The Autonomy Ladder
Six rungs from script to autonomous agent, with promotion criteria so you climb on evidence instead of enthusiasm.

The Autonomy Ladder is the promotion path from script to autonomous agent, and each rung needs stronger evidence before the model gets more authority.
Key Takeaways
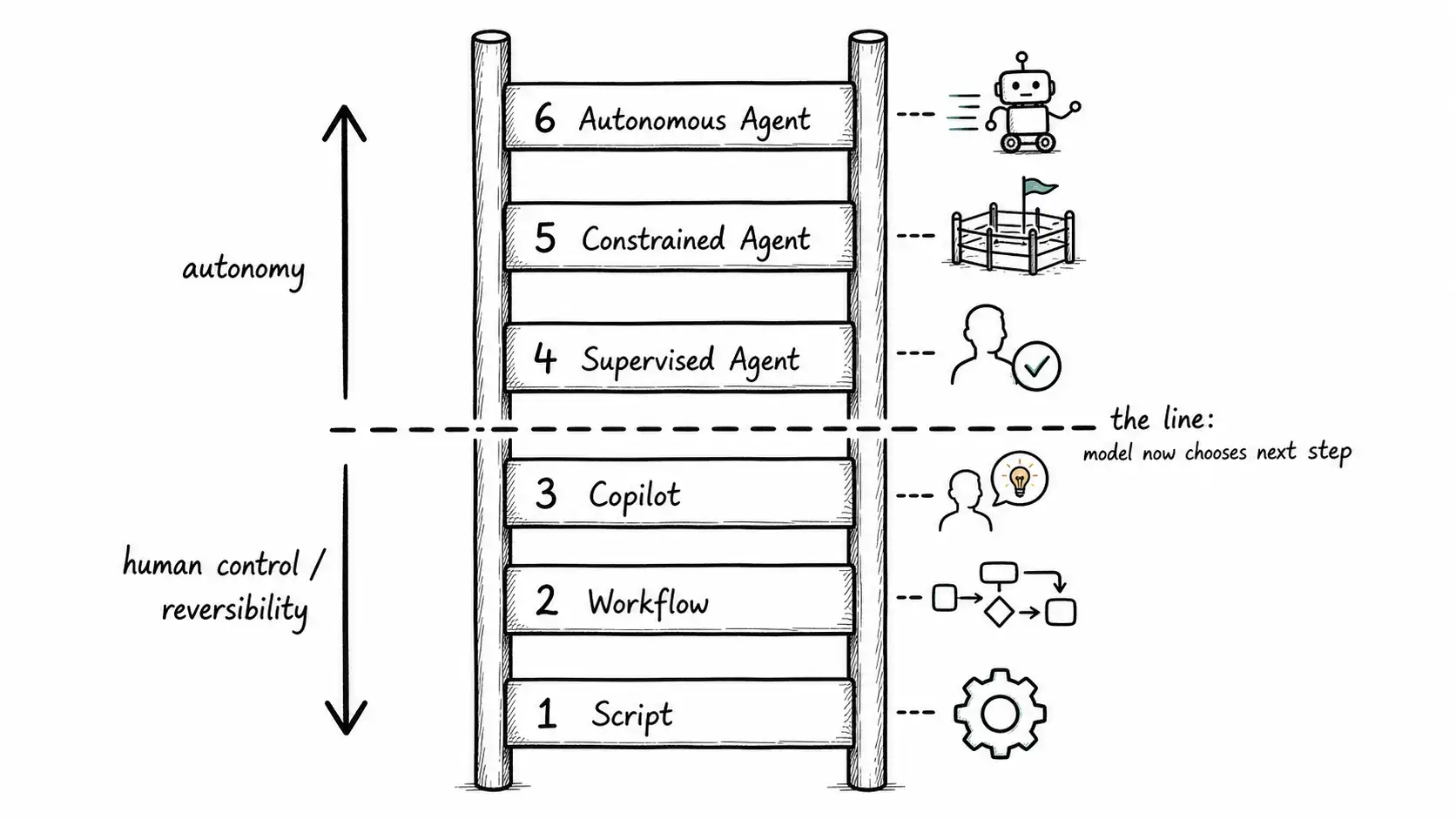
- The Autonomy Ladder has six rungs: Script, Workflow, Copilot, Supervised Agent, Constrained Agent, Autonomous Agent. The line that matters runs between Copilot and Supervised Agent, where the model starts choosing the next step at runtime.
- The goal is the lowest rung that delivers the value you need, not the highest rung you can build. Most production agents belong at rung 4 or 5.
- Promote from rung N to N+1 only with four things: a measured success rate, a characterized failure distribution, a reversibility story for the new actions, and observability sufficient to replay any run.
- Demotion is a designed control, not a defeat. Wire automatic demotion triggers to fire when the assumptions that justified the higher rung break.
- Promote narrow capabilities, not whole agents. Grant "refunds under $50, reversible, logged," not "autonomy."
Read this beside what an agent is and is not, human handoffs and approvals, and agentic AI vs generative AI when you turn the chapter into a production design.
Every team I have watched fail with agents made the same move: they started at the top of the ladder. The pitch deck showed an autonomous agent handling end-to-end work, so that is what they built first, in one quarter, and shipped to production. They skipped the rungs. When it failed, they had no idea which rung it should have stopped at, because they had never stood on any of them.
The teams that succeed do the opposite. They treat autonomy like a security clearance: you start with none, and you earn each increment by demonstrating you can be trusted at the level below. The Autonomy Ladder is the structure for that earning. It has six rungs, and the rule is simple and unromantic: you do not climb a rung until the rung below it has produced evidence, not optimism.
The six rungs
Rung 1, Script. Fixed steps, authored by a human, no decision delegated. The model, if present at all, is a pure function inside a step (extract this field, classify this text). Failure is loud and local. This is where most automation should live and stay.
Rung 2, Workflow. Predefined branches over a finite state machine. The model may choose between enumerated branches, but it cannot invent new ones. You can print the graph and prove things about it. Durable execution platforms make this rung reliable even across crashes and retries.
Rung 3, Copilot. The model proposes; a human disposes. Every consequential action passes through a human keystroke. Autonomy is bounded to suggestion. This is the highest rung where a human is the actuator on every action.
Between rung 3 and rung 4 runs the line that changes everything. Below it, a human or an authored graph chooses the next step. Above it, the model chooses the next step at runtime. Crossing that line is the decision to build an agent, and it should feel like crossing a line, not sliding up a ramp.
Rung 4, Supervised Agent. The model chooses and executes its own steps, but a human approves every action that has side effects before it commits. The agent can plan, read, and reason freely; it cannot write to the world without a human pressing approve. This is the first rung where you get the agent's flexibility, and it is the rung where most production agents should live longer than their builders want them to.
Rung 5, Constrained Agent. The model chooses and executes steps autonomously within a hard boundary: a whitelist of tools, a sandbox, a budget, an allowlist of accounts or amounts, and pre-classified reversibility on every action it can take unsupervised. Side-effecting actions either fall inside the safe envelope (reversible, bounded, logged) or escalate to a human. The agent runs without per-action approval, but only inside a fence you can describe precisely.
Rung 6, Autonomous Agent. The model chooses, executes, and completes work without per-action human involvement, including some irreversible actions, governed by policy and monitored after the fact. This rung is rarer than the discourse implies. It is appropriate for low-stakes, high-volume, reversible-or-cheap-to-undo work where the cost of any single error is small and the value of speed is large. It is almost never appropriate for money, identity, production infrastructure, or anything a regulator cares about.
The thing the marketing gets backwards: rung 6 is not the goal. The right rung is the lowest one that delivers the value you actually need. Most teams need rung 4 or 5 and convince themselves they need rung 6 because rung 6 is the one in the keynote.
Mapping the ladder to the real world
The ladder is not abstract. Here is how the rungs map to systems you have probably used or read about.
| Rung | Example | Who actuates side effects | Blast radius of one error |
|---|---|---|---|
| 1 Script | Nightly ETL job | Authored code | Bounded, predictable |
| 2 Workflow | Loan approval state machine | Authored branches | Bounded to enumerated states |
| 3 Copilot | Code completion, email draft assist | Human keystroke | Zero until human commits |
| 4 Supervised agent | Coding agent that opens a PR for human merge | Human approves each write | Whatever a human waves through |
| 5 Constrained agent | Support agent issuing refunds under $50, logged, reversible | Agent, inside fence | Capped by the fence |
| 6 Autonomous agent | High-volume content tagging, reversible | Agent, monitored after | Small per error, large in aggregate |
Notice that the research-famous coding agents largely live at rung 4 in real engineering orgs even when the paper demonstrates rung 5 or 6 behavior. SWE-agent can resolve real GitHub issues autonomously in the benchmark, but the sane production deployment has it open a pull request that a human reviews and merges. The benchmark measures rung 5/6 capability; the deployment chooses rung 4 governance. That gap between demonstrated capability and deployed autonomy is not cowardice. It is the whole discipline.
Promotion criteria: how you earn a rung
The ladder is useless without rules for climbing. "It seemed to work in testing" is not a rule; it is the sentence people say right before an incident. Here is the promotion gate I use. To move a task from rung N to rung N+1, you need all four:
1. A measured success rate at rung N, on a real eval set, that clears your bar. Not a demo. A held-out set of representative tasks with graded outcomes. If you cannot measure success at the current rung, you have no business granting more autonomy. The evals chapter builds this; for now, the principle is that promotion is gated on numbers you can defend.
2. A characterized failure distribution. You must know not just how often it fails but how. Does it fail by giving up (safe) or by confidently doing the wrong thing (dangerous)? A 90 percent success rate where the 10 percent failures are silent and irreversible is worse than an 80 percent success rate where failures are loud and self-arresting. Promotion requires that the failure mode at rung N+1 stays inside what your landing zone can catch.
3. A reversibility and containment story for the new actions the higher rung unlocks. Rung 5 lets the agent act without per-action approval, so before you grant it, every action it can now take unsupervised must be reversible, bounded, or escalated. If you cannot say what happens when this specific action is wrong, you cannot grant the rung.
4. Observability sufficient to reconstruct any run. You must be able to replay what the agent saw, decided, and did. If a promotion would create runs you cannot reconstruct, deny the promotion. You are not allowed to add autonomy you cannot debug.
If all four hold, promote, and watch the failure distribution at the new rung as carefully as a new hire's first month. If any one fails, you have found your homework. The most common missing item, by a wide margin, is number two: teams measure success obsessively and never characterize how the failures actually hurt.
Demotion is a feature, not a defeat
Ladders go down. The single most underused control in agent operations is demotion: dropping a task to a lower rung when the evidence says the higher rung is no longer earning its keep. If the failure distribution shifts (a tool starts returning ambiguous responses, an upstream system changes, a new class of input appears), the right move is to demote, fix, and re-earn the rung. Demotion should be a routine, blameless operational action, wired into the kill-switch runbook, not a crisis.
Hypothetical, but it is the shape of a hundred real ones: a constrained refund agent at rung 5 runs clean for two months. Then a payments-provider change makes a previously reversible refund irreversible above a threshold. The reversibility story that justified rung 5 is now false. The correct response is automatic demotion to rung 4 (human approves refunds again) the moment the reversibility assumption breaks, not a postmortem after the irreversible refunds pile up. Demotion triggers belong in the design, not the retrospective.
A worked promotion: from script to constrained agent
Let me walk one task up the ladder so the criteria are concrete. The task is hypothetical but boringly realistic: triaging inbound support emails for a SaaS product.
Rung 1, Script. A cron job pulls new emails and dumps them in a queue. No intelligence. Reliable, useless for triage. We are here because we have to start somewhere observable.
Rung 2, Workflow. Add a model step that classifies each email into one of six known categories and routes by a fixed table. We measure: classification accuracy 94 percent on a labeled set, misroutes are visible and cheap (a human in the destination queue notices). We have numbers and a benign failure mode. The workflow is genuinely good. Many teams should stop here.
Rung 3, Copilot. For the "needs a reply" category, the model drafts a response; an agent in the support tool suggests it; the human edits and sends. Measure: draft acceptance rate, edit distance, time saved per ticket. Failure mode is zero-risk because nothing sends without a human. We learn how often the model's drafts are usable, which we will need later.
Crossing the line, Rung 4, Supervised agent. Now the model is allowed to choose its own steps for a ticket: maybe look up the account, check recent tickets, query order status, then draft. It plans at runtime. But every external action with a side effect (issuing a credit, changing a setting) requires human approval before it commits; read-only lookups run free. Measure: task success on a real eval set of tickets, step success, how often the human rejects a proposed action and why. We are now learning the agent's planning quality with a safety net.
Rung 5, Constrained agent. The evidence from rung 4 says: on refunds under $50, the agent proposed the correct action 98.5 percent of the time over 1,200 tickets, the 1.5 percent errors were all caught by the approval step, and refunds under $50 are fully reversible within 24 hours and logged. So we grant exactly that: the agent may issue refunds under $50 without per-action approval, inside a sandbox that caps the rate, logs every action, and escalates anything over $50 or anything touching an enterprise account to a human. Everything else still needs approval. We promoted one narrow capability, not the whole agent, and we wrote down the reversibility story that justifies it.
We did not promote to rung 6, because the value of removing the cap is small and the cost of a confidently-wrong large refund is large. The ladder told us to stop, and stopping is the right answer more often than the discourse admits.
The ladder as a management tool, not just an engineering one
The Autonomy Ladder earns its keep in the meeting where someone with a budget says "make it autonomous." It gives you a shared, concrete vocabulary: not "is it safe?" (unanswerable in the abstract) but "which rung, and what is the evidence for promotion?" It converts a vibes argument into a decision with criteria. It also gives you a graceful way to ship value early (rungs 2 and 3 deliver before the agent exists) and a principled reason to slow down at the line (rung 3 to 4) where the real risk lives.
Most of all, it reframes the goal. The goal is not maximum autonomy. The goal is the lowest rung that delivers the value, operated with the controls that rung requires. Autonomy is not a feature you accumulate. It is a liability you take on deliberately, one rung at a time, only after the rung below has shown you it can be trusted.
The next chapter is the gate before the ladder: the BOUND Test, which decides whether the task should be on the ladder at all.