The AI-Native Operating System
The company's AI program did not fail because the models were weak. It failed because nobody changed the calendar.

An AI-native operating system is the recurring cadence of evals, metrics, ownership records, autonomy reviews, failure reviews, and portfolio decisions that keeps machine-shaped work connected to outcomes. Without that calendar, AI adoption stays active but ungoverned.
The company's AI program did not fail because the models were weak. It failed because nobody changed the calendar.
Teams had tools. They had pilots. They had champions. They had Slack channels full of tips. They had a vendor roadmap. What they did not have was an operating cadence that made AI-native work governable. Evals were reviewed only before launch. Prompt changes happened informally. Automation boundaries were discussed after incidents. Managers measured usage. Risk owners were consulted late. Rejection reasons disappeared into comments. Customer outcomes were reviewed in separate meetings from workflow design. Nobody had a recurring forum where machine output, human judgment, business outcomes, and system changes were examined together.
The organization had AI activity. It did not have an AI-native operating system.
An operating system, in this sense, is not software. It is the recurring set of meetings, metrics, artifacts, decision rights, review loops, and escalation paths that keep work aligned with outcomes. AI-native organizations need one because machine execution increases the speed at which weak operating habits compound.
Key Takeaways
- The company's AI program did not fail because the models were weak. It failed because nobody changed the calendar.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with AI-Native and the adjacent chapters when you need the wider AI-Native Engineering frame.
The cadence must match the new failure modes
Traditional operating cadences are often organized around function: engineering standup, sales forecast, support QA, product roadmap, security review, finance close, customer success health, executive business review. AI-native workflows cut across these functions. A support resolution system may depend on product incident data, CRM entitlements, legal policy, knowledge-base freshness, model behavior, QA sampling, and customer outcome metrics. No single traditional meeting sees the whole loop.
The cadence must therefore include AI-native review rituals.
A minimal operating cadence includes:
| Cadence | Participants | Questions | Output |
|---|---|---|---|
| Weekly workflow health review | Workflow owner, system owner, ops lead, QA/eval owner | Are outcome metrics stable? What failed? Are review queues healthy? | Fixes, escalations, eval updates |
| Weekly eval review | System owner, domain expert, QA, product/ops | Which evals failed? Are evals representative? What new cases are needed? | Updated eval set and release gates |
| Biweekly boundary review | Workflow owner, risk/constraint owner, system owner | Should autonomy expand, contract, or stay? What evidence supports boundary? | Boundary decision and controls |
| Monthly outcome review | Functional leader, finance/revops/product/ops, workflow owners | Did AI-native workflow improve business/customer outcome? | Continue, redesign, or stop decision |
| Monthly failure review | Cross-functional owners | Which Judgment Stack layers failed repeatedly? | Systemic fixes, not blame |
| Quarterly governance review | Executive owner, legal, security, compliance, AI/product/ops | Are controls, logs, risks, and responsibilities adequate? | Governance actions and policy changes |
| Quarterly workflow portfolio review | Exec team and workflow owners | Which workflows deserve more autonomy, less automation, or retirement? | Portfolio prioritization |
The cadence should be proportional. A small team does not need seven meetings for a low-risk internal assistant. But every AI-native workflow needs some recurring forum where output, acceptance, outcome, and risk are reviewed together.
DORA's AI-assisted software work emphasizes that successful adoption is a systems problem, not merely a tooling problem (DORA 2025 report). That point generalizes beyond engineering. AI-native performance depends on practices around the tool: measurement, culture, feedback, review, and reliability.
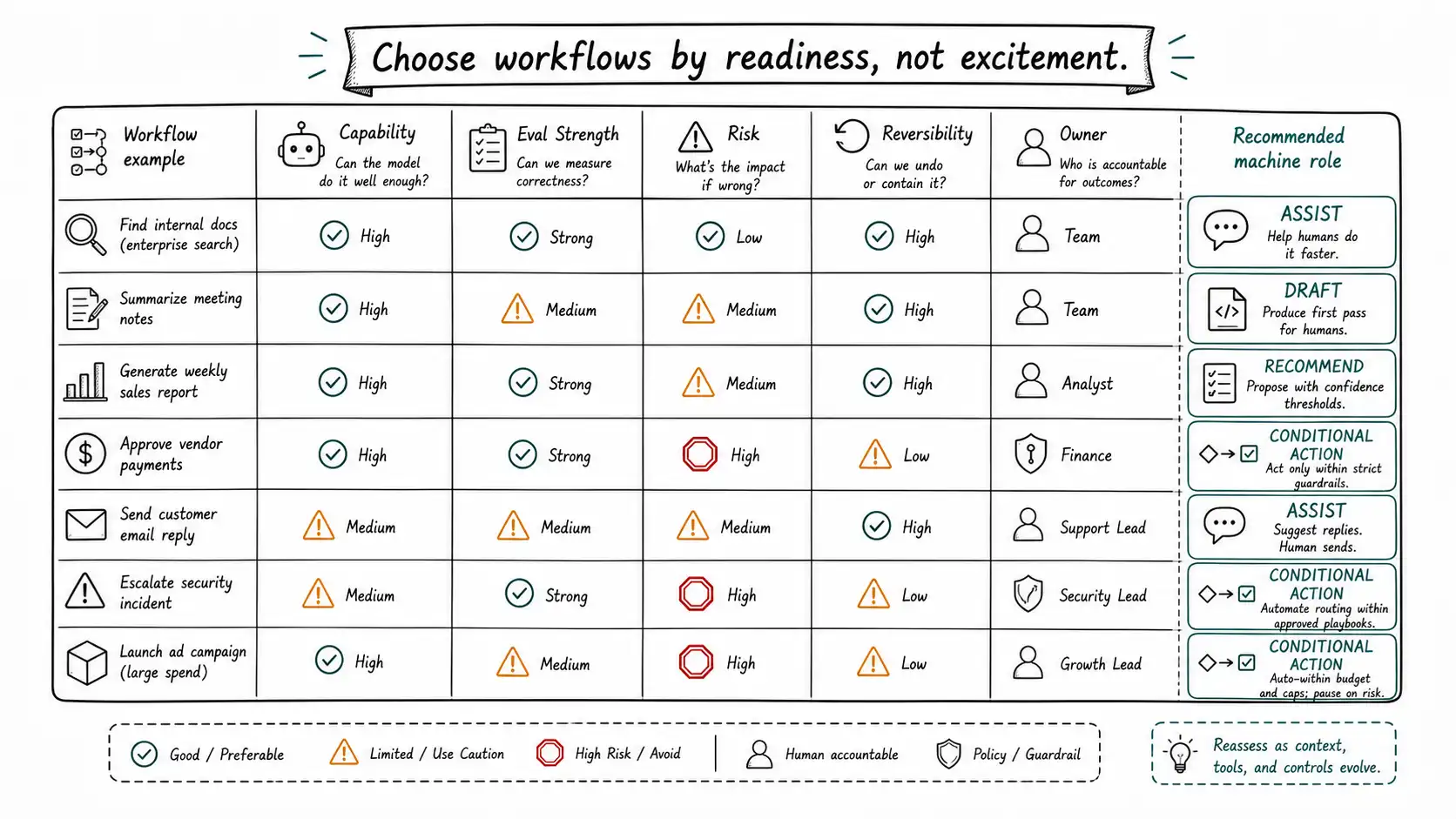
The AI-native readiness matrix
Before expanding AI across a workflow portfolio, leaders need a way to prioritize. The readiness matrix prevents teams from selecting workflows purely by excitement or vendor demo quality.
| Workflow type | Machine capability | Evaluation strength | Risk | Reversibility | Decision owner | Readiness |
|---|---|---|---|---|---|---|
| Internal meeting summary | High | Medium | Low | High | Team lead | Good starter |
| Standard support classification | High | High | Medium | High | Support ops | Good candidate |
| Low-value refund recommendation | Medium | Medium | Medium | Medium | Support manager | Pilot with gates |
| Enterprise contract acceptance | Medium | Low | High | Low | Legal/commercial owner | Assist only |
| Production code patch in isolated module | Medium | High if tests strong | Medium | Medium | Code owner | Machine-first draft |
| Security-sensitive code change | Medium | Medium | High | Low | Security/code owner | Human-led with AI assist |
| Sales outreach for low-tier accounts | High | Medium | Medium | High | Sales manager | Controlled pilot |
| Strategic account negotiation | Low/medium | Low | High | Low | Account executive/executive sponsor | Human-led |
| Invoice field extraction | High | High | Medium | Medium | Finance ops | Good candidate |
| Vendor bank-detail change | Medium | Medium | Very high | Low | Finance/security | Human-led with checks |
Readiness is not a moral ranking. It is a design ranking. The best early AI-native workflows are repeated, bounded, measurable, reversible, and owned. The worst early candidates are ambiguous, high-stakes, sparse, adversarial, irreversible, and politically sensitive.
The operating artifacts
A mature AI-native operating system uses a small set of durable artifacts. These artifacts prevent conversations from becoming abstract.
Workflow map. Defines intent, context, production, verification, decision, and consequence for a workflow.
Judgment Stack assignment. Names which roles own Intent, Constraint, Context, Quality, Risk, Ownership, and Change Judgment.
Acceptance criteria. States what makes output good enough, what blocks acceptance, and what requires escalation.
Eval suite. Tests expected behavior, failure modes, policy constraints, and regressions.
Autonomy boundary. Defines what the machine may assist, draft, recommend, or do.
Output-to-outcome ledger. Connects generated artifacts to accepted business outcomes.
Failure taxonomy. Classifies failures by Judgment Stack layer, severity, cause, and fix path.
Runbook. Explains what to do when the workflow misbehaves.
Change log. Records prompt/spec/model/context/eval/policy changes and their effects.
Governance record. Preserves ownership, risk assessment, approvals, audit logs, and review history.
These artifacts should be boring enough to maintain. The danger is creating a governance museum: many documents, little operational use. Every artifact should support a recurring decision. If nobody uses an artifact in a meeting, review, release, audit, or incident, simplify it or remove it.
Metrics that matter
AI-native metrics should connect machine activity to judgment quality and business outcome.
A practical metric set includes four layers.
Activity metrics show usage and volume. They include generated outputs, accepted outputs, automation rate, tool usage, and workflow coverage. These are useful diagnostics but weak success metrics.
Acceptance metrics show whether output survives judgment. They include acceptance rate, rejection rate by reason, review time, automated-check pass rate, escalation rate, and human override rate.
Outcome metrics show whether the workflow improved. They include customer resolution, conversion, safe deployment, cycle time, error reduction, cost per accepted outcome, retention, incident rate, and revenue quality.
Risk and learning metrics show whether the system remains safe and improves. They include policy violations, high-severity misses, audit gaps, repeated failure rate, eval coverage, drift indicators, repair time, and system improvement rate.
The most common measurement failure is stopping at activity. The second most common is measuring outcomes without measuring acceptance cost. A workflow may improve average speed but overload senior reviewers. Another may reduce support cost while increasing customer frustration. Another may increase code volume while decreasing maintainability. The operating system must see both value and burden.
Operating review questions
A weekly AI-native workflow health review can be run with ten questions:
- What outcome did this workflow improve or harm this week?
- How many outputs were generated, accepted, rejected, escalated, or auto-accepted?
- Which rejection reasons were most common?
- Which Judgment Stack layer failed most often?
- Did any high-risk cases bypass the intended boundary?
- Were reviewers overloaded or under-informed?
- Did eval failures match real-world failures?
- Which failures became system improvements?
- Should the autonomy boundary change?
- What is the single highest-use workflow fix before next review?
The review should not become a status meeting. It is a control loop. The output should be a change: update an eval, change an escalation rule, improve context retrieval, narrow autonomy, expand autonomy, adjust staffing, retire a low-value automation, or revise acceptance criteria.
OpenAI's eval guidance is useful here because it treats evaluation as an ongoing practice for variable AI systems rather than a one-time launch activity (evaluation best practices). The operating translation is that eval review belongs on the calendar. If evals are not reviewed, they become stale. If they become stale, the workflow's confidence becomes ceremonial.
The failure review
AI-native failure reviews should be blameless but not vague. They should identify where the workflow failed and what control must change.
A failure review template:
| Field | Description |
|---|---|
| Incident / failure | What happened? |
| Workflow | Which AI-native workflow was involved? |
| Machine role | Assist, draft, recommend, conditional action, autonomous loop |
| Accepted output/action | What was accepted or acted on? |
| Outcome impact | Customer, revenue, operational, legal, security, engineering impact |
| Judgment layer failed | Intent, constraint, context, quality, risk, ownership, change |
| Detection method | How was it found? |
| Detection gap | How should it have been found sooner? |
| Boundary issue | Was the machine allowed too much autonomy? |
| Context issue | Was required context missing/stale/incorrect? |
| Eval issue | Did evals cover this failure? |
| Repair owner | Who owns customer/system repair? |
| System change | What changed because of this? |
The key field is "system change." A failure review that ends with "user should be more careful" is usually incomplete. Maybe the user should be more careful. But the workflow should also ask why the user was placed in a position where care was the only control.
Governance without freezing the work
Governance is often presented as the enemy of speed. In AI-native work, good governance is what makes speed repeatable. It defines where teams can move quickly without renegotiating risk every time.
NIST's Govern-Map-Measure-Manage structure is helpful because it frames AI risk management as continuous (NIST AI RMF). ISO/IEC 42001 similarly emphasizes a management-system approach, not one-off approval (ISO/IEC 42001). The practical implication is that governance should be embedded into the operating system: ownership records, risk classification, eval evidence, logs, review cadence, change control, and incident learning.
The goal is not to make every AI workflow pass through a central committee. That does not scale. The goal is to classify workflows by risk and give teams clear rules for each class.
A lightweight governance tiering model:
| Tier | Example | Required controls |
|---|---|---|
| Tier 0: Personal productivity | Individual brainstorming, internal notes | Data policy, user guidance |
| Tier 1: Internal low-risk workflow | Meeting summaries, internal draft docs | Owner, usage logging, opt-out/correction path |
| Tier 2: Customer-facing draft/recommendation | Support drafts, sales drafts | Acceptance criteria, evals, human gate, audit logs |
| Tier 3: Conditional action | Small refunds, routing decisions, operational updates | Strong evals, boundary policy, monitoring, sampling, rollback/repair |
| Tier 4: High-stakes regulated or irreversible | Employment, credit, healthcare, legal acceptance, security action | Formal risk assessment, specialized review, human decision, compliance controls |
This allows speed where stakes are low and discipline where stakes are high. The worst governance model treats every workflow the same. That either blocks useful low-risk work or under-controls serious systems.
Portfolio management
Once a company has multiple AI-native workflows, leaders need portfolio management. The portfolio should answer:
- Which workflows are producing measurable outcome lift?
- Which are stuck in first-draft factory mode?
- Which have high review cost relative to value?
- Which have weak evaluation but rising autonomy?
- Which should be expanded, redesigned, paused, or retired?
- Which context sources, eval capabilities, or governance primitives would unlock multiple workflows?
This is where AI-native work becomes strategic. The point is not to have many pilots. The point is to build reusable operating capability: eval infrastructure, context management, permissioning, logging, acceptance interfaces, failure taxonomies, review practices, and talent development.
The organization that learns workflow by workflow becomes faster at the next workflow. The organization that treats each pilot as a separate tool experiment learns the same lessons repeatedly.
The operating principle
AI-native organizations are not defined by the number of workflows they automate. They are defined by whether machine output is connected to human judgment, measurable acceptance, accountable consequence, and systematic learning.
The operating system is what keeps that connection alive after the demo. It is the calendar, the metrics, the artifacts, the review habits, the escalation paths, and the governance tiers. Without it, AI-native language becomes branding. With it, AI becomes a durable redesign force.
The machine can produce work every second. The organization's cadence decides whether that work becomes progress. Before You Call It AI-Native distills the full operating doctrine into a checklist for that judgment.