the system knows how to run it. If you cannot name the rollback, the tool is not REVERSIBLE-WRITE; it is IRREVERSIBLE-WRITE, and you have been lying to yourself about your blast radius.
6. Rate limits. How often may the agent call this, per run and per unit time? Agents in a loop can hammer a tool in ways no human ever would. Rate limits protect the downstream system from the agent and protect your budget from a loop that calls a paid API two thousand times because it got stuck. Rate limits are also a security control: OWASP explicitly recommends rate-limiting tool invocation as a mitigation for excessive agency, because an abnormal call rate is often the first observable signal that something has gone wrong.
7. Audit logging. Does every invocation get recorded with who, what, when, with what arguments, and what result? An unlogged tool call is an invisible action, and invisible actions break the O gate. The audit log is not the same as the agent trace (the trace is for debugging the agent; the audit log is for reconstructing what happened to the world), and you want both. A tool that cannot be made to log every invocation should not be in an agent's toolbox.
The contract as config
Here is a Tool Trust Contract for the refund tool that should have existed before the demo. It is the artifact you fill out per tool, reviewed and signed off before the tool is registered.
tool: issue_refund
version: 2
permission:
acts_as: "task-scoped service identity, customer-bound"
scope: "refund the named customer's own transactions only"
forbidden: "cross-customer access, payouts, plan changes"
input_schema:
customer_id: { type: string, must_match: task.customer_id }
transaction_id: { type: string, must_belong_to: customer_id }
amount_usd: { type: number, min: 0.01, max: 5000 }
reason_code: { type: enum, values: [DUPLICATE, OVERCHARGE, GOODWILL] }
side_effects: REVERSIBLE-WRITE # provider reverses within 24h
idempotency:
mode: key
key_source: "hash(customer_id, transaction_id, amount_usd)"
behavior: "duplicate key returns the original result, does not refund twice"
rollback:
mechanism: "void_refund(refund_id)"
window: "24h from issue"
restores: "transaction to pre-refund state, removes ledger entry"
rate_limits:
per_run: 3
per_customer_per_day: 5
per_agent_per_minute: 20
audit_logging:
records: [actor, customer_id, transaction_id, amount_usd, reason_code, refund_id, timestamp, agent_run_id]
destination: "immutable audit store"
autonomy:
unsupervised_if: "amount_usd <= 50 AND account.tier!= enterprise"
else: "ESCALATE for human approval"Every field is a control that maps to a failure. must_match: task.customer_id stops the agent from refunding the wrong account. idempotency.mode: key stops the doubled credit. rollback makes the REVERSIBLE-WRITE classification honest. autonomy.unsupervised_if is where the Tool Trust Contract meets the Autonomy Ladder: the constrained-agent envelope for this specific tool, expressed as a checkable condition. The agent gets rung-5 autonomy on small, non-enterprise refunds and rung-4 supervision on everything else, decided at the tool level, in config, reviewed by a human.
Side-effect classification is a team activity, not a guess
The most common way teams get the side-effect class wrong is by asking the engineer who wrote the tool, in isolation, and accepting the first answer. The engineer says "issue_refund is reversible, you can void it," which is true in the payments system and false in the customer's inbox, because the void does not unsend the refund-confirmation email the refund triggered. Side effects cascade through systems the tool author may not own.
So classification is a review, not a declaration. Walk the full blast radius: when this tool runs, what else fires? Webhooks, notifications, downstream syncs, third-party calls, ledger entries, cache invalidations. Classify the tool by its least reversible downstream effect. If issuing a refund sends an irreversible email, then issue_refund is IRREVERSIBLE-WRITE for the purposes of agent autonomy, no matter how cleanly the payments record reverses. This is exactly the applyCredit lesson: the team classified it by the part they owned (the credit) and missed the part they did not (the dunning webhook).
A useful forcing question for the review: "If the agent does this and it turns out to be wrong, what is the worst thing the customer or a regulator experiences, and can we fully undo that specific thing?" If the worst thing is "an email they cannot unreceive," you have an irreversible write wearing a reversible costume.
Tool errors are inputs, not exceptions
An agent's tools will return errors: timeouts, 500s, validation rejections, rate-limit responses, ambiguous nulls. The wrong design treats a tool error as an exception that crashes the run or, worse, gets swallowed so the agent proceeds as if the call succeeded. The right design treats a tool error as a typed observation the agent must reason about, with the orchestration layer enforcing the policy.
Concretely, every tool call returns a structured result the agent can read: { ok: true, value: ... } or { ok: false, error_class: ..., retryable: bool, message: ... }. The agent sees the error and can decide to retry (if the contract says retryable and idempotent), try a different approach, or escalate. The orchestration layer enforces the limits: it counts retries against the budget, refuses to retry non-idempotent tools, and trips the stopping rule after N consecutive errors. The model proposes the recovery; the system enforces the boundaries.
This is where the disputed_amount: null bug lived. The tool returned a null, the serialization turned it into the string "null," and the agent treated it as data rather than as a missing value it should have questioned. The fix is at the contract boundary: a tool's output schema is as much a contract as its input schema. A nullable field is declared nullable, nulls are rendered to the model as an explicit MISSING sentinel rather than a stringified "null," and the agent's instructions say what to do when a required field is MISSING (escalate, do not substitute). The model did not fail; the tool's output contract did not exist.
The permissions matrix
For an agent with several tools, the per-tool contracts roll up into a permissions matrix: a single table that shows, at a glance, what the agent can do and at what autonomy level. This is the artifact you put in front of a security reviewer, and it is the artifact that makes excessive agency visible.
| Tool | Side effect | Idempotent | Rollback | Unsupervised autonomy | Approval needed |
|---|---|---|---|---|---|
| get_account | READ | n/a | n/a | always | never |
| get_transactions | READ | n/a | n/a | always | never |
| draft_email | REVERSIBLE-WRITE | yes | discard draft | always | never |
| send_email | IRREVERSIBLE-WRITE | no | none | never | always |
| issue_refund | REVERSIBLE-WRITE (24h) | key | void_refund | <= $50, non-enterprise | else yes |
| change_plan | REVERSIBLE-WRITE | key | revert_plan | never | always |
| delete_account | IRREVERSIBLE-WRITE | no | none | never | always |
Reading this matrix, a reviewer can ask the right questions in one minute. Why does the agent have delete_account at all? (If onboarding never deletes, remove it; excessive functionality is OWASP's first root cause of excessive agency.) Why is change_plan approval-required rather than unsupervised given it is reversible? (Because reversible does not mean low-stakes; an enterprise plan change has billing consequences worth a human glance.) The matrix turns "is this agent safe?" into a set of specific, answerable questions about specific rows.
The toolbox is part of the attack surface
One more reason the contract matters, which the security chapter will expand: every tool you give the agent is also a tool an attacker who can influence the agent's inputs gets to use by proxy. If a prompt injection (the top entry in the OWASP LLM Top 10) convinces the agent to call send_email or issue_refund, the attacker now has whatever the agent has. So the permissions matrix is not just a reliability artifact; it is a bound on what a successful injection can accomplish. An agent with delete_account in its toolbox is one successful injection away from deleting accounts. An agent without it is not, no matter how clever the injection. The cheapest security control for tool-using agents is the tool you did not register.
The Tool Trust Contract satisfies the U gate, and it does more: it gives the constrained agent its envelope, the approval gates their triggers, the audit log its entries, and the security review its checklist. But a tool, even a perfectly contracted one, acts on state. And the agent's own state, what it remembers, what is in its context, what it carries between steps, is its own source of failure. That is the next gate.