State, Memory, and Context Control
An agent's reliability is bounded by what it can see, what it remembers, and what it carries between steps, all of which you must control deliberately.

State, Memory, and Context Control is the discipline of separating what the agent can see, what it remembers, and what the system treats as authoritative state.
Key Takeaways
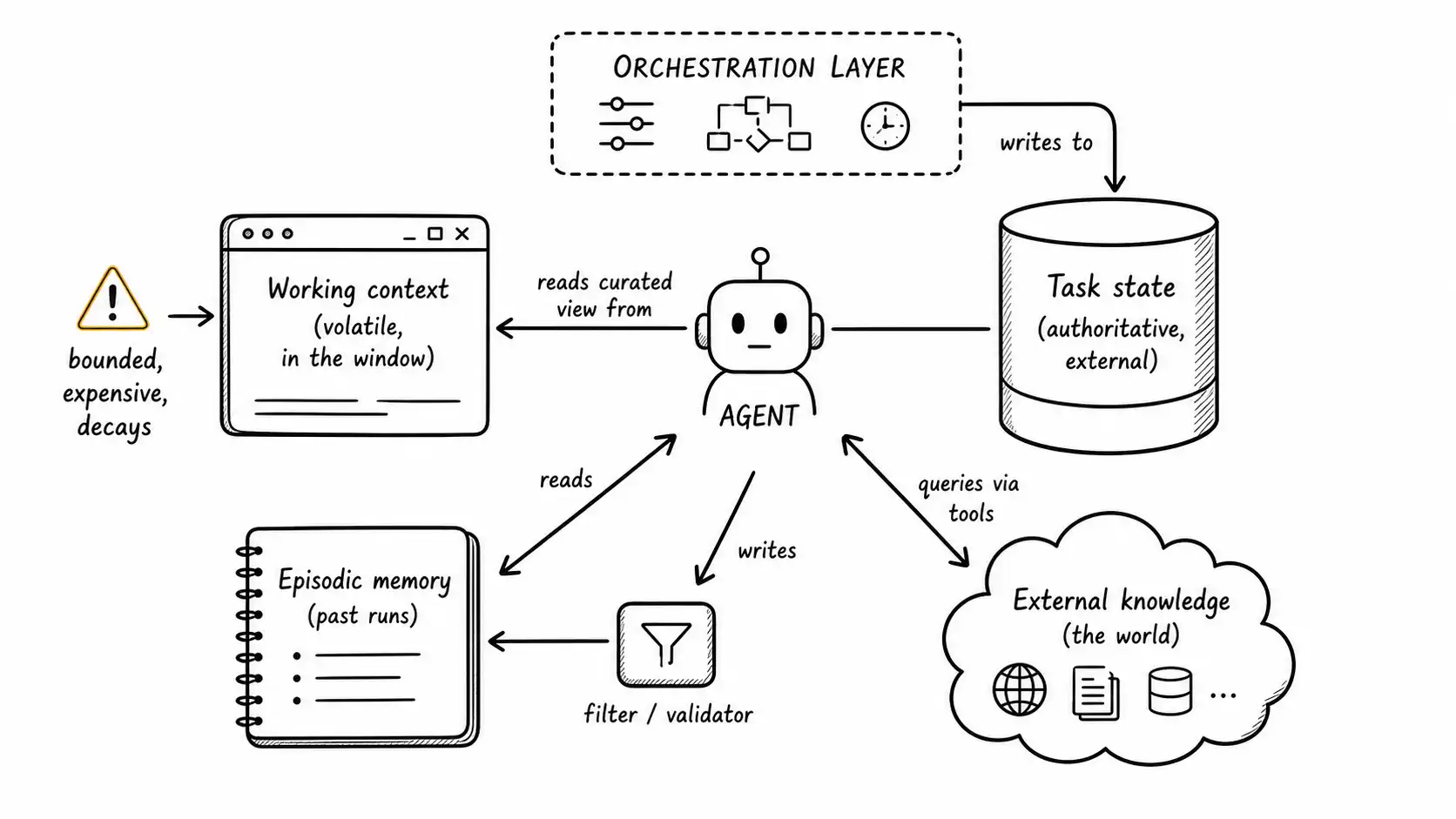
- Separate four kinds of state that "memory" smears together: working context (volatile, in the window), task state (authoritative, external), episodic memory (past runs), and external knowledge (the world). They have different lifetimes, trust levels, and failure modes.
- The context window is a budget to allocate deliberately each step, not a transcript to accumulate. Assemble a small curated view from authoritative task state; do not feed back the raw growing history.
- Make task state an explicit, checkpointable record (a state machine with a saga log of reversible actions), so runs can survive crashes, resume from the last good step, and be cleanly stopped and unwound.
- Treat writes to long-term memory like irreversible writes: gate them with validation appropriate to the stakes, and attach provenance so a poisoned note can be traced and contained.
- Controlled state is the same discipline as observable state. Deterministic, structured context is what makes traces, replay, and budgets actually work.
Read this beside memory systems for agents, planning without wandering, and observability and replay when you turn the chapter into a production design.
Here is a failure that does not look like a failure until you graph it. An agent handling a multi-step research task ran fine for the first eight steps and then started repeating itself: re-running searches it had already run, re-reading documents it had already summarized, and contradicting conclusions it had reached four steps earlier. Nobody had changed the model, the tools, or the prompt. What had changed was the length of the conversation. By step eight, the running transcript had grown past the point where the early findings still fit usefully in context, and the agent, working from a truncated and increasingly muddled view of its own history, lost the thread.
This is a state problem, not an intelligence problem, and it is the most underestimated source of agent unreliability. An agent's behavior at step N is a function of what it can see at step N: its goal, its history, its latest observations, its memory. If you do not control that state deliberately, it controls you, and it tends to do so right when the task gets long and interesting.
Four kinds of state, kept separate
The word "memory" in agent discourse smears together at least four distinct things, and the smearing is the first mistake. Keep them separate, because they have different lifetimes, different trust levels, and different failure modes.
Working context is what is in the model's context window right now: the goal, recent steps, the latest tool results, the instructions. It is volatile, expensive (you pay per token, every step), and bounded by the window. It is also where the agent actually thinks, so what is in it is what the agent knows.
Task state is the structured, authoritative record of where the task stands: which steps completed, what their results were, what the current values of the success conditions are, what the budget counters read. This lives outside the model, in a store you control, as data, not prose. The agent reads from it and the orchestration layer writes to it. It is the source of truth; the working context is a view onto it.
Episodic memory is the record of past runs: what this agent did on previous tasks, what worked, what failed. Reflexion showed that letting an agent keep verbal notes on its own past failures and consult them on later attempts measurably improves performance, and Voyager built a growing skill library across episodes in Minecraft. Episodic memory is powerful and dangerous in equal measure, because a wrong memory poisons every future run that reads it.
External knowledge is the world the agent queries: databases, documents, APIs, search. It is not the agent's memory at all; it is state the agent observes through tools, and it is governed by the Tool Trust Contract, not by the memory system.
The discipline is to never let these blur. Task state is not working context (do not trust the transcript to remember what step three returned; read it from the store). Episodic memory is not external knowledge (a note the agent wrote about itself is not a fact about the world). The research agent that lost the thread blurred working context and task state: it treated the conversation transcript as its authoritative record of progress, and when the transcript got truncated, its record of progress got truncated with it.
The context window is a budget, spend it on purpose
The naive agent loop appends everything to a running transcript and feeds the whole thing back to the model every step. This works for short tasks and falls apart for long ones, for three reasons that compound.
First, cost. You pay for every token in context, every step. A transcript that grows linearly makes a task's cost grow quadratically, because each of N steps reprocesses an O(N) transcript. The cost-and-latency chapter quantifies this; here, the point is that the transcript-everything loop has a cost curve that bends the wrong way exactly as the task gets valuable.
Second, the relevant information gets diluted. As the transcript grows, the goal and the critical early findings become a smaller and smaller fraction of the context, competing with stale intermediate chatter. Models attend imperfectly across long contexts, and the practical effect is that the agent's grip on its own goal weakens as the task lengthens. The research agent's contradiction of its own earlier conclusions was this dilution in action.
Third, truncation is silent and arbitrary. When the transcript exceeds the window, something gets dropped, and unless you chose what, the something is whatever fell off the end of your truncation rule, often the early findings that mattered most.
The fix is to treat the context window as a budget you allocate deliberately each step, not a transcript you accumulate. Each step, the orchestration layer constructs the working context from the authoritative task state: the goal (always), the current success-condition values (always), a curated summary of progress (not the raw transcript), the last one or two tool results in full, and whatever retrieved knowledge this step needs. The raw history lives in task state and the trace; the working context holds a deliberately chosen view. This is sometimes called context engineering or context curation, and it is the single highest-use thing you can do for long-running agent reliability.
Task state as a state machine you can checkpoint
The authoritative answer to "where is this run?" should be a structured object, not a transcript. I model task state explicitly, often literally as a state machine with a typed record, because that makes it checkpointable, replayable, and resumable. Borrowing from durable execution systems like Temporal, the principle is that every meaningful step's effect is persisted, so the run can survive a crash and resume from the last good point rather than starting over.
A minimal task-state record for the onboarding agent:
{
"run_id": "run_8f21",
"task": "provision_enterprise_customer",
"contract_version": 3,
"status": "IN_PROGRESS",
"step": 6,
"success_conditions": {
"account_active": true,
"sso_configured": false,
"billing_verified": true,
"welcome_sent": false
},
"completed_actions": [
{"step": 2, "tool": "create_account", "result": "ok", "reversible_until": "2026-06-14T10:00:00Z"},
{"step": 4, "tool": "set_billing_plan", "result": "ok", "rollback": "revert_plan(...)"}
],
"budget": {"steps_used": 6, "tool_calls": 9, "cost_usd": 0.41},
"checkpoint_id": "ckpt_6",
"open_questions": ["SSO metadata missing entityID field"]
}This record does real work. The success_conditions block is the checkable goal from the task contract, evaluated against ground truth, so the system (not the agent) decides when the task is done. The completed_actions block, with its per-action reversible_until and rollback, is the live saga log: if the run aborts at step 6, the orchestration layer knows exactly which reversible writes to compensate and which window they are in. The checkpoint_id lets the run resume after a crash from step 6 rather than re-running steps 2 through 5, which matters enormously when those steps had irreversible or expensive effects you must not repeat. And open_questions carries the ambiguity forward in structured form, so an escalation hands the human the actual blocker rather than a transcript to read.
Checkpointing is not just crash recovery. It is the substrate for the kill switch and the rollback runbook later in the book: you cannot cleanly stop and unwind an agent whose only record of what it did is a chat transcript. You can cleanly stop and unwind one whose every committed action sits in a structured, compensable log.
Memory you write back is a liability you must validate
Episodic memory is the feature that turns a stateless agent into one that learns from its runs, and it is the feature most likely to create a slow, invisible failure. The mechanism is simple: the agent writes notes about what it learned, and future runs read those notes. The danger is equally simple: if the agent writes a wrong note, every future run that reads it inherits the error, and because the note looks like learned wisdom, nobody questions it.
I treat writes to long-term memory with the same suspicion as IRREVERSIBLE-WRITE tools, because that is effectively what they are: a write to state that future runs will trust. So memory writes go through a validation gate. A note is not committed because the agent decided it was true; it is committed if it passes a check appropriate to the stakes: a schema constraint, a consistency check against existing memory, a human review for high-impact memory, or a confidence threshold. Low-stakes memory (this customer prefers email over phone) can have a light gate. High-stakes memory (this account is exempt from refund caps) needs a heavy one, or it should not be agent-writable at all.
The reads matter too. When the agent retrieves a memory, the memory carries provenance: when it was written, by which run, with what confidence, and whether it has been validated. The agent's instructions treat a validated memory as more trustworthy than an unvalidated one, and the trace records which memories influenced which decisions, so that when a run goes wrong you can find the poisoned note that misled it. Memory without provenance is a debugging dead end; you will see the agent make a confident wrong choice and have no idea which remembered "fact" caused it.
A decision table for what goes where
When you are designing an agent, every piece of information it touches has a right home. Putting it in the wrong place is the root of a whole class of bugs. Here is the routing I use.
| Information | Lives in | Why | Failure if misplaced |
|---|---|---|---|
| The goal and scope | Task contract, injected into working context every step | Must never decay or drop | Agent loses the thread on long tasks |
| What step we are on and results | Task state (external, authoritative) | Survives truncation and crashes | Repeated work, contradictions, no recovery |
| Last 1-2 tool results, in full | Working context | Needed for the immediate decision | Agent acts on stale or summarized data |
| Summary of earlier progress | Working context (curated), full version in task state | Keeps context small and focused | Cost explosion, dilution |
| Facts about the world | External knowledge, via tools | The world is authoritative, not the agent | Agent trusts its own stale guess as fact |
| Lessons across runs | Episodic memory, gated on write, with provenance | Learning without poisoning | Silent error propagation across runs |
The unifying rule: the model's working context is a small, deliberately curated view assembled fresh each step from authoritative external state. The model is a reasoning engine operating on a view, not a database that remembers things. The moment you start trusting the transcript as your record of truth, you have signed up for the research agent's slow unravel.
Context control is an observability feature too
There is a payoff for all this discipline that shows up in the next chapter. An agent whose working context is assembled deterministically from structured task state, rather than accumulated as an opaque transcript, is an agent you can actually trace and replay. You can record exactly what view the agent saw at step 6, reconstruct it, and re-run the decision. You can answer "where did the plan change?" because the state at every step is a structured snapshot, not a smear of tokens. The O gate of the BOUND Test and the state discipline of this chapter are the same discipline viewed from two angles: control the state and you can observe it; let it sprawl and you can do neither.
Controlled state is also what makes the budget real. The budget counters in the task-state record are the live values the stopping rules check. An agent that does not track its own resource consumption in authoritative state cannot enforce a budget, and an agent that cannot enforce a budget is the wandering loop from the bounded-goals chapter. State, budget, and stopping are one system.
We have the goal bounded, the tools contracted, and the state controlled. What remains is the part everyone thinks of as the agent: the loop where it plans and acts. And the central risk of that loop is the one the research agent showed us in miniature, the agent that keeps going, keeps deciding, keeps spending, without converging. The next chapter is about planning that ends.