Human Handoffs and Approvals
Approval gates earn their keep only when they intercept the right actions, give the human enough to decide, and do not become a rubber stamp.

Human Handoffs and Approvals only make agents safer when the gate catches the right actions and gives the reviewer enough evidence to decide.
Key Takeaways
- A badly designed human gate is worse than none: it manufactures the appearance of oversight while rubber-stamping under load. Intercept selectively (irreversible and out-of-envelope actions) so the gate fires rarely and gets real attention.
- Hand the human a decision packet, not a transcript: the action in plain language, the agent's reasoning, the evidence, the reversibility and blast radius, and a calibrated recommendation. Rejection is only real if the human has enough to reject.
- Every gate needs a timeout that fails closed. Auto-approving on timeout disables the control exactly when load makes it most necessary.
- Capture every approval and rejection with reasons. The gate becomes an eval source and a promotion engine; it generates the measured success rate and failure distribution the Autonomy Ladder requires.
- The escalation handoff must transfer state (saga log, open questions, trace), not just a flag, so a human can continue the task rather than restart it. Put humans where judgment is decisive, not where volume drowns it.
Read this beside Human in the Loop Is Not a Plan, evaluating agent runs, and human-in-the-loop evaluation when you turn the chapter into a production design. For governance language, use NIST AI RMF as the external reference point.
A bank I advised put a human approval step in front of its loan-document agent. Every action the agent proposed went to a reviewer who clicked approve or reject. Leadership was proud of the control. Then I watched the reviewers work. They were processing an action every four seconds, approving a stream of proposals they could not possibly be reading, because the queue was three hundred deep and growing. The approval gate existed. It approved everything. It was a rubber stamp with a salary, and it gave everyone the false comfort of a control that was not controlling anything.
This is the central problem with human-in-the-loop for agents, and it is not the problem the discourse worries about. The discourse worries about whether to have a human in the loop. The real problem is that a badly designed human gate is worse than no gate, because it manufactures the appearance of oversight while delivering none, and it does so right up until the incident, at which point everyone discovers the human was a formality.
So this chapter is not "add a human." It is how to design a handoff that actually intercepts the right decisions, gives the human what they need to decide well, and does not collapse into a rubber stamp or a bottleneck. The approval gate is the bridge between the Autonomy Ladder's rung 4 and rung 5, and like everything else in this book, it has to earn its place.
Approve the action that matters, not every action
The loan agent's mistake was approving everything, which guarantees that nothing gets real attention. The fix is selective interception: the gate fires on the actions where human judgment changes the outcome and waves through the ones where it does not. The Tool Trust Contract already told you which actions those are. The side-effect class and the autonomy condition decide whether an action needs a human.
The routing is mechanical, which is the point. A human should never decide whether something needs approval; the contract decides, deterministically, and the human decides only the things that reach them.
| Action class | Default gate | Rationale |
|---|---|---|
| READ tool | No approval | Observes, changes nothing, cheap to be wrong |
| REVERSIBLE-WRITE inside autonomy envelope | No approval | Bounded and undoable; that is what the envelope means |
| REVERSIBLE-WRITE outside envelope | Approval | Reversible but high-stakes (enterprise plan change) |
| IRREVERSIBLE-WRITE | Approval, always | Cannot be undone; the model's runtime plan is the one thing unreviewed |
| Out-of-scope action attempt | Escalate, never auto-approve | A scope violation is a signal, not a request |
This single table dissolves the rubber-stamp problem at the source. If the loan agent had routed only its irreversible and out-of-envelope actions to humans, the queue would have been a fraction of the size, each item would have warranted attention, and the reviewers could have actually reviewed. A gate that fires rarely and meaningfully gets read. A gate that fires constantly gets rubber-stamped. The design choice is volume, and volume is controlled by what you choose to intercept.
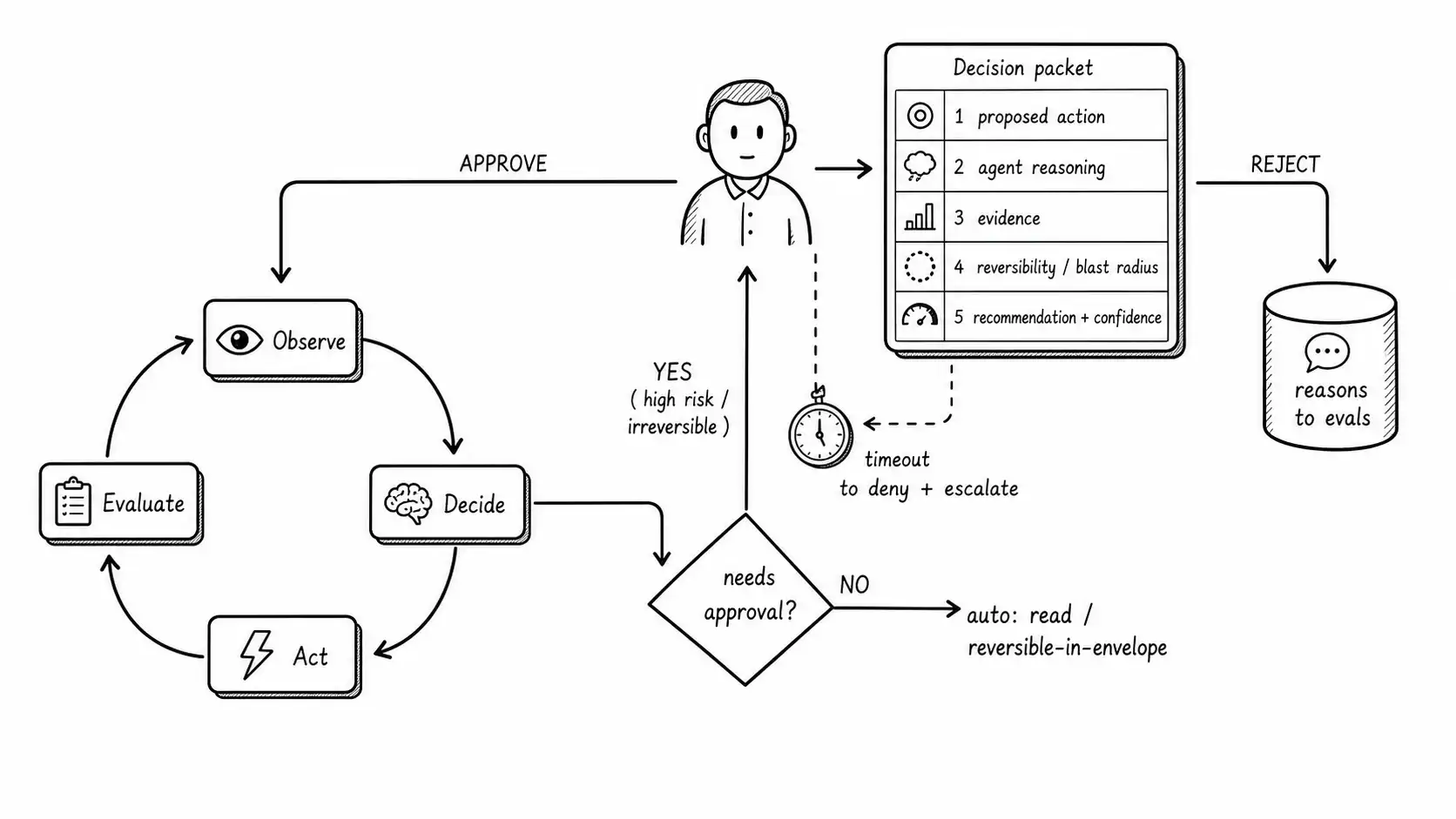
The human needs a decision packet, not a transcript
When an action does reach a human, what they see determines whether their judgment is real or theater. The loan reviewers saw a proposed action and an approve button. They had no context, so they had no basis to reject, so they approved. A good approval gate hands the human a decision packet: everything needed to make the call in the time available, and nothing that buries it.
A decision packet has five parts:
- The proposed action, in plain language. "Issue a $1,200 refund to account #48213 (Acme Corp, enterprise tier) for transaction #T-9981, reason: overcharge." Not a JSON blob. The actual consequence in words.
- Why the agent proposes it. The agent's reasoning, summarized: "Customer reports being charged twice; transaction #T-9981 and #T-9980 are identical except for timestamp 4 seconds apart; #T-9981 appears to be the duplicate." This is the agent's case, and the human is judging the case, not the action in isolation.
- The evidence. Links or snapshots of the underlying state the agent relied on: the two transactions, the account tier, the relevant policy. The human can verify the agent's claims rather than trusting them.
- The reversibility and blast radius. "This refund is reversible within 24 hours via void_refund. It will also send an irreversible confirmation email to the customer." The human needs to know what they cannot take back, especially the cascading irreversible effects the side-effect review surfaced.
- The recommended decision and its confidence. "Recommend approve, confidence high." A calibrated confidence signal lets the human triage attention: spend the scarce review time on the low-confidence cases, move faster on the high-confidence ones, without rubber-stamping either.
The decision packet is the difference between a human who can meaningfully reject and a human who can only approve. The loan reviewers could only approve because rejection required information they did not have. Give them the packet and rejection becomes a real option, which is the only thing that makes approval mean anything.
The gate needs a timeout, and the timeout fails closed
An approval gate introduces a new failure mode: the human never responds. The reviewer is on vacation, the queue is backed up, the notification got lost. An agent run that blocks forever on an approval is a stuck run, and a system full of stuck runs is its own incident. So every gate needs a timeout, and the timeout must fail closed: if the human does not respond in the window, the action is denied and the run escalates further (to a backup approver, to on-call, to a hold queue), never auto-approved.
Failing closed is non-negotiable and frequently gotten wrong. The tempting design under load is to auto-approve on timeout so the queue does not back up. That design converts your approval gate into a delayed rubber stamp: under exactly the conditions where review matters most (high load, backlog), the gate stops reviewing. The bank's four-second approvals were a human version of fail-open; a timeout-auto-approve gate is the automated version, and it is worse because it hides even the appearance of a human. If the queue backing up is the problem, the answer is to intercept fewer actions or add reviewers, not to disable the control when it is most needed.
Rejection is data, and the gate is an eval source
Here is the part most teams miss: every human decision at the gate is a labeled example, and the labels are free. When a reviewer rejects a proposed refund, that rejection plus its reason is a data point about where the agent's judgment diverges from a human's. Capture it. A gate that routes approvals and rejections into a structured store, with reasons, builds an eval set as a byproduct of operating, and that eval set is more valuable than anything you could construct synthetically, because it is exactly the distribution of real cases your agent faces.
This connects the approval gate to the Autonomy Ladder's promotion criteria. To promote the refund agent from rung 4 (approve every refund) to rung 5 (auto-approve refunds under $50), you needed a measured success rate and a characterized failure distribution. The approval gate produced both: over 1,200 tickets, the agent's proposal matched the human's decision 98.5 percent of the time, and the 1.5 percent of rejections clustered in a specific, describable region (enterprise accounts, refunds over a threshold). The gate did not just control the agent; it generated the evidence to safely loosen its own control. A gate that captures rejections is a promotion engine. A gate that only clicks approve, like the bank's, generates nothing and can justify no promotion, which is why those teams stay stuck at rung 4 forever, manually approving a stream they cannot read.
A human approval policy, as an artifact
Pulling this together into something a team can adopt, here is an approval policy template. It is the artifact that answers, for a given agent, who approves what, with what packet, in what window, and what happens on timeout.
approval_policy:
agent: support_refund_agent
version: 4
gates:
- trigger: "irreversible_write OR (reversible_write AND outside_envelope)"
packet: [action_plain, agent_reasoning, evidence_links, reversibility, recommendation_confidence]
approver_role: "tier-2 support lead"
timeout_sec: 900
on_timeout: "deny + escalate to backup approver; never auto-approve"
capture: "decision, reason_code, reviewer_id -> eval_store"
- trigger: "out_of_scope_attempt"
packet: [action_plain, scope_rule_violated, agent_reasoning, evidence_links]
approver_role: "security on-call"
timeout_sec: 300
on_timeout: "abort run + freeze state; never auto-approve"
capture: "incident_record"
envelope: # what runs WITHOUT a gate
reversible_write_auto:
condition: "refund AND amount_usd <= 50 AND account.tier!= enterprise"
still_logged: true
rubber_stamp_guard:
max_auto_throughput_per_reviewer_per_hour: 60
alert_if_median_review_time_below_sec: 20The rubber_stamp_guard block is the part born directly from the bank. It instruments the gate's own health: if a reviewer is approving more than one a minute or median review time drops below twenty seconds, the system alerts, because those are the signatures of a gate that has stopped reviewing. You monitor the human control the same way you monitor the agent, because a control you do not monitor is a control you do not have. The four-second approvals would have tripped this guard on day one, and the conversation would have happened before the incident instead of after.
Handoff is not only approval: the escalation handoff
Approval is one kind of handoff, where the agent proposes and the human disposes. There is a second kind that matters as much: the escalation handoff, where the agent reaches a boundary it cannot cross (ambiguity it cannot resolve, a scope it cannot enter, a no-progress landing from the governor) and hands the whole task to a human to continue. The quality of this handoff determines whether escalation is a graceful transfer or a frustrating dead end.
A good escalation handoff transfers state, not just a flag. The human who picks up an escalated onboarding run should receive the task-state record: what is done, what reversible actions are outstanding and until when, the open question that blocked the agent ("SSO metadata is missing the entityID field"), and the trace if they want to dig. They continue the task from where the agent left it, with full context, rather than starting over from a ticket that says "agent gave up." This is why the state chapter insisted that escalations carry the open_questions block and the saga log: the escalation handoff is only as good as the state it transfers, and an agent whose only state is a transcript hands off a transcript, which is to say nothing useful.
The two handoffs share a design principle. In both, the human is most valuable when they are given a small number of high-stakes decisions with rich context, and least valuable when they are given a high volume of low-context approvals. Design the handoff to put humans where their judgment is decisive and keep them out of where it is not. That is the difference between human-in-the-loop as a control and human-in-the-loop as the bank's salaried rubber stamp.
We now have the agent bounded, tooled, stated, governed, and gated. The remaining question is whether any of it actually works, which is to say: how do you measure an agent, when the thing you are measuring generates a different path every time? That is the evals chapter, and it is where leaderboard optimism goes to die.