The Autonomy Boundary
The workflow was technically automatable. That did not make it a good candidate for autonomy.

An AI autonomy boundary is the explicit line between what the machine may assist with, draft, recommend, conditionally do, or operate without approval. Capability is only one input; permission depends on risk, reversibility, eval strength, context completeness, constraint clarity, abuse exposure, user expectation, monitoring, and repair.
The workflow was technically automatable. That did not make it a good candidate for autonomy.
A finance operations team wanted to use AI to approve vendor-payment exceptions. The model could read invoices, compare purchase orders, inspect vendor history, draft explanations, and recommend whether an exception should be paid or escalated. In shadow mode, it performed well on routine cases. The temptation was obvious: let it approve low-value exceptions automatically.
The CFO paused the rollout. Not because the model was bad, but because the consequences were asymmetric. A false rejection could damage a vendor relationship. A false approval could create fraud exposure. Some exceptions looked routine but involved new vendors, changed bank details, or unusual payment timing. The evaluation set was too small. The workflow had no mature repair process. The team had not agreed who owned an automated approval error.
The correct decision was not "never use AI." It was "recommend, do not act, until the autonomy boundary is earned."
AI-native is often mistaken for full autonomy. That is a dangerous misunderstanding. AI-native means the workflow is redesigned around machine capability and human judgment. Sometimes that produces autonomy. Often it produces better assistance, better drafting, better routing, better decision support, or conditional action inside strict limits.
The autonomy boundary is the line between what the machine may do and what it may only propose.
Key Takeaways
- The workflow was technically automatable. That did not make it a good candidate for autonomy.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with AI-Native and the adjacent chapters when you need the wider AI-Native Engineering frame.
Capability is not permission
A model may be capable of producing an action. That does not mean it should be permitted to perform the action. Capability answers "can it?" Permission answers "may it?" AI-native design lives in the gap.
A model can draft a refund email. It may not be allowed to issue the refund. A model can suggest a discount. It may not be allowed to approve pricing. A model can generate a code patch. It may not be allowed to merge. A model can summarize a medical note. It may not be allowed to make a clinical decision. A model can classify a job applicant. It may not be allowed to decide employment. A model can identify suspicious activity. It may not be allowed to freeze an account without review.
The autonomy boundary depends on more than model quality. It depends on stakes, reversibility, evaluation strength, context completeness, legal constraints, user trust, monitoring, and repair capacity.
This is why high-level autonomy claims are useless. "Our agent can handle procurement" is not a meaningful operating statement. Which procurement tasks? Under what amount? For which vendors? With which data? Against which policy? With what confidence? With what audit? With what rollback? With what human approval? With what fraud controls? With what repair owner?
Autonomy is a design decision, not a vibe.
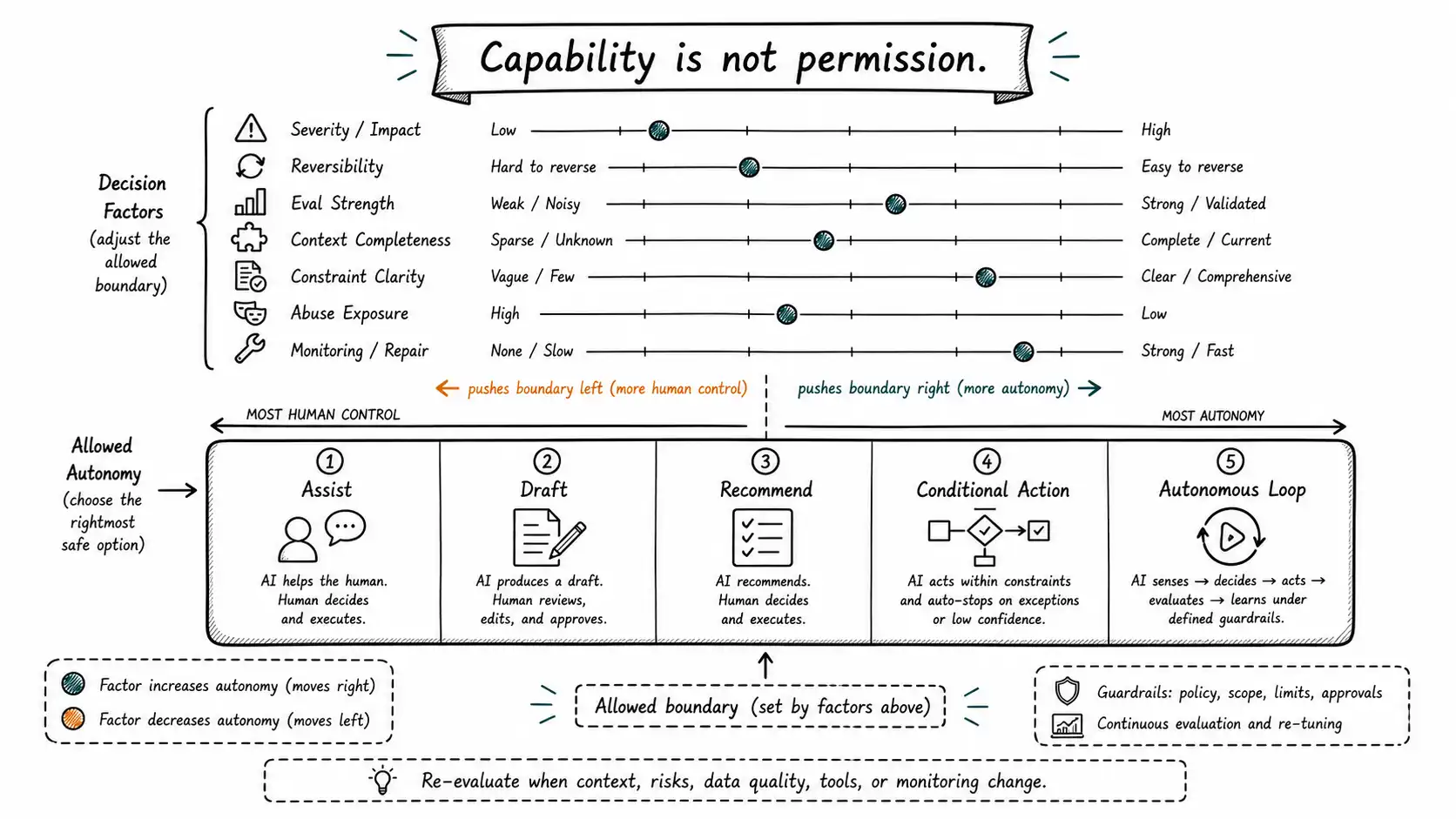
The Autonomy Boundary Test
The Autonomy Boundary Test forces a team to decide the allowed machine role for a workflow.
| Dimension | Low-risk answer | High-risk answer | Boundary implication |
|---|---|---|---|
| Consequence severity | Mistake is minor | Mistake causes harm, loss, legal exposure, outage, trust damage | Higher severity reduces autonomy |
| Reversibility | Easy to undo | Hard or impossible to undo | Irreversible actions need stronger human gate |
| Evaluation strength | Large representative evals, reliable outcome data | Sparse labels, ambiguous quality | Weak evals reduce autonomy |
| Context completeness | Required context is known and fresh | Important context is tacit, missing, stale, or political | Missing context reduces autonomy |
| Constraint clarity | Rules are explicit and codifiable | Rules are ambiguous or negotiated | Ambiguity reduces autonomy |
| Abuse/security exposure | Low adversarial incentive | High manipulation, prompt injection, fraud, data leakage risk | Higher exposure reduces autonomy |
| User expectation | Users expect automation | Users expect human care or expert judgment | Trust expectation shapes boundary |
| Monitoring and repair | Fast detection and repair | Slow detection, unclear repair owner | Weak repair reduces autonomy |
| Volume and value | High-volume routine cases | Low-volume bespoke cases | Routine volume supports bounded autonomy |
| Escalation path | Clear owner and SLA | Unclear or overloaded escalation | Weak escalation reduces autonomy |
A workflow with low severity, high reversibility, strong evaluation, complete context, clear constraints, low abuse risk, good monitoring, and a repair owner can support conditional autonomy. A workflow with high severity, poor reversibility, weak evaluation, incomplete context, ambiguous rules, or adversarial exposure should remain human-led or recommendation-only.
The maturity ladder
AI-native maturity should be described as a ladder, not a binary switch.
| Stage | Description | Signs | Main risk | Required control |
|---|---|---|---|---|
| 1. Tool use | Individuals use AI manually | Personal productivity, inconsistent practice | Shadow AI, data leakage, uneven quality | Usage guidance and data policy |
| 2. Assisted drafting | AI drafts artifacts for human editing | Emails, summaries, code snippets, documents | First-draft factory | Acceptance criteria and review rubrics |
| 3. Workflow augmentation | AI embedded in a workflow step | Classification, retrieval, routing, suggestions | Old bottlenecks remain | Workflow map and outcome metrics |
| 4. Machine-first production with human acceptance | Machine produces material work; humans accept | Draft responses, code patches, analysis memos | Review bottleneck | Evals, rejection labels, judgment gates |
| 5. Conditional autonomy | Machine acts under bounded rules | Small refunds, low-risk routing, simple updates | Boundary creep | Autonomy policy, monitoring, audit logs |
| 6. Closed-loop improvement | Failures update system artifacts | Eval updates, playbook changes, prompt/spec revisions | Learning from biased signals | Governance review and data quality checks |
| 7. Governed AI-native operation | Workflow is measured, owned, auditable, and continuously improved | Stable outcomes, clear owners, reliable escalation | Complacency and drift | Operating cadence, risk review, periodic redesign |
Most organizations overstate their maturity. Heavy tool usage is not maturity. A widely used assistant is not maturity. Even machine-first production is not maturity if acceptance, evaluation, and repair are weak.
The ladder also prevents premature autonomy. A workflow should not jump from assisted drafting to autonomous action because the demo was impressive. The stages represent control capability, not just model capability.
When not to make a workflow AI-native
A workflow may be technically possible and strategically wrong.
Be cautious when the workflow is:
- High-stakes and low-volume. Rare decisions with serious consequences often do not provide enough data for reliable evaluation, and the savings from automation may not justify risk.
- Relationship-dependent. Enterprise negotiation, executive escalation, sensitive employee relations, and complex customer recovery often depend on trust and tacit context.
- Legally or ethically sensitive. Employment, credit, healthcare, insurance, education, law enforcement, and similar domains require careful governance and may be subject to high-risk rules.
- Poorly evaluated. If the team cannot tell good output from bad output reliably, autonomy is premature.
- Contextually incomplete. If decisive information lives in people's heads, private channels, or unstructured relationships, machine output may be confidently incomplete.
- Adversarial. Fraud, security, abuse, and prompt-injection-prone workflows require stricter boundaries.
- Irreversible. Actions that cannot be undone require stronger human approval.
- Identity-defining. Some customer moments matter because a human shows up. Automating them may save cost and destroy trust.
This is not an argument against AI in these workflows. It is an argument for the right machine role. In a sensitive legal workflow, AI may summarize, compare, and surface deviations while lawyers own judgment. In a healthcare workflow, AI may prepare information and highlight risks while clinicians own decisions. In enterprise escalation, AI may assemble context and draft options while humans manage the relationship.
AI-native design includes restraint.
Security changes the boundary
Security and abuse risks deserve special attention because AI systems can turn text into action. Prompt injection, insecure output handling, sensitive information disclosure, excessive agency, and tool misuse are not abstract risks in agentic workflows. OWASP's Top 10 for LLM Applications is a practical starting point because it treats the LLM application as an attack surface, not just a model call.
The autonomy boundary should shift left when:
- The model reads untrusted text.
- The workflow can call tools that change state.
- The system has access to sensitive data.
- Users have incentives to manipulate output.
- The model can send messages externally.
- The workflow crosses permission boundaries.
- The action is hard to reverse.
For example, an internal knowledge assistant that summarizes read-only policy documents may be allowed to answer directly with citations. A procurement agent that reads vendor emails and can update bank details should not act autonomously without strong controls, because untrusted text plus financial action creates a dangerous channel.
Security is not a separate review after autonomy is chosen. Security is one of the forces that defines the boundary.
Risk, reversibility, and dignity
Risk is not only financial or legal. It includes customer trust and human dignity.
A fully automated support workflow may be acceptable for resetting a password or confirming a shipment date. It may be unacceptable for a bereavement-related travel issue, a healthcare billing dispute, a termination appeal, or a customer who has already contacted support five times. The machine may know the policy. It may not be the right representative of the company at that moment.
AI-native leaders should include dignity in the autonomy boundary. Ask:
- Would a reasonable customer expect human attention here?
- Is the user vulnerable, angry, confused, or in distress?
- Does the situation require empathy, apology, negotiation, or moral judgment?
- Would automation signal disrespect even if technically correct?
These questions cannot always be reduced to metrics, but they can be operationalized through escalation rules. A support system can route repeated contacts, distress language, legal threats, high-value accounts, safety issues, or sensitive life events to humans. A hiring system can use AI for scheduling and resume organization while keeping evaluative employment decisions human and auditable.
The fact that the machine can respond does not mean the company should let it represent the relationship.
Boundary creep
Autonomy often expands informally. A tool begins as a drafting assistant. Users trust it. Managers see speed. Someone enables auto-send for a low-risk category. Another team copies the pattern. Edge cases appear. Logging is incomplete. The system becomes more autonomous without a formal decision.
This is boundary creep.
Preventing boundary creep requires explicit change control. Any move from assist to draft, draft to recommend, recommend to conditional action, or conditional action to autonomous loop should require:
- Updated workflow map.
- Updated evals.
- Updated risk assessment.
- Updated acceptance criteria.
- Named owner.
- Rollback plan.
- Monitoring plan.
- Failure review after launch.
This may sound heavy, but the burden should scale with risk. A low-risk internal formatting assistant needs little ceremony. A customer-facing action system needs more. A regulated decision system needs much more.
AI-native maturity is the ability to scale controls proportionally, not to avoid controls entirely.
The boundary is a living artifact
The autonomy boundary should be reviewed regularly because models improve, workflows change, data quality shifts, regulations evolve, and failures reveal missing assumptions. A boundary that was too risky last year may become safe after better evals, clearer constraints, and stronger monitoring. A boundary that was safe last quarter may become unsafe after product changes or new abuse patterns.
The boundary review should ask:
- What is the current machine role?
- What evidence supports that role?
- Which failures occurred since the last review?
- Were any accepted outputs later reversed or repaired?
- Did context, policy, data, or user expectations change?
- Should autonomy expand, contract, or stay fixed?
- What must improve before expansion?
This review is not bureaucracy. It is the steering wheel.
AI-native work is not defined by maximum automation. It is defined by appropriate autonomy inside an accountable system. The strongest organizations will not be the ones that let machines do everything earliest. They will be the ones that know exactly where the machine may act, where it may recommend, where it may draft, and where it must remain silent. The AI-Native Operating System describes the cadence and governance that keep those boundaries governed over time.