Incidents, Kill Switches, and Rollback
Every agent fails eventually, so the question that decides your worst day is whether you can stop it, unwind it, and learn from it.

Incidents, Kill Switches, and Rollback decide whether an agent failure becomes a contained event or a long manual cleanup.
Key Takeaways
- Incident response is a feature you build before the incident. The teams that improvise it during the incident spend most of the incident building the ability to respond.
- Agent incidents propagate along the Incident Chain: bad instruction or input, bad plan, wrong tool, irreversible action, hidden failure. You do not need a control at every link, only at the earliest reachable one, because that is where the chain gets cut.
- A real kill switch is fast (no deploy), offers graceful and hard modes, is scoped (task, tool, account, run), fires on automatic triggers, and is drilled on a schedule. An untested kill switch is a belief, not a control.
- Rollback is the saga pattern applied to agent actions: walk the saga log in reverse and run each compensation in its window. Only REVERSIBLE-WRITEs auto-undo, which is why gating irreversible actions shrinks the manual-cleanup pile.
- The agent postmortem adds two questions a service postmortem omits: should this task be demoted on the Autonomy Ladder, and what eval case was missing? Demotion is the most underused and most honest remedy, and every incident should become a permanent eval fixture.
Read this beside security boundaries for tool-using systems, observability and replay, and LLM evaluation framework when you turn the chapter into a production design.
A logistics company ran an agent that re-routed shipments when carriers reported delays. One morning a carrier's status API started returning stale data: shipments marked "delayed" that had actually arrived. The agent, doing exactly its job, began re-routing arrived shipments to new carriers, generating duplicate deliveries, cancellation fees, and a flood of confused customers. The agent was not broken. Its inputs were. By the time anyone understood what was happening, it had processed four hundred shipments. Then came the question that defines a team's worst day: how do we stop it?
The honest answer that morning was: we are not sure. There was no single switch. Turning off the agent meant finding the right service, the right flag, the right deploy, while the agent kept running. Unwinding the four hundred re-routes meant reconstructing which were wrong, which had already shipped, and which could still be cancelled, from logs that were not built for it. The incident lasted six hours, and four of those hours were spent building the ability to respond, in the middle of responding. That is the most expensive way to learn that incident response is a feature you build before the incident, not a reaction you improvise during one.
This chapter is about the D gate of the BOUND Test, designed failure, realized as three capabilities you build in advance: a kill switch that actually stops the agent, a rollback path that actually unwinds what it did, and a postmortem discipline that actually prevents the recurrence. None of these is exotic. All of them are routinely absent, because they only matter on the worst day, and teams optimize for every other day.
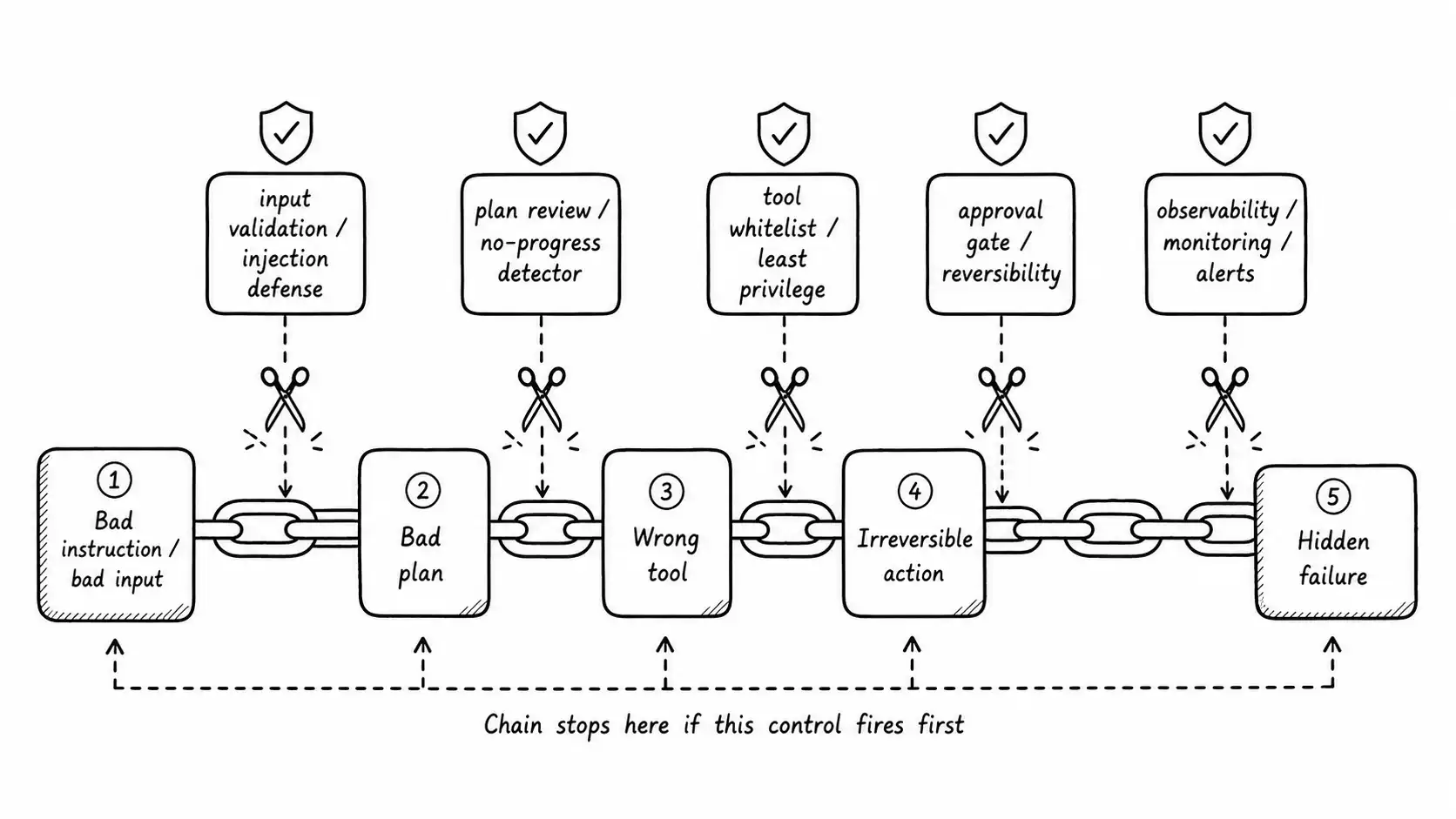
The Agent Incident Chain
Agent incidents are not random. They propagate along a chain of five links, and understanding the chain tells you where to put controls, because a control at any link can break the chain before it reaches the expensive end.
Link 1: bad instruction or bad input. The chain starts with something wrong entering the agent: a malformed goal, an injected instruction, or, as in the logistics case, a tool returning stale data the agent trusts. Controls here are input validation, the injection defenses from the security chapter, and the tool output contracts that would have flagged the stale carrier data as suspect.
Link 2: bad plan. The bad input produces a bad plan: the agent decides to re-route arrived shipments. Controls are plan review (for high-stakes runs, a human sees the plan before execution) and the no-progress and sanity detectors from the planning chapter.
Link 3: wrong tool. The bad plan reaches for a tool: the re-route tool. Controls are the tool whitelist and least privilege, the question "does the agent even have this tool, and should it?"
Link 4: irreversible action. The tool executes and the world changes irreversibly: the shipment is re-routed, the carrier is committed, the fee is incurred. Controls are the approval gate and the reversibility classification, the difference between an action that lands somewhere recoverable and one that does not.
Link 5: hidden failure. The damage accumulates unnoticed: four hundred shipments before anyone sees it. Controls are observability, monitoring, and alerting, the things that turn a six-hour silent incident into a five-minute alert.
The logistics incident ran the full chain because there was a control at zero of the five links. Stale input was trusted (link 1, no output contract). The bad plan executed unreviewed (link 2). The re-route tool was freely available (link 3). The re-routes were irreversible and ungated (link 4). And nothing alerted until a human noticed the customer complaints (link 5). The lesson of the chain is that you do not need a control at every link to survive; you need a control at the earliest reachable link, because the chain is only as long as your first intervention. One alert at link 5 would have capped the damage at minutes. One reversibility classification at link 4 would have made the unwind trivial. One output contract at link 1 would have stopped it entirely.
The kill switch that actually works
"We can turn it off" is something almost every team believes and almost no team has tested. A kill switch that works has properties most do not, and the gap between believing you have one and having one is measured in incident hours.
A real kill switch is fast: one action, one place, takes effect in seconds, not a deploy. If stopping the agent requires shipping code, you do not have a kill switch; you have a plan to maybe stop it in twenty minutes. The logistics team's "turn off the agent" meant a deploy, which is why the agent kept running while they scrambled.
A real kill switch is graceful by default and hard when needed. Graceful stop lets in-flight runs reach a safe checkpoint and stop, leaving no half-completed irreversible action dangling. Hard stop halts everything immediately, accepting that some runs will be left mid-action and need cleanup. You want both, because some incidents (runaway cost, active exfiltration) need the hard stop now, and most incidents are better served by the graceful one that does not create a second mess.
A real kill switch is scoped. You rarely want to kill all agents everywhere; you want to kill the affected task, or the affected tool, or runs touching the affected accounts. A switch that can only nuke everything is a switch teams hesitate to use, and hesitation during an incident is itself a failure. The logistics team needed to stop re-routing while leaving the rest of the agent's read-only functions running; an all-or-nothing switch would have over-corrected.
And a real kill switch is tested, on a schedule, like a fire drill, because an untested kill switch is a belief, not a control. The first time you discover your kill switch does not actually stop in-flight runs should not be during the incident it was built for.
Here is the kill-switch design as a runbook, the artifact you write before you need it:
kill_switch:
scopes: [global, by_task, by_tool, by_account, by_run]
modes:
graceful:
effect: "stop accepting new runs; in-flight runs run to next checkpoint then halt"
latency: "seconds to stop intake; in-flight bounded by checkpoint interval"
use_when: "elevated error rate, suspected bad behavior, no active irreversible harm"
hard:
effect: "halt all targeted runs immediately, mid-action; freeze state"
latency: "seconds"
use_when: "active irreversible harm, exfiltration, runaway cost"
triggers:
manual: "on-call can invoke any scope/mode without a deploy"
automatic:
- "cost rate > 3x baseline -> graceful by_task"
- "irreversible-write rate > N/min -> hard by_tool"
- "out-of-scope attempt rate spike -> hard by_task + page security"
- "tool-error rate > threshold -> graceful by_task (the stale-input case)"
after_trip:
- "freeze and checkpoint all affected runs"
- "snapshot traces for the incident window"
- "open incident record automatically"
drill_schedule: "monthly, in staging; quarterly, scoped live test"The automatic triggers are the part that would have saved the logistics company. A tool-error-rate trigger would have tripped a graceful stop when the carrier API started returning stale data, because a spike in one tool's anomalous behavior is exactly the signature of bad input entering the chain. The switch fires at link 1 or 5, automatically, before a human notices, which is the only way to cap an incident that propagates faster than humans react.
Rollback: the saga log earns its keep
Stopping the agent ends the bleeding. It does not undo the four hundred re-routes. Rollback is unwinding the committed actions, and it is only possible if you built for it, which the earlier chapters did, under different names.
The Tool Trust Contract classified every tool's side effects and named the rollback mechanism for every REVERSIBLE-WRITE. The state chapter kept a saga log: the completed_actions list in the task state, each entry recording the tool, the result, the reversibility window, and the compensating action. Together these are the rollback infrastructure. To unwind a run, you walk its saga log in reverse and execute each compensation that is still in its window:
def rollback_run(run):
for action in reversed(run.state.completed_actions):
if action.side_effect_class == "REVERSIBLE-WRITE" and within_window(action):
execute(action.rollback) # e.g. void_refund(refund_id)
log_compensation(run, action)
elif action.side_effect_class == "IRREVERSIBLE-WRITE":
flag_for_human(run, action) # cannot auto-undo; needs manual handling
run.state.status = "ROLLED_BACK"This is the saga pattern from distributed transactions, applied to agent actions: a sequence of local actions, each with a compensating action, unwound in reverse on failure. It is also why the side-effect classification was never optional. Rollback can only auto-undo the REVERSIBLE-WRITEs. The IRREVERSIBLE-WRITEs (the re-routes that already shipped) cannot be undone by code; they get flagged for human handling, and the smaller that pile is, the faster the recovery. This is the operational payoff of gating irreversible actions: every irreversible action you prevented from happening unsupervised is an action you do not have to clean up by hand at 3 a.m.
For the logistics agent, a saga log would have meant that re-routes still cancellable (within the carrier's window) auto-reverse on rollback, and only the ones already shipped land in the human pile. Without the saga log, every one of the four hundred was a manual investigation. The difference between those two mornings is entirely whether the rollback infrastructure existed before the incident.
The agent incident postmortem
After the bleeding stops and the world is unwound, the work that prevents the next incident is the postmortem, and an agent postmortem asks questions a normal service postmortem does not, because the failure involved a system that made its own decisions. I run it against the Incident Chain, link by link, because the chain is the diagnostic frame.
The postmortem template:
| Section | Questions |
|---|---|
| Timeline | When did link 1 enter? When did each subsequent link fire? When did we detect? When did we stop? When was it unwound? (Reconstructed from the trace, which is why observability is non-negotiable.) |
| Chain analysis | At which link did the chain actually start? Which controls existed at each link? Which fired, which should have fired, which were absent? |
| Earliest reachable control | What is the earliest link where a control would have stopped this, and why was it not there? |
| Blast radius | How many actions, of which side-effect classes? How many auto-rolled-back, how many needed manual handling? |
| Detection gap | How long between first harm and detection? What would have alerted sooner? |
| Autonomy verdict | Should this task be demoted on the Autonomy Ladder? Should an action be re-gated? Should a tool be removed? |
| Eval gap | What case was missing from the eval set that would have caught this? (Add it.) |
The "autonomy verdict" row is the one that makes an agent postmortem different and is the most commonly skipped. A normal postmortem ends with "fix the bug." An agent postmortem must also answer whether the agent should have less autonomy than it had, because the incident is evidence about the failure distribution the Autonomy Ladder's promotion criteria depend on. The logistics incident is direct evidence that the re-routing task, at its current rung, fails dangerously when inputs degrade. The right outcome is not just "fix the stale-data handling" but "demote re-routing to require approval when the carrier API shows anomalous patterns, until we trust the input again." Demotion is the postmortem's most underused remedy, and it is the honest one: the agent earned a rung it could not hold, and the response is to take the rung back until it re-earns it.
The "eval gap" row closes the loop to the evals chapter. Every incident is a case your eval set did not cover. Freeze the incident's world state into a fixture, add it to the eval suite, and now the regression is tested forever. An incident you do not turn into an eval case is an incident you have licensed to recur.
Designed failure is the whole book, compressed
Step back and notice that the controls in this chapter are not new. The kill switch is the operational form of the bounded goal's stopping rules. The rollback is the operational form of the Tool Trust Contract's reversibility and the state chapter's saga log. The postmortem's chain analysis maps onto every gate of the BOUND Test. The demotion verdict is the Autonomy Ladder running in reverse. Designed failure is not a separate discipline bolted on at the end; it is what every earlier chapter was quietly building toward, because the entire premise of the book is that autonomy is a liability that must earn its place, and a liability is defined by what happens when it goes wrong.
The logistics company had a great agent and no designed failure, so its worst day was six hours of building response capability while the damage compounded. The same agent with a kill switch, a saga log, monitoring at link 5, and a postmortem habit would have had a five-minute incident and a one-line demotion. The agent did not need to be smarter. It needed a landing zone. That is the D gate, and it is the difference between an incident and a catastrophe.
We have built the whole thing now: when to use an agent, how to bound it, tool it, state it, govern it, gate it, measure it, trace it, secure it, and survive it failing. The conclusion pulls it into a single checklist and makes the argument that has been implicit throughout: the best agents are not the most autonomous. They are the most accountable.