The First-Draft Factory
The meeting felt successful because the dashboard was full.

An AI-native first-draft factory is what happens when generative AI increases artifact volume faster than an organization can accept, measure, and own the work. The useful question is not "how many more drafts did we produce?" It is "how much more accepted work reached the customer, the product, or the business decision?"
The meeting felt successful because the dashboard was full.
A mid-market software company had spent ninety days rolling out generative AI across sales, support, product, marketing, and engineering. The CEO opened the quarterly operating review with the numbers everyone expected to celebrate.
Sales development representatives had generated 41 percent more outbound messages. Support agents had responded to 28 percent more tickets per shift. Product managers had produced twice as many requirement drafts. Engineers had opened more pull requests. Marketing had a backlog of campaign variations that would have taken a full quarter to produce the year before.
The room liked the numbers. The board liked the numbers. The slide title was "AI Productivity Lift."
Then the COO asked a quieter question: "How much of this shipped?"
The answer was less exciting. Sales replies had not improved. The best account executives were rewriting most of the generated outreach because the drafts were plausible but generic.
Support deflection rose, but reopened tickets rose too, because the AI-assisted answers often solved the visible symptom without resolving the customer's underlying problem. Product managers were producing more PRDs, but engineering leads complained that the documents looked complete while leaving harder tradeoffs unresolved.
Engineers were moving faster on small changes and slower on unfamiliar code paths because review time had increased. Marketing shipped more variants, but brand review had become a bottleneck because the volume of acceptable-sounding copy exceeded the team's ability to judge it.
The organization had built a first-draft factory. It had not yet built an AI-Native operating model.
A first-draft factory is what happens when AI is added to existing work without redesigning the workflow around acceptance. It produces visible artifacts at lower marginal cost. It feels useful because the early metric is output volume: more emails, more summaries, more proposals, more code, more answers, more analysis.
But unless the organization redesigns judgment, the cheap output piles up in front of the same review gates that constrained the old process. In the best case, the gains are partial. In the worst case, the company becomes faster at generating work that someone else must reject.
The first lesson of AI-native design is that output is not outcome. The machine can reduce the cost of production while increasing the cost of acceptance.
Key Takeaways
- AI-added work increases artifact volume; AI-native work redesigns acceptance, risk, and learning around machine output.
- Productivity evidence is jagged: support workflows, bounded coding tasks, and expert work in familiar repositories show different results.
- The scarce resource after production gets cheap is judgment, not drafts, prompts, seats, or dashboards.
- The Output-to-Outcome Ledger keeps teams from celebrating generated work before accepted value improves.
The trap of artifact productivity
Most management systems are biased toward counting artifacts because artifacts are visible. Tickets closed. Messages sent. Pull requests opened. Documents drafted.
Calls summarized. Campaigns generated. Pages produced. These are easy to count, and AI makes many of them easier to increase.
The problem is that artifacts are intermediate. They are evidence that work happened, not evidence that the right thing happened.
A support answer is not a resolved customer issue. A generated sales email is not pipeline. A code patch is not a safe product change. A requirement document is not a decision.
A meeting summary is not organizational alignment. A legal clause is not an acceptable contract position. A dashboard is not insight.
AI-added thinking confuses the artifact with the value. It asks, "How many more artifacts can we produce if every worker has an AI assistant?" AI-native thinking asks, "Which artifacts should still exist, which decisions do they support, which machine-produced artifacts can be accepted automatically, and where must human judgment move?"
The difference is not semantic. It changes what the organization measures and therefore what it becomes.
Consider customer support. A company can add an AI writing assistant to the existing ticket queue. Agents still receive tickets, search the knowledge base, draft responses, send replies, and escalate when stuck.
The assistant helps produce faster responses. That is AI-assisted support. It may help. But it leaves the shape of support untouched.
An AI-native support operation starts earlier. It redesigns intake so the machine classifies intent, detects account state, retrieves relevant policy, drafts a response, identifies whether the answer can resolve the issue, checks confidence against a resolution standard, routes low-confidence cases to humans, samples machine-handled cases for quality review, and turns unresolved patterns into knowledge-base updates. The human role moves from typing every answer to designing the resolution standard, handling exceptions, judging edge cases, coaching the system, and owning the customer outcome.
The same distinction applies in software engineering. Code completion is AI-assisted. A machine-first implementation flow where humans define intent, acceptance tests, architectural constraints, security boundaries, review rubrics, and deployment gates is closer to AI-native.
The machine writes more of the code, but the human must become stricter about what counts as a valid change. That is the core move in evals that predict production: make the acceptance standard explicit before the output volume rises.
The evidence is jagged, not universal
The research on generative AI productivity should make leaders more careful, not more simplistic. Brynjolfsson, Li, and Raymond's widely cited study, "Generative AI at Work", found meaningful productivity gains in a customer-support setting, especially for less experienced workers. The strongest lesson from that work is not merely that AI made agents faster. It is that the tool redistributed useful patterns from more experienced workers to less experienced workers inside a workflow where output quality could be observed and corrected.
That result does not automatically transfer to every domain. Peng et al.'s controlled experiment on GitHub Copilot reported that developers completed a specific programming task substantially faster with AI assistance, but the task was bounded and measurable: implement an HTTP server in JavaScript under experimental conditions (arXiv:2302.06590). A later METR randomized controlled trial in 2025 looked at experienced open-source developers working in repositories they knew well and found that allowing AI tools increased task completion time in that setting (METR study, arXiv:2507.09089). The METR authors were careful about scope, but the result is strategically important: AI gains depend on task boundary, context, worker skill, codebase familiarity, review burden, and the cost of verifying output.
This is the jagged frontier of AI at work. Some tasks fall inside the model's useful capability boundary. Others sit just outside it, where the output looks plausible enough to invite trust but unreliable enough to demand expensive review. Dell'Acqua and coauthors describe this uneven capability boundary in "Navigating the Jagged Technological Frontier", a phrase that has become one of the clearest ways to discuss why AI can create and destroy value depending on task fit.
That evidence should change how executives talk about AI-native adoption. The right question is not "Does AI increase productivity?" The right question is "For which task, with which context, under which evaluation regime, for which worker, at what review cost, with what consequence if wrong?"
A company that refuses that specificity will confuse local wins with general doctrine. It will take a successful support-assist rollout and assume the same playbook applies to legal review, production code, financial forecasting, medical triage, or enterprise sales negotiation. It will count generated artifacts where it should count accepted outcomes.
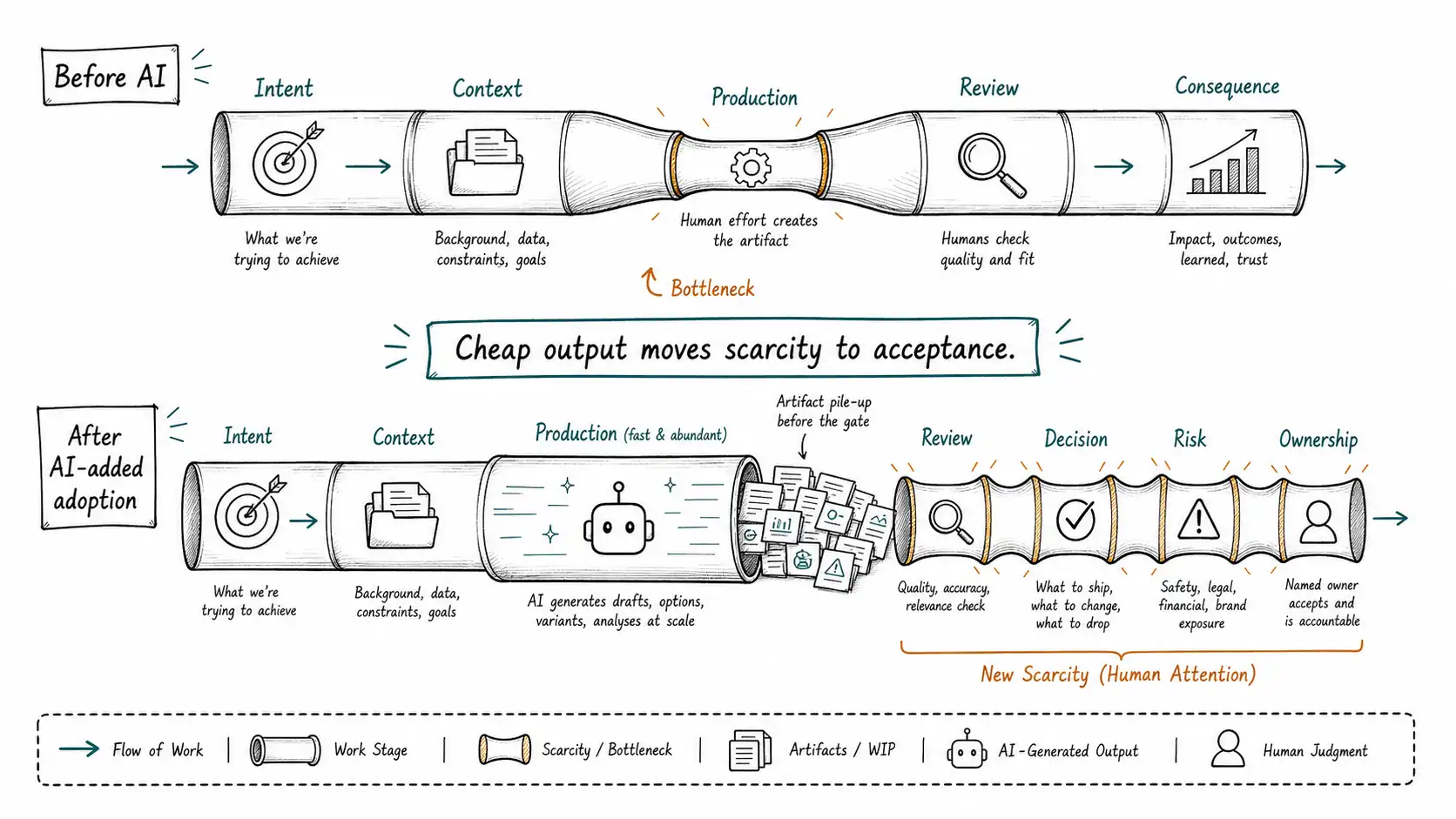
AI-added work preserves the old bottleneck
The old process in most knowledge organizations had five broad stages: intent, context gathering, production, review, and consequence. Humans performed all five, though not always consciously. They decided what to do, collected context, produced the artifact, reviewed the artifact, and lived with the result.
AI changes production first. That is why the first wave feels dramatic. Production is the stage where text, code, images, summaries, classifications, drafts, analyses, and recommendations appear. A model can generate these quickly because it has learned patterns over enormous corpora and can transform input into plausible output at speed.
But the surrounding stages do not become free. In fact, they often become more important.
Intent becomes more important because a machine can execute the wrong instruction fluently. Context becomes more important because the model does not automatically know the account history, regulatory status, architectural constraint, customer politics, pricing exception, support backlog, or unstated executive priority. Review becomes more important because plausible output creates overconfidence. Consequence becomes more important because the organization cannot blame the model when a customer is harmed, a contract is wrong, a release breaks production, or a forecast misleads a board.
AI-added work keeps the same process and accelerates the middle. AI-native work redesigns the whole process around the new constraint.
The simplest way to see this is as a bottleneck shift.
A useful operating question follows: if the machine made production ten times cheaper tomorrow, what would become the bottleneck the day after? In most organizations the answer is not compute. It is not prompting. It is not seats purchased. It is judgment.
The Output-to-Outcome Ledger
The first artifact in an AI-native operating model is a ledger that connects machine-produced output to the business or operational outcome it is supposed to affect. The ledger prevents the organization from celebrating generated volume when accepted value did not improve. It also sets up the later argument in The Judgment Stack: every output needs a defined judgment surface before it can be trusted.
| Generated output | Human or system acceptance point | Intended outcome | Evidence required | Failure if mismeasured |
|---|---|---|---|---|
| AI-drafted sales email | Account owner approves/send rules accept | Qualified meeting or useful reply | Reply quality, conversion, account fit | More spam, lower trust |
| AI support response | Resolution check passes or agent accepts | Issue resolved without reopen | Reopen rate, CSAT, escalation rate, refund/contact follow-up | Faster replies, unresolved problems |
| AI-generated code patch | Tests, review, security checks, owner approval | Safe product change | Passing tests, code review, incident rate, maintainability | More PRs, more defects |
| AI product requirement draft | Product/engineering agree on decision | Clear build intent | Acceptance criteria, tradeoff decisions, scope boundary | More documents, unclear work |
| AI analysis memo | Decision-maker accepts recommendation | Better decision | Decision outcome, assumptions, sensitivity analysis | Confident wrong analysis |
| AI marketing variant | Brand/legal/performance gates pass | Better campaign performance | Conversion, brand safety, compliance, unsubscribe rate | More copy, weaker brand |
The ledger is intentionally boring. It turns a vague AI productivity claim into an accountability chain. For every machine-produced artifact, it asks: where is the acceptance point, what outcome does this output exist to improve, what evidence proves the outcome, and what happens if we measure the wrong thing?
Without this ledger, a company can drown in AI-generated work while convincing itself that the water level is growth.
The first-draft factory has a morale cost
There is another cost that leaders often miss. When AI is deployed as a first-draft factory, human workers become cleanup crews for machine output. That may be useful in moderation. It is corrosive when it becomes the dominant shape of work.
Reviewing plausible-but-wrong output is cognitively different from creating work directly. The reviewer must hold the intended answer, the system constraints, the customer context, and the machine's output in mind at the same time.
The machine's fluency can also create anchoring: the reviewer starts from the generated draft and edits around it, even when a fresh answer would have been better. Human-factors researchers have warned for decades that automation can create misuse, disuse, and complacency when people either trust it too much or learn not to trust it at all. Parasuraman and Riley's classic paper on automation misuse, disuse, abuse remains relevant because AI does not eliminate human factors; it intensifies them.
A bad AI rollout therefore changes not only productivity but dignity. Senior people can feel trapped approving mediocre drafts. Junior people can lose the learning path that came from producing the first draft themselves.
Managers can mistake busyness for progress because review queues look full. Customers can receive faster responses that feel less understood.
AI-native design does not ask humans to become passive editors of infinite output. It asks them to redesign the workflow so the machine handles the part it can do well, while humans spend time at judgment points worthy of human attention. The deeper evaluation argument is in Human in the Loop Is Not a Plan: human review only works when the loop has capacity, criteria, and escalation rules.
AI-native starts with a different question
The AI-added question is: "Where can we insert AI into the current process?"
The AI-native question is: "If production were cheap, what process would we design around intent, context, acceptance, risk, and learning?"
That question forces a company to revisit things it may have treated as stable: role boundaries, approval rights, review sampling, documentation standards, escalation paths, evaluation datasets, feedback loops, pricing models, and training programs. It also forces humility.
Not every workflow should become AI-native immediately. Some workflows lack reliable evaluation. Some are too high-stakes. Some depend on trust, relationship, or context that is hard to encode. Some would become cheaper but worse.
A workflow earns the label AI-native only when the organization has redesigned the work around the machine's actual strengths and limitations. The presence of a model is not enough. The purchase of a tool is not enough. The increase in drafts is not enough.
The company in the opening meeting eventually stopped reporting generated artifact volume as its primary AI metric. It kept the metric as a diagnostic, but moved it below accepted outcomes.
Sales measured qualified replies and pipeline quality. Support measured resolution and reopen rates. Engineering measured safe accepted changes, failed deployment recovery, and review burden. Product measured decision clarity, not PRD count. Marketing measured approved campaign performance and brand exceptions, not variant count.
The AI systems did not go away. In several places they became more valuable, because the organization finally asked them to serve the workflow instead of flooding it.
That is the first step into AI-native work: stop celebrating the factory. Find the judgment bottleneck. The next chapter traces where the work actually moved, inside tasks, not across job titles.