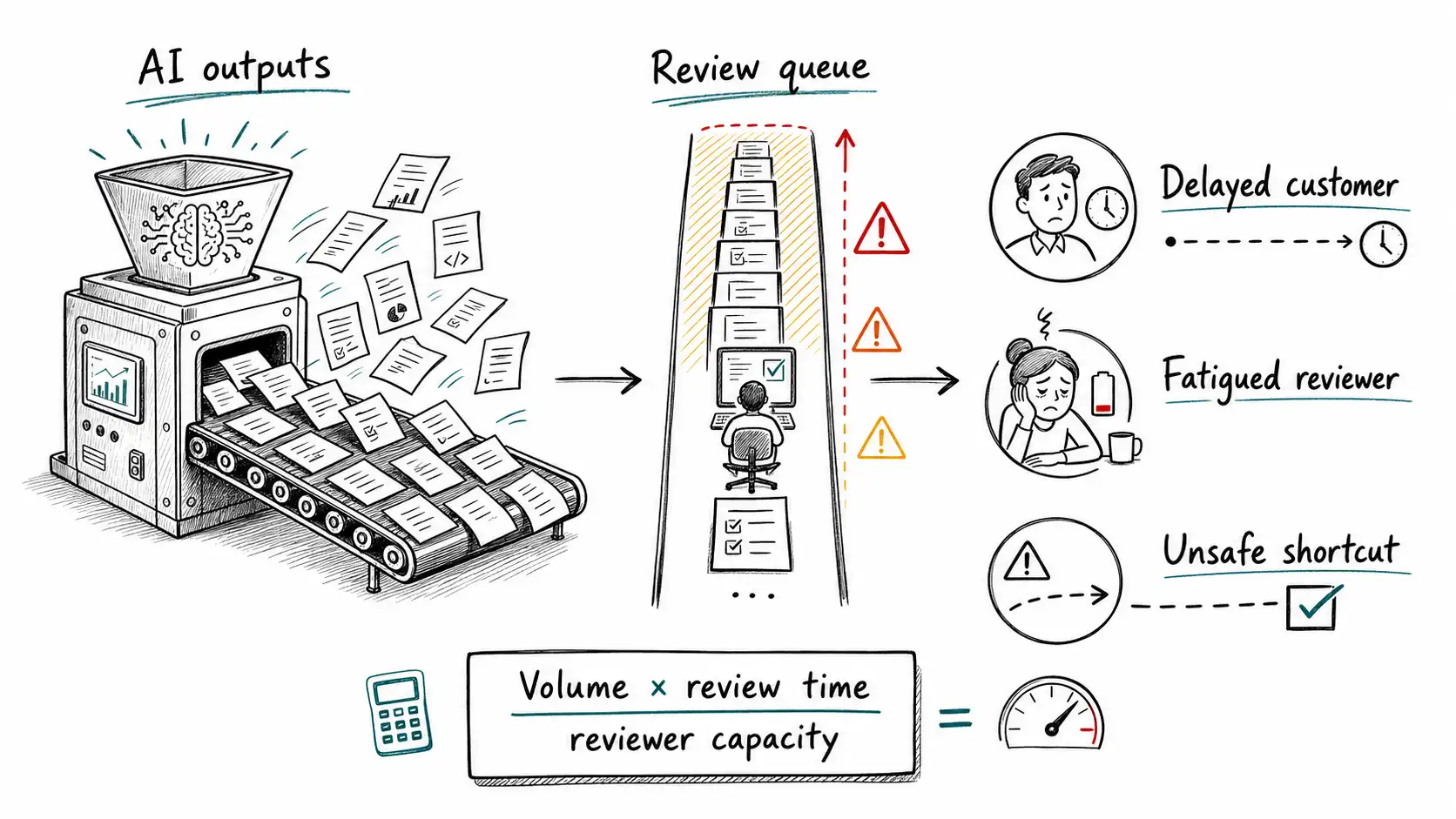
The Review Queue Collapse
At 9:10 on Monday morning, the support automation team believed they had solved the human-in-the-loop problem. No refund would be issued without a human review.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. At 9:10 on Monday morning, the support automation team believed they had solved the human-in-the-loop problem. No refund would be issued without a human review. No enterprise contract response would be sent without a human review. No cancellation-save offer would go out without a human review. The dashboard looked responsible because every risky action had a person in the loop.
By Thursday afternoon, the review queue had become the product.
The system generated 18,400 draft actions in four days. Each draft took an average of two minutes to review when it was obviously right, six minutes when it was ambiguous, and fifteen minutes when the reviewer had to open customer history, policy docs, and billing records. The team had five reviewers. They had designed a safe system on paper and an impossible system in production. By the time the first escalation hit leadership, customers were waiting longer for AI-reviewed responses than they had waited when humans wrote the responses from scratch.
This is the failure the phrase "human in the loop" hides. It sounds like a plan because it names a person. It is not a plan until it names capacity, criteria, evidence, authority, feedback, escalation, and what happens when volume exceeds review. A loop is an operating system, not a box on an architecture diagram.
The older literature on automation saw this coming. Lisanne Bainbridge's classic paper "Ironies of Automation" argued that automated systems often leave humans with the hardest work: monitoring, exception handling, and intervention after their manual skill has atrophied. The paper was written for industrial automation, but the pattern maps directly onto AI products. The machine handles common cases. The human receives the ambiguous cases, the edge cases, the risky cases, and the cases where the automation's internal state is hardest to interpret. Source: https://davidjusth.com/s/Ironies-of-Automation_Bainbridge_1983.pdf
In AI-native systems, the irony becomes sharper. The machine does not merely route work to humans. It creates a new class of work: reviewing plausible machine output. A human reviewer is not reading an empty ticket. They are reading a draft answer that may be mostly correct, subtly wrong, overconfident, stale, unauthorized, or unsupported. The work is cognitively different from doing the task directly. It requires comparing output to policy, evidence, context, and risk under time pressure.
The first honest claim of this book is simple: putting a human in the loop does not make a system safe. It moves risk into a queue. Whether the system becomes safer depends on how that queue is designed.
Key Takeaways
- The Review Queue Collapse names the operating decision a team has to make before it accepts the work.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with Human in the Loop Is Not a Plan and the adjacent chapters when you need the wider Evals and Evaluation frame.
The Loop Has a Unit Economics Problem
A human review process has throughput. That throughput is finite. If the system produces more reviewable decisions than reviewers can handle, the backlog grows. If the backlog grows in a user-facing workflow, the product degrades. If reviewers speed up to clear the backlog, review quality falls. If the company hires more reviewers without changing the system, automation savings disappear.
Consider a simple model:
| Variable | Meaning | Example |
|---|---|---|
| AI outputs per day | Number of items requiring potential review | 12,000 |
| Review rate | Average minutes per human review | 3 |
| Reviewer focus time | Effective review hours per reviewer per day | 5 |
| Daily capacity per reviewer | Reviews per day | 100 |
| Review-all staffing need | Reviewers needed if every item is reviewed | 120 |
The math is brutal because it is honest. Twelve thousand outputs at three minutes each require 36,000 minutes of review, or 600 reviewer hours. At five effective hours per reviewer per day, the team needs 120 reviewers. The phrase "human in the loop" did not mention 120 people. The architecture diagram did not mention 120 people. The product plan probably did not budget 120 people. The loop failed before launch because nobody priced it.
This is why human review must be treated as production capacity. It is not an ethical decoration. It is a resource with cost, latency, quality, variance, fatigue, scheduling, training, and failure modes. A system that depends on human review should have a capacity model just as surely as a system that depends on GPUs should have an inference cost model.
def reviewers_needed(outputs_per_day: int, minutes_per_review: float, focus_hours_per_day: float) -> float:
review_hours = outputs_per_day * minutes_per_review / 60
return review_hours / focus_hours_per_day
print(reviewers_needed(12000, 3, 5)) # 120.0
print(reviewers_needed(12000, 0.3, 5)) # 12.0 after triage and samplingThe second line is the design goal. A good loop does not review everything. It reduces the number of items needing full review, shortens the items that remain, and makes each review more evidence-rich. That is not cutting corners. That is designing the loop instead of pretending the loop is infinite.
Human Review Is Not One Activity
Teams often speak of "review" as if it were one thing. It is not. There is quality review, compliance review, approval review, escalation review, audit review, calibration review, sampling review, and incident review. Each has a different purpose.
A quality reviewer asks, "Is this output good enough?" A compliance reviewer asks, "Is this output allowed?" An approver asks, "Should the system take this action?" A calibration reviewer asks, "Do reviewers agree on the rubric?" An audit reviewer asks, "Can we explain what happened later?" These are distinct jobs. A single human may do several, but the system should not confuse them.
This distinction matters because the right design depends on the review purpose. If the task is approval, the reviewer needs authority and action context. If the task is calibration, the reviewer needs blind examples and comparison against other reviewers. If the task is compliance, the reviewer needs policy references and a defensible record. If the task is sampling, the reviewer needs representative coverage, not only the scariest cases.
The collapse story at the beginning failed partly because every review type was placed into one queue. Reviewers were asked to approve, correct, calibrate, audit, and teach the model in the same interface. They could not optimize for all of those at once. The product needed multiple loops, not one loop.
The Hidden Latency of Judgment
AI systems often reduce execution latency while increasing decision latency. The model can draft a response in seconds, but the organization may take hours to decide whether that response can be trusted. The user experiences the total latency, not the model latency. When teams celebrate faster generation while ignoring slower acceptance, they optimize the wrong part of the system.
This becomes visible in workflows with a deadline. A sales quote generated in twenty seconds but reviewed in two days is not a twenty-second sales tool. A clinical summary drafted instantly but waiting for physician review until after the appointment is not a real-time assistant. A fraud system that flags transactions quickly but waits for manual review while customers are blocked may create more harm than the old rule-based system.
The correct metric is not "time to generate." It is "time to safe action." Safe action is the moment the system can do something useful without creating unacceptable risk. Human review is part of that path. If review dominates the path, the product is not AI-fast. It is review-bound.
The First Design Principle
The first principle of this book is therefore: do not add a human loop until you know what the loop is for.
A loop may exist to prevent harm, to collect labels, to calibrate uncertainty, to approve irreversible actions, to handle exceptions, or to maintain trust with customers and regulators. Each purpose implies a different interface, sampling policy, reviewer skill set, and metric. A vague loop does not solve risk. It hides it.
Chapter Takeaway
Human-in-the-loop is not a safety mechanism by itself. It is a production queue with cost, latency, skill, capacity, and failure modes. If you do not design the queue, the queue designs the product.
The Review Queue as a Product Surface
The queue is not merely internal operations. It is a product surface because its behavior determines what users experience. If review takes six hours, the user experiences six-hour automation. If reviewers reject 30% of outputs because the model often retrieves stale policy, the user experiences a system that promises speed and delivers uncertainty. If a high-value customer's case sits behind thousands of low-risk cases, the product has made a prioritization decision whether or not anyone named it.
This is why review queues need service levels. A support-review queue may promise that orange-tier cases are reviewed within thirty minutes during business hours and within two hours overnight. A code-review queue for generated security-sensitive diffs may promise same-day review only if the review packet is complete. A clinical or financial workflow may have stricter or legally defined timing. The specific SLA depends on the domain, but the existence of an SLA changes the conversation. It forces the team to ask whether volume, staffing, and automation match the product promise.
The queue also needs triage rules. First-in-first-out sounds fair but often is not. A low-risk wording issue should not block a high-risk customer refund. A policy ambiguity affecting many future outputs may deserve faster escalation than a one-off correction. A reviewer interface should therefore support priority, grouping, and escalation rather than presenting an undifferentiated stream of machine work.
When Review Makes Quality Worse
Human review can make quality worse when it is poorly designed. This surprises teams because they assume "more review" is always safer. It is not. A rushed reviewer may approve a plausible but wrong output because the model's writing looks polished. A reviewer without context may edit tone while missing a factual error. A reviewer measured on throughput may optimize for speed. A reviewer whose corrections are ignored may stop caring. A reviewer who sees only escalated failures may develop a distorted view of the system and overcorrect benign cases.
Review can also destroy ownership. If every AI output is reviewed by operations, product and engineering may stop feeling accountable for quality. The loop becomes a human patch over an underdeveloped system. Reviewers absorb defects that should have been fixed upstream. The organization calls the system "safe" because humans are catching failures, but the failure rate never falls.
A healthy loop has a decreasing-defect expectation. If reviewers see the same reason code repeatedly, the owner must fix the upstream cause. If unsupported claims dominate, improve retrieval or generation constraints. If policy ambiguity dominates, rewrite policy. If reviewers repeatedly add the same sentence, change the prompt or product flow. A loop that does not reduce recurring work is not learning; it is laundering defects through humans.
The Queue Collapse Warning Signs
A review queue is approaching collapse when queue age grows faster than volume, when reviewers begin bulk-approving, when reason codes become generic, when escalations sit unresolved, when sampled failures repeat, when reviewers create private shortcuts, when product teams ask reviewers to "just get through it," and when leadership hears about backlog only after customers complain.
These signs should trigger an operational response, not a motivational speech. Reduce autonomy, narrow the workflow, improve evidence packets, change tier thresholds, add temporary reviewers, pause the launch, or remove a feature from the AI path. The responsible decision may be to ship less autonomy until the loop can handle more.
The lesson is uncomfortable but liberating: review is part of the system. Once teams accept that, they can design it, measure it, improve it, and decide where it is not worth the cost.