Planning Without Wandering
The agent loop is where autonomy lives and where it runs away, so it needs budgets, convergence checks, and a forced landing.

Planning Without Wandering means wrapping the agent loop in budgets, convergence checks, and a forced landing the model cannot override.
Key Takeaways
- The characteristic failure of the agent loop is not a wrong action but no convergence: wandering. The bare ReAct loop has no reason to stop, so the loop you ship is ReAct plus a governor the model cannot override.
- Enforce four independent budgets (steps, tool calls, cost, wall clock) in the governor, not the prompt. Each catches a different shape of wandering, and a model can rationalize past a prompt-level limit.
- Budgets stop runaway loops; add a no-progress detector (no success condition flipped, no new information) and a repetition detector (same call, same state) to catch loops that spin without progressing.
- Use plan-then-execute for inspectability at high-stakes decision points and react-and-revise for adaptability during execution, governed throughout. Decomposition needs hierarchical, conserved budgets and a real task contract per sub-agent.
- A forced landing is a healthy outcome. It converts a silent, unbounded wandering failure into a loud, attributable escalation with state intact, which is exactly the signal the team needs.
Read this beside the autonomy ladder, observability and replay, and agentic workflows when you turn the chapter into a production design.
I once watched an agent spend $340 trying to book a meeting room. The task was trivial: find an open room for six people on Thursday afternoon and reserve it. The room-booking API was flaky that day, returning intermittent timeouts. The agent, reasoning sensibly each step, kept trying: query availability, timeout, reason about the timeout, try a different room, timeout, reason about that, broaden the search, query again. Each individual decision was defensible. The aggregate was a loop that ran for ninety minutes and a thousand tool calls before someone noticed the spend alert. The agent never did anything irreversible. It just never stopped.
This is wandering, and it is the characteristic failure of the agent loop. Not a wrong action, but no convergence: an agent that keeps planning, keeps acting, keeps spending, and never lands. The wandering agent is the dark side of the property that makes agents useful. Because the path is generated at runtime, the loop can generate paths forever. Planning that works is planning that ends.
The honest agent loop has a governor
The minimal ReAct loop, reason then act then observe then repeat, has no built-in reason to stop. It stops when the model decides it is done, and a model that cannot make progress will not reliably decide it is done; it will keep reasoning about why it is stuck and trying one more thing. So the loop you ship is not the loop in the paper. It is the loop in the paper plus a governor: a control layer that the model does not get to override, which enforces budgets, detects non-convergence, and forces a landing.
The governor sits outside the model's reasoning. This separation is the whole point. If the stopping logic is something you ask the model to respect in its prompt ("stop after ten steps"), the model can rationalize past it, because the same reasoning that makes it capable makes it good at arguing it should continue. The budget must be enforced by code the model cannot talk its way around. The room-booking agent had its budget in the prompt. The prompt said "be efficient." The governor said nothing because there was no governor.
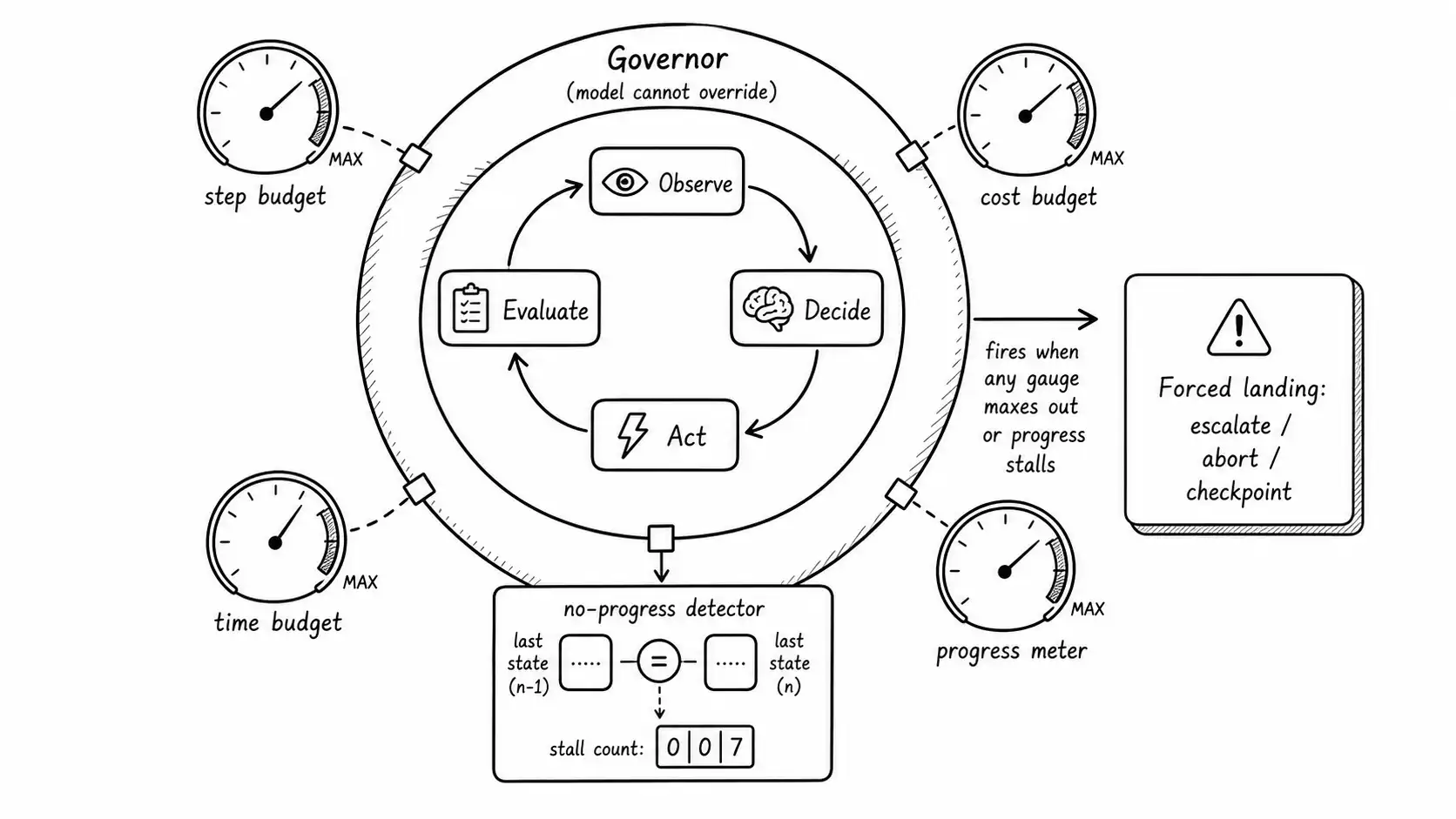
Four budgets, because one is never enough
The bounded-goals chapter put four fuses in the task contract. This is where they earn their place, because each catches a different shape of wandering.
Step budget caps the number of loop iterations. It is the coarsest fuse and the one most likely to fire on a genuinely stuck agent. The room-booking loop would have hit a sane step budget (say, 15 iterations) in under a minute.
Tool-call budget caps total tool invocations, which can outrun the step budget when a single step fans out into many calls. A research step that issues twelve searches is one step and twelve tool calls.
Cost budget caps spend directly, in dollars, and it is the fuse that matters most to whoever signs off on the project. Steps and calls are proxies for cost; cost is cost. Track it in the task state and check it every step. The $340 room booking is a cost-budget failure with a $5 budget that did not exist.
Wall-clock budget caps elapsed time, which matters when an agent's actions have real-world deadlines (a customer waiting, a market window, a downstream timeout). An agent that converges correctly in two hours has still failed a task the customer expected resolved in two minutes.
The four are independent because wandering takes different shapes. A flaky-tool loop blows the step and call budgets first. An expensive-reasoning loop blows the cost budget first. A slow-but-progressing task blows the wall-clock budget while the others look fine. You want all four, and you want them in the governor, not the prompt.
Budgets stop runaway loops; they do not detect stuck loops
A budget catches the agent that runs too long. It does not catch the agent that runs in a circle and would eventually hit the budget but is wasting every step until then. For that you need a no-progress detector: a check that asks, each step, whether the agent is actually getting closer to the goal, and that escalates when the answer has been no for too long.
Progress is measurable when your goal is a set of checkable success conditions, which is exactly why the bounded-goals chapter insisted on them. The detector compares the success-condition state across recent steps. If the agent has taken three steps and no success condition has flipped from false to true, and no new information has entered the task state, it is not progressing; it is wandering, and the detector trips. The room-booking agent never flipped its one success condition (room_reserved) across a thousand calls. A no-progress detector with a threshold of, say, five non-progressing steps would have caught it almost immediately, long before the cost budget.
A more refined detector watches for repetition: the same tool called with the same arguments, the same reasoning recurring, the same state revisited. The research agent from the state chapter, re-running searches it had already run, is the textbook case. Detecting repetition is cheap (hash the tool call and the relevant state, keep a set, flag a repeat) and it catches the most common wandering pattern, the loop that has lost track of what it already tried because it lost track of its own state.
# Governor check, run every step, outside the model's control
def governor_check(state, history):
# 1. Hard budgets
if state.budget.steps_used >= contract.max_steps: return STOP("budget_steps")
if state.budget.tool_calls >= contract.max_tool_calls: return STOP("budget_calls")
if state.budget.cost_usd >= contract.max_cost_usd: return STOP("budget_cost")
if elapsed(state) >= contract.max_wall_clock_sec: return STOP("budget_time")
# 2. No-progress detector
if steps_since_last_progress(state) >= NO_PROGRESS_LIMIT: return STOP("no_progress")
# 3. Repetition detector
sig = hash(last_tool_call(history), relevant_state(state))
if sig in history.seen_signatures: return STOP("repetition")
history.seen_signatures.add(sig)
return CONTINUESTOP here does not mean crash. It means trigger the forced landing, which routes through the task contract's stopping rules to a terminal state: ESCALATE with the reason, or ABORT with rollback. The model is not asked whether it agrees. The governor decides; the contract routes.
Planning style: plan-then-execute versus react-and-revise
There are two broad shapes for how an agent forms a plan, and the choice affects wandering.
Plan-then-execute has the agent draft a full plan up front, then execute the steps, optionally re-planning if a step fails. The advantage is that the plan is inspectable before any action happens, which is gold for approval gates: a human can review the plan before the agent touches anything. The disadvantage is that a plan made before contact with the world is often wrong, because agents earn their keep precisely when the world does not hold still, so rigid plan-then-execute either fails on the first surprise or re-plans so often that you are back to react-and-revise with extra steps.
React-and-revise (the ReAct shape) interleaves reasoning and action, deciding the next step based on the latest observation. It adapts naturally to a changing world, which is the whole reason to use an agent. Its weakness is exactly the wandering this chapter is about: without a governor, react-and-revise has no natural endpoint.
The practical answer is a hybrid governed by stakes. For high-stakes runs, have the agent produce an explicit plan, route it through an approval gate (next chapter), then execute with react-and-revise inside the approved plan's scope, re-escalating if it needs to leave that scope. You get the inspectability of plan-then-execute at the decision point that matters and the adaptability of react-and-revise during execution, with the governor ensuring that the revising does not become wandering. For low-stakes runs, skip the upfront plan and lean on the governor and budgets alone. The plan is a control surface for human review, not a religious commitment.
Decomposition helps until it multiplies
A popular move for hard tasks is decomposition: break the goal into subgoals, possibly spawn sub-agents to handle them. Done well, this is genuinely useful; a bounded subgoal is easier to keep bounded than a sprawling parent goal. Done badly, it is a wandering multiplier, because each sub-agent has its own loop, its own budget, and its own opportunity to wander, and the parent agent now has to evaluate sub-agent results it cannot fully observe.
Two rules keep decomposition honest. First, budgets are hierarchical and conserved: a sub-agent's budget is carved out of the parent's, not added on top, so spawning sub-agents cannot increase total spend beyond the parent's cap. The room-booking agent multiplied across three sub-agents is a $1,020 room booking. Second, a sub-agent is an agent, which means it needs its own task contract, its own success conditions, and its own forced landing. A sub-agent without a contract is a budget leak with extra steps. If you cannot write a bounded task contract for the subgoal, the subgoal is not ready to be delegated to a sub-agent, and you should keep it inline where the parent's governor watches it.
The multi-agent literature (frameworks like AutoGen formalize multi-agent conversation) makes choreography easy and makes it easy to forget that every agent in the choreography is a loop that can run away. The governor discipline applies recursively or it does not apply at all.
The forced landing is a feature, not an admission of failure
When the governor trips, the run ends somewhere named. This is the connection to the D gate, designed failure. A run that lands in ESCALATE because it hit the no-progress detector is not a failed run in the way that matters; it is a run that correctly recognized it was stuck and handed off to a human with its state intact, its reversible actions still reversible, and its open question documented. That is a good outcome. The bad outcome is the run that would have wandered for ninety minutes if a human had not happened to see an alert.
So I measure forced landings as a first-class metric, and I want the distribution to be healthy: most runs land in SUCCESS, a meaningful minority land in ESCALATE for legitimate reasons (genuine ambiguity, needed approval, real blockers), and ABORT is rare and investigated. A spike in no-progress escalations on a particular task is a signal: the task is harder than the agent can handle, or a tool has gotten flaky, or the goal is mis-bounded. The forced landing turns a silent wandering failure into a loud, attributable signal you can act on. The room-booking agent, governed, would have produced one ESCALATE("no_progress") and one alert that said "room-booking API is flaky," which is exactly the information the team needed and exactly the information the ungoverned loop buried under a thousand tool calls.
Putting it together: the governed loop
The loop that survives production is the ReAct loop wearing four pieces of armor:
- A task contract that defines the goal, scope, terminal states, and the four budgets (from the bounded-goals chapter).
- Controlled state so the loop reasons from a clean, authoritative view and can detect repetition and progress (from the state chapter).
- A governor that enforces budgets, runs the no-progress and repetition detectors, and forces a landing, outside the model's control (this chapter).
- A forced landing that routes every trip through the contract's stopping rules to a named terminal state with state intact (this chapter, completed by the incidents chapter).
None of this makes the agent less capable at the task it can do. It makes the agent unable to fail in the one way that has no upper bound on cost: running forever, spending forever, never landing. Capability comes from the model. Convergence comes from the governor. You need both, and only one of them is the model's job.
The governor decides when to stop the agent acting on its own. The next question is what happens when the agent should not act on its own at all, when the right move is to hand the decision to a human. That is the approval gate, and it is where bounded autonomy meets human judgment.