The Judgment Stack
A CEO once told his leadership team, "We need people using judgment, not doing busywork." Everyone agreed, which was the problem. The sentence sounded wise enough to stop the conversation before it became useful.

The Judgment Stack is the operating model for reviewing machine output: split "use judgment" into intent, constraints, context, quality, risk, ownership, and change so the right person or system owns each decision. Without that split, AI-native work turns human review into a vague liability sink.
A CEO once told his leadership team, "We need people using judgment, not doing busywork." Everyone agreed, which was the problem. The sentence sounded wise enough to stop the conversation before it became useful.
Judgment is one of those words organizations use when they know something matters but have not decomposed it. It is treated like a personal trait: some people have judgment, others do not. That framing is too vague for AI-native work. Once machines produce drafts, actions, recommendations, and code at scale, judgment cannot remain a soft compliment. It has to become an operating structure.
The reason is simple. Different failures require different kinds of judgment. A machine-generated legal clause may be grammatically clean and commercially disastrous. A support answer may be factually correct and emotionally tone-deaf. A code patch may pass tests and violate architecture. A forecast may be statistically plausible and strategically irrelevant. A marketing message may be on-brand and noncompliant in one region. A recommendation may maximize conversion and damage trust.
Calling all of these "judgment" hides the work. AI-native organizations need to split judgment into layers so they can assign responsibility, design review, build evaluation, and train people deliberately.
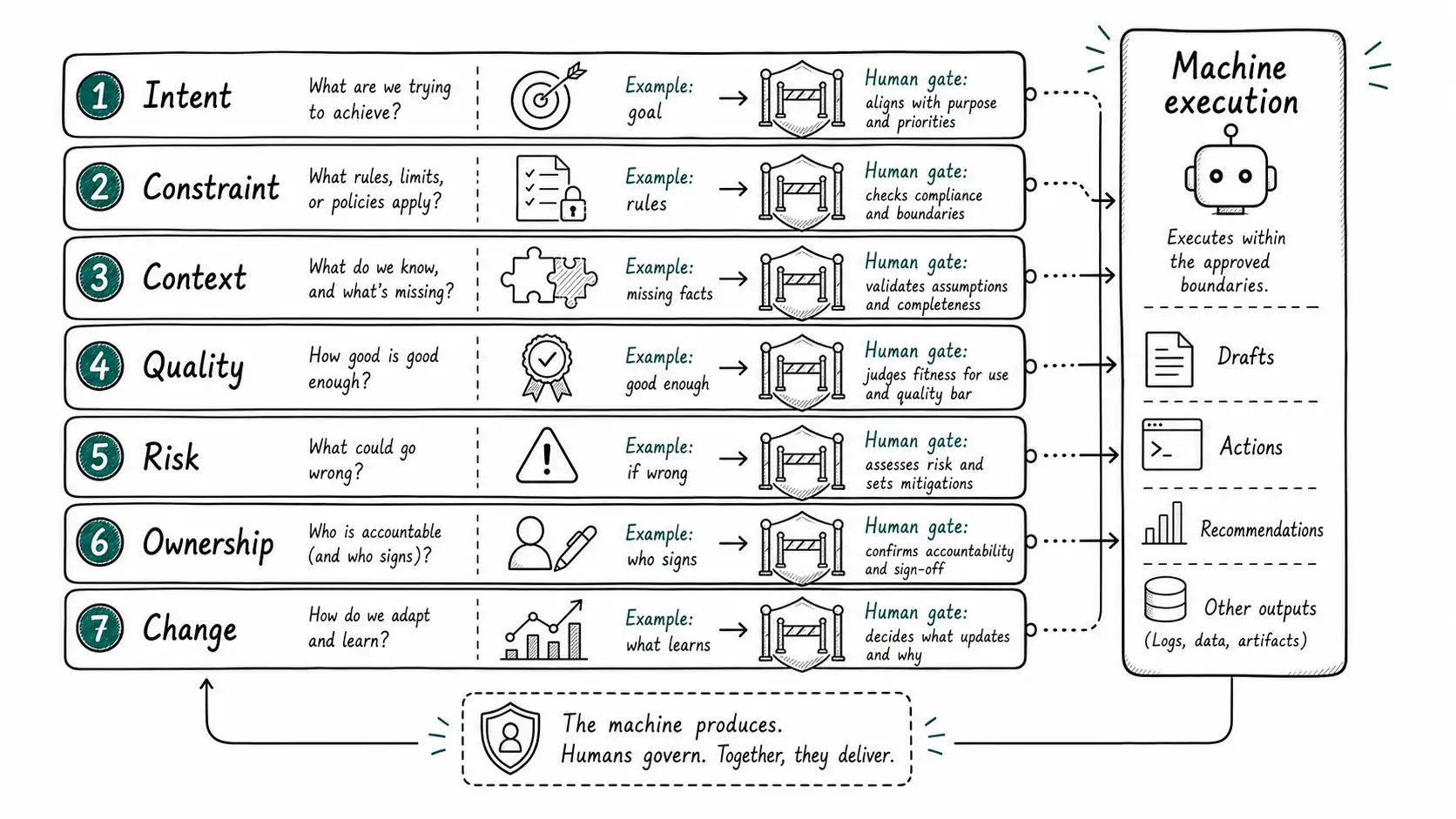
This book uses a framework called The Judgment Stack.
Key Takeaways
- The Judgment Stack names the operating decision a team has to make before it accepts the work.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with AI-Native and the adjacent chapters when you need the wider AI-Native Engineering frame.
The seven layers
The Judgment Stack names the human decision layers that remain load-bearing after machine execution increases.
| Layer | Core question | Example in software | Example in revenue | Example in operations |
|---|---|---|---|---|
| Intent Judgment | What are we trying to achieve? | Should this system optimize reliability, speed, or flexibility? | Is this outreach meant to qualify, educate, renew, or expand? | Are we reducing cost, cycle time, error rate, or customer pain? |
| Constraint Judgment | What must not be violated? | Security, architecture, latency, data model, maintainability | Brand, pricing policy, legal promise, account strategy | Compliance, safety, fairness, service commitments |
| Context Judgment | What does the machine not know? | Legacy behavior, incident history, team ownership | Political state of account, customer history, buyer personality | Local exception, edge case, staffing constraint |
| Quality Judgment | Is the output good enough for its use? | Patch is correct, tested, readable, and maintainable | Message is specific, useful, and credible | Resolution actually solves the problem |
| Risk Judgment | What happens if this is wrong? | Outage, data leak, tech debt, security flaw | Lost deal, broken trust, bad pricing precedent | Compliance violation, customer harm, operational backlog |
| Ownership Judgment | Who accepts responsibility? | Code owner, reviewer, service owner, release approver | Account owner, manager, legal approver | Process owner, escalation owner, executive sponsor |
| Change Judgment | What should improve after this result? | Add tests, update spec, improve prompt, change architecture | Update playbook, revise segmentation, fix CRM data | Update policy, knowledge base, routing, staffing model |
The stack is deliberately not a personality model. It is a workflow model. Each layer can be assigned, trained, supported, audited, and improved. A person may be excellent at Quality Judgment and weak at Risk Judgment. A product manager may have strong Intent Judgment and need legal support for Constraint Judgment. A support lead may have deep Context Judgment and need analytics support for Change Judgment. A senior engineer may be strong across most layers in one codebase and weak in a new domain.
Judgment under uncertainty is not magic
The Judgment Stack sits on a long research tradition. Herbert Simon's work on bounded rationality argued that humans do not optimize with perfect information; they satisfice under limits of attention, information, and computation. Kahneman, Slovic, and Tversky's work on judgment under uncertainty showed that human decisions rely on heuristics and are vulnerable to bias. Gary Klein's research on recognition-primed decision-making showed that expert judgment often works by pattern recognition under time pressure, not by exhaustive analysis.
AI-native work does not remove these human limits. It changes the environment in which they operate. The machine can increase available information and generate alternatives, but it can also increase cognitive load, create anchoring, hide uncertainty behind fluent language, and flood reviewers with more plausible options than they can inspect deeply.
That is why "let the human decide" is not a design. A human decision at the end of an overloaded workflow may be the weakest control in the system. The Judgment Stack helps by asking which judgment layer is actually needed and how it should be supported.
For example, a machine-generated customer refund decision might require:
- Intent Judgment: Are we trying to minimize refund cost or maximize retention?
- Constraint Judgment: What does policy allow? What did the contract promise?
- Context Judgment: Is this a strategic account? Has this customer had repeated issues?
- Quality Judgment: Is the proposed response clear and complete?
- Risk Judgment: What precedent does this create?
- Ownership Judgment: Who can approve the exception?
- Change Judgment: Does this issue reveal a product defect or policy gap?
If the company simply asks a support agent to "review the AI answer," it compresses seven distinct responsibilities into one vague instruction. The agent may check tone and miss contract risk. A manager may approve the refund and miss the product pattern. Legal may review the clause and miss the customer relationship. Good AI-native design separates the layers enough that the right person or system handles each one.
Judgment is different from preference
One reason organizations fail to operationalize judgment is that they confuse judgment with preference. Preference says, "I like this version." Judgment says, "This version is adequate for this purpose under these constraints with these risks."
The distinction matters because AI can produce endless variants. In marketing, a model can generate ten headlines in seconds. If the human review criterion is preference, the review becomes taste theater. If the criterion is judgment, the review asks: Which audience is this for? What claim are we allowed to make? What risk does this phrasing create? What outcome are we testing? What evidence would make us keep or kill the variant?
In engineering, preference says, "I like this implementation style." Judgment says, "This implementation preserves the service boundary, follows the data model, has clear tests, avoids known operational failure modes, and is maintainable by the on-call team."
In sales, preference says, "This email sounds good." Judgment says, "This message is specific to the buyer's situation, does not overpromise, aligns with the account strategy, and creates a next step the buyer is likely to accept."
AI-native workflows need review rubrics that turn preference into judgment. The rubric does not eliminate expertise; it makes expertise teachable and auditable.
A minimal judgment rubric looks like this:
| Review dimension | Pass condition | Human question | Evidence source |
|---|---|---|---|
| Intent fit | Output serves the stated objective | Does this solve the problem we intended? | Brief, ticket, account plan, PRD |
| Constraint fit | No hard rule is violated | What would make this unacceptable even if useful? | Policy, architecture, legal, brand, security |
| Context fit | Situation-specific facts are respected | What does the model not know or underweight? | CRM, logs, customer history, incident notes |
| Quality fit | Output is good enough for its use | Would this satisfy a competent reviewer in this domain? | Tests, examples, expert review, customer signal |
| Risk fit | Failure mode is acceptable or mitigated | What is the cost of being wrong? | Risk register, severity matrix, rollback path |
| Ownership fit | Accountable person or system is named | Who signs this? | RACI, approval workflow, audit log |
| Learning fit | Failure can improve the workflow | If wrong, what will change? | Eval backlog, prompt/spec update, playbook update |
This rubric can be adapted to code review, content approval, sales outreach, support resolution, legal review, procurement, finance analysis, and operations. The point is not to bureaucratize every decision. It is to stop pretending that a generic human review is sufficient.
The machine can assist judgment, but not own it
AI can support parts of the Judgment Stack. It can identify missing context, compare an output to a policy, run a test, estimate risk from historical incidents, suggest an owner, or summarize patterns from failures. In mature workflows, the machine should do these things. The issue is not whether AI can support judgment. It is whether the organization treats support as ownership.
A model can say, "This contract clause appears to deviate from standard indemnity language." It cannot own the commercial decision to accept that deviation. A model can say, "This customer is likely to churn." It cannot own the retention strategy. A model can say, "This code patch touches a high-risk service and lacks tests for a known failure mode." It cannot own the release decision. A model can say, "This support answer may be incomplete because the account has an enterprise exception." It cannot own the customer relationship.
The distinction between assistance and ownership is central to AI-native governance. NIST's AI Risk Management Framework emphasizes that AI risk management includes governance, mapping context, measuring risk, and managing risk over the AI lifecycle (NIST AI RMF). The framework is not only about model performance; it is about organizational responsibility. The Judgment Stack is a practical translation of that principle into daily work.
Microsoft Research's Guidelines for Human-AI Interaction also reinforce the importance of making AI uncertainty, context, and user control visible across interaction stages. The lesson for operating design is that judgment improves when humans know what the system is doing, what it is confident about, where it may be wrong, and what action is expected from the human.
A human asked to approve AI output without system transparency is not exercising judgment. They are absorbing liability.
Judgment debt
Technical debt is the cost of past engineering shortcuts. AI-native organizations also accumulate judgment debt: the cost of automating production without designing the judgment layers around it.
Judgment debt appears as:
- Review queues that grow faster than output quality improves.
- Managers who approve machine output because they cannot inspect everything.
- Workers who rubber-stamp AI suggestions because rejection takes longer than acceptance.
- Customers who receive fast but generic answers.
- Metrics that reward generated volume rather than accepted value.
- Escalation paths that do not distinguish quality failures from risk failures.
- Policies that say "human in the loop" without defining the loop.
- Incidents where nobody can say who accepted the machine's action.
Judgment debt compounds because AI systems produce more opportunities for weak acceptance. A human-only process may fail slowly because production capacity is limited. A machine-first process can fail at scale because production is abundant. The organization that does not strengthen judgment can become faster precisely where it is least safe to be fast.
A practical way to detect judgment debt is to ask five questions in an operating review:
- Which AI-generated outputs were accepted last week?
- Which were rejected, and why?
- Which accepted outputs later caused rework, customer dissatisfaction, risk, or escalation?
- Which judgment layer failed: intent, constraint, context, quality, risk, ownership, or change?
- What changed in the workflow because of the failure?
If the team cannot answer these questions, it is not managing AI-native work. It is managing output.
Using the stack across domains
The Judgment Stack is useful because it travels.
In software engineering, Intent Judgment defines the behavior change; Constraint Judgment captures architecture, security, latency, data, and maintainability boundaries; Context Judgment includes existing codebase conventions and incident history; Quality Judgment is expressed through tests and code review; Risk Judgment includes blast radius and rollback; Ownership Judgment names code owners and service owners; Change Judgment updates tests, specs, or architecture after failures.
In sales, Intent Judgment distinguishes education from qualification, renewal, expansion, or executive alignment. Constraint Judgment protects pricing, legal promises, brand, and account strategy. Context Judgment includes buyer personality, politics, history, and timing. Quality Judgment asks whether the message is specific and useful. Risk Judgment asks whether the outreach damages trust or creates a false commitment. Ownership Judgment names the account owner. Change Judgment updates segmentation, messaging, or qualification logic.
In support, Intent Judgment defines resolution, not response. Constraint Judgment includes policy and entitlement. Context Judgment includes customer history and product state. Quality Judgment asks whether the issue is solved. Risk Judgment asks whether the answer creates churn, legal exposure, or product harm. Ownership Judgment identifies the resolver and escalation owner. Change Judgment turns unresolved patterns into product fixes or knowledge updates.
In legal and compliance review, the stack slows down appropriately. The machine may assist with comparison, summarization, redlining, and issue spotting, but Constraint, Risk, and Ownership Judgment remain strongly human and role-bound.
The point is not that every workflow needs a seven-step meeting. The point is that every AI-native workflow needs to know which judgment layers are relevant, which can be partially automated, which require humans, and what evidence supports acceptance.
The machine can produce. The stack decides whether production should matter. The next chapter addresses who owns the consequences when the machine produces and the human accepts.