Acceptance Is the New Bottleneck
The engineering manager did not object to AI writing code. He objected to AI opening pull requests faster than his team could understand them.

The AI-native acceptance bottleneck appears when machine output becomes cheaper than the organization's ability to verify, accept, reject, and learn from it. The fix is not more generation. It is stronger acceptance infrastructure: evals, review queues, labels, outcome metrics, and clear gates.
The engineering manager did not object to AI writing code. He objected to AI opening pull requests faster than his team could understand them.
At first, the new coding agent looked like a gift. It could take a ticket, inspect parts of the repository, draft a change, add tests, and open a pull request. For small fixes it was impressive. The team celebrated the first week: more PRs opened, faster turnaround on low-priority bugs, fewer engineers spending time on repetitive edits.
By the third week, the team's lead time had not improved. Review queues were longer. Senior engineers were spending more time reading code they did not write and less time designing the system. Some AI-authored changes were directionally correct but subtly inconsistent with service boundaries. Others passed tests but added maintenance burden. A few were rejected after long review because the ticket itself was under-specified. The agent had done exactly what it was asked to do. The organization had not improved its ability to accept, reject, or learn from what it produced.
This is the acceptance bottleneck.
Production became cheap. Acceptance did not.
Key Takeaways
- The engineering manager did not object to AI writing code. He objected to AI opening pull requests faster than his team could understand them.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with AI-Native and the adjacent chapters when you need the wider AI-Native Engineering frame.
Generated output has negative value until accepted
A generated artifact is not neutral. It has carrying cost. Someone must inspect it, store it, route it, reject it, approve it, or clean up after it. A low-quality generated output can cost more than no output because it consumes scarce judgment and introduces anchoring.
This is obvious in code review, but it appears everywhere. A sales team that generates 5,000 account-personalized emails now needs a way to know which messages are accurate, timely, and strategically useful. A legal team that uses AI to redline contracts now needs a way to verify whether suggested edits match policy and negotiating strategy. A support team that auto-drafts replies needs to know whether the issue was resolved. A product team that generates feature briefs needs to know whether the brief contains a decision or only a plausible narrative.
The value of AI-produced work is realized at acceptance, not generation. Until then, the artifact is inventory.
Manufacturing leaders understand inventory. Inventory ties up capital, hides quality problems, and creates downstream congestion. AI-generated knowledge work creates a similar problem: a pile of plausible artifacts waiting for scarce acceptance capacity.
The acceptance bottleneck has four components:
- Inspection cost - time and expertise required to judge output.
- Context cost - effort required to recover missing situation-specific information.
- Correction cost - effort required to fix flawed output.
- Consequence cost - risk if flawed output is accepted.
AI-native design reduces all four, not just generation cost.
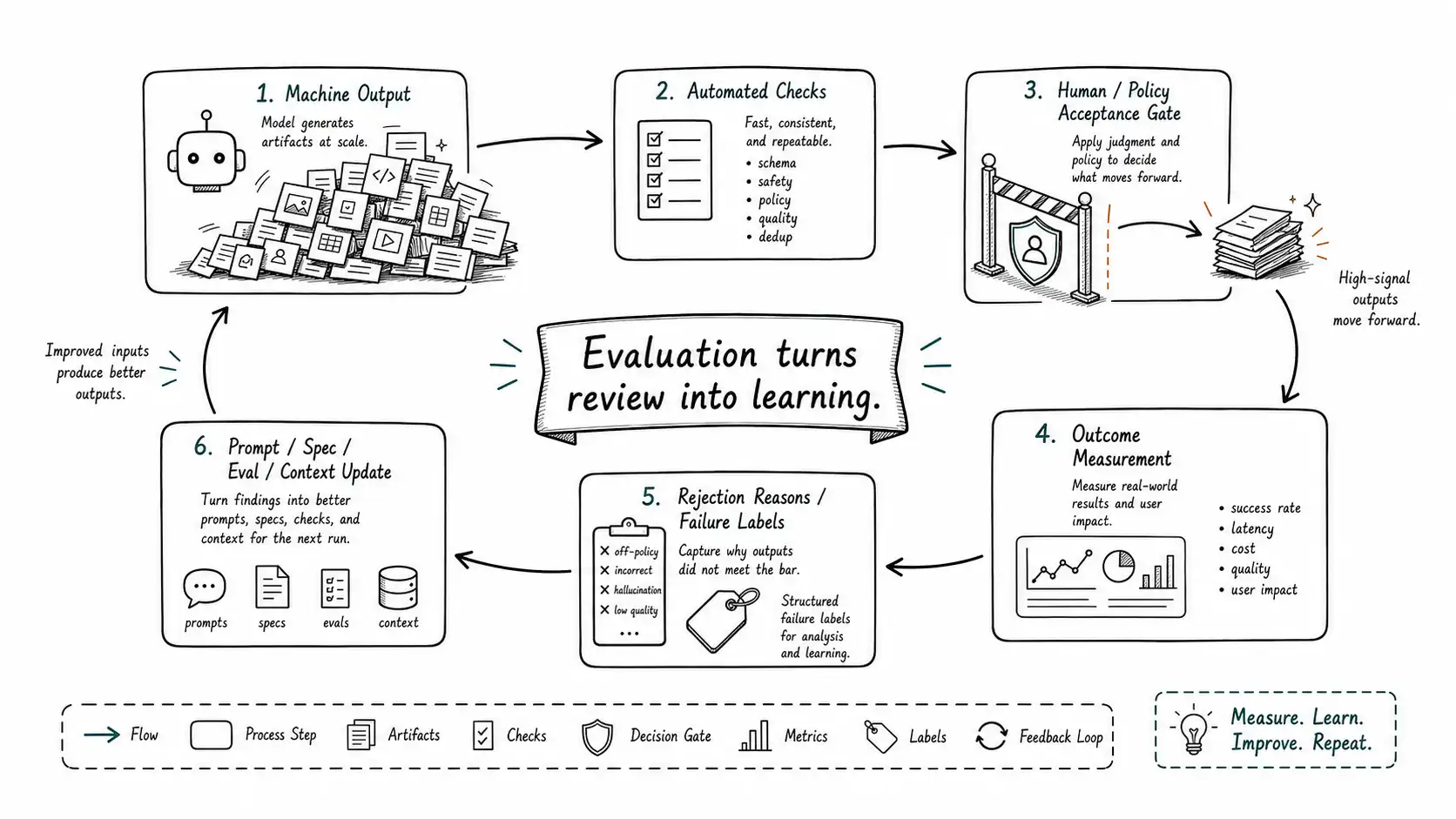
Evaluation is how judgment scales
Human review does not scale linearly with machine output. If every generated artifact requires full expert review, AI will increase workload instead of reducing it. If human review is removed without evaluation, quality and risk failures scale. The only durable answer is evaluation: tests, metrics, labels, reference cases, sampling, monitoring, and feedback loops that let the organization distinguish acceptable from unacceptable output with increasing reliability.
The AI community uses "evals" to describe systematic testing of model or application behavior. OpenAI's evaluation guidance frames evals as a way to test AI systems despite variability in model outputs (OpenAI evaluation best practices). The important operating lesson is broader than any vendor tool: AI-native workflows need evaluation before autonomy and better evaluation as autonomy increases.
Evaluation is not one thing. It can include:
- Unit tests for machine-authored code.
- Golden datasets for support classification.
- Human-labeled examples of good and bad responses.
- Policy checks for prohibited claims.
- Retrieval tests for knowledge workflows.
- Regression suites for prompts/specs.
- Shadow-mode comparisons before automation.
- Sampled quality review after deployment.
- Outcome metrics such as reopen rate, conversion, retention, incident rate, or rework rate.
Evaluation turns judgment from a purely human bottleneck into a system capability.
But evaluation is also not magic. It measures what the organization has made measurable. A weak eval can create false confidence. A support eval that checks answer similarity but not customer resolution will reward fluent wrong answers. A coding eval that checks test pass rate but not maintainability will reward brittle patches. A sales eval that checks personalization tokens but not buyer relevance will reward synthetic specificity.
The first rule of acceptance is therefore: evaluate the outcome you actually care about, not the artifact the model can easily produce.
Review is no longer the same job
Before AI, review often meant reading work produced by a colleague who understood the same operating context. After AI, review often means judging work produced by a system that may have partial context, no responsibility, high fluency, and uneven reliability. The reviewer's job changes.
A traditional reviewer asks, "Is this good?"
An AI-native reviewer asks a wider set of questions:
- Did the machine receive the right intent?
- Did it have the necessary context?
- Did it violate any explicit constraints?
- Is the output correct enough for this use?
- Does it require escalation?
- What failure mode would this create if accepted?
- Does this output reveal a spec, data, or workflow problem?
- Should the system be updated after this review?
That last question is critical. In a human-only workflow, a reviewer can correct an individual artifact and move on. In an AI-native workflow, repeated corrections should become system improvements. If reviewers fix the same output failure every day without updating the prompt, spec, retrieval source, policy, eval, or workflow, the organization is paying review cost without learning.
This is where acceptance becomes a product surface. The review interface should not only offer "approve" and "reject." It should capture structured rejection reasons, missing context, severity, policy issue, output category, and suggested system improvement.
A basic acceptance event might look like this:
{
"workflow": "support_resolution_draft",
"artifact_id": "sr_2026_04_17_9182",
"prompt_version": "support_resolution_v14",
"context_snapshot_id": "ctx_88431",
"machine_confidence": 0.87,
"reviewer": "agent_204",
"decision": "reject",
"judgment_layer_failed": "context",
"rejection_reason": "enterprise contract exception missing",
"customer_impact_if_accepted": "incorrect refund denial",
"should_update_system": true,
"recommended_update": "add contract exception retrieval before refund policy generation"
}This is not bureaucratic overhead if it prevents the same failure from repeating. It is how the system learns from human judgment.
Acceptance criteria must exist before generation
Many AI pilots fail because acceptance criteria are written after people see the output. That encourages subjective review and moving goalposts. A team asks the model to write something, reacts to the draft, then tries to explain what was wrong. The process can produce better prompts, but it is not a reliable operating model.
AI-native workflows define acceptance before generation. That is easiest in software, where test-driven development already provides a mental model: define expected behavior, then write code that satisfies it. AI-native software work extends that discipline. The human specifies behavior, constraints, tests, non-goals, and review standards; the machine drafts implementation; the system checks; humans review high-value judgment points.
The same principle applies outside software. Before generating a sales follow-up, define what a good follow-up must accomplish: reference a real customer pain, avoid unsupported claims, reflect the stage of the deal, include a useful next step, and respect account strategy. Before generating a support answer, define resolution criteria: solves the stated issue, uses current policy, references account entitlement, avoids restricted claims, and does not close the ticket if uncertainty remains. Before generating a legal summary, define what must be extracted, what cannot be inferred, and when lawyer review is mandatory.
A practical acceptance-criteria document has five parts:
| Section | Question | Example |
|---|---|---|
| Intended use | What will this output be used for? | Draft response sent to customer after agent acceptance |
| Hard constraints | What must never be violated? | No refund denial without entitlement lookup |
| Quality bar | What does good enough mean? | Solves issue without requiring a second contact |
| Escalation triggers | When must machine output not be accepted? | Enterprise account, legal threat, active incident |
| Learning hook | How do failures improve the system? | Rejection reason updates eval set weekly |
This document may be short. It may live in code, a workflow tool, a policy repository, or an operating manual. The important fact is that it precedes production.
Outcome metrics must discipline output metrics
DORA's work on software delivery has long emphasized that delivery performance is a system property, not a raw activity count. Its 2024 and 2025 AI-assisted software material is useful because it warns organizations to look beyond tool adoption toward system-level outcomes and unintended effects (DORA AI resources, 2025 State of AI-Assisted Software Development). Whether or not one agrees with every interpretation of DORA survey data, the operating point is sound: AI impact must be measured through workflow outcomes, not usage enthusiasm.
Here is the difference:
| Output metric | Why it is tempting | Outcome metric | Why it is better |
|---|---|---|---|
| Emails generated | Easy to count | Qualified replies / pipeline quality | Measures buyer response and fit |
| Tickets answered | Easy to count | Resolved issues without reopen | Measures customer outcome |
| PRs opened | Easy to count | Accepted safe changes | Measures delivered value and review cost |
| Documents drafted | Easy to count | Decisions made with clarity | Measures coordination value |
| Summaries produced | Easy to count | Actions taken correctly | Measures whether summary mattered |
| Prompts run | Easy to count | Workflow cost per accepted outcome | Measures economics |
AI-native managers do not ignore output metrics. They demote them. Output metrics become leading indicators or diagnostics. Outcome metrics become the basis for trust.
A team that generates more support answers but increases reopen rate did not improve support. A team that opens more PRs but increases review time and defects did not improve engineering. A sales team that sends more outreach but damages reply quality did not improve revenue. A product team that writes more requirements but creates more ambiguity did not improve product development.
A small eval configuration
For technical teams, acceptance should eventually become executable. A simple retrieval/support workflow might define eval cases and acceptance thresholds like this:
eval_suite: support_resolution_v3
workflow: ai_assisted_support_resolution
owner: support_quality_lead
cadence: weekly
cases:
- id: refund_policy_standard
input: "Customer asks for refund after duplicate charge"
required_context:
- billing_history
- refund_policy_current
expected_behavior:
- acknowledges issue
- checks duplicate charge before policy denial
- avoids unsupported guarantee
failure_severity: medium
- id: enterprise_contract_exception
input: "Enterprise customer requests refund outside standard policy"
required_context:
- account_tier
- contract_terms
- customer_success_owner
expected_behavior:
- escalates to CSM
- does not deny automatically
- references account-specific review
failure_severity: high
metrics:
policy_violation_rate:
max: 0.01
resolution_accuracy:
min: 0.90
escalation_recall_high_risk:
min: 0.98
reopen_rate_shadow_mode:
max: 0.07
release_gate:
block_if:
- policy_violation_rate > 0.01
- escalation_recall_high_risk < 0.98
- any_high_severity_failure: trueThis is not a complete eval system. It is a posture. The workflow does not graduate because the generated text sounds good in a demo. It graduates because it passes cases that represent real failures the organization cares about.
Review queues are signals
When review queues grow after AI adoption, leaders often treat them as staffing problems. Sometimes they are. More often they are design signals.
A growing review queue may mean:
- The machine is producing too much low-value output.
- Acceptance criteria are unclear.
- The system lacks automated checks.
- The task is outside the model's reliable frontier.
- The workflow lacks escalation rules.
- The wrong person is reviewing the wrong judgment layer.
- The organization is trying to automate a high-context task prematurely.
- The output metric is rewarded more than the outcome metric.
The correct response is not always "hire more reviewers." It may be to narrow the machine's scope, improve context retrieval, add automated policy checks, require better specs, change review sampling, or stop generating certain artifacts entirely.
A review queue is the organization telling itself where judgment is overloaded.
The acceptance doctrine
Acceptance is where AI-native work becomes real. A model can generate a thousand drafts. Only accepted output changes the business. A model can suggest a hundred actions. Only accepted action creates consequence. A model can open ten pull requests. Only merged, safe, maintainable code matters.
The doctrine is straightforward:
- Define acceptance before generation.
- Evaluate against outcomes, not artifact volume.
- Automate checks where rules are clear.
- Keep humans at judgment layers where stakes or ambiguity are high.
- Capture rejection reasons as training signal for the workflow.
- Treat review queues as system-design feedback.
- Increase autonomy only after acceptance is measurable and reliable.
AI-native work does not worship speed. It earns speed by making acceptance trustworthy. Redesigning the workflow, not just the tooling budget, is where that trust is built into the process.