The LOOP-SAFE Framework
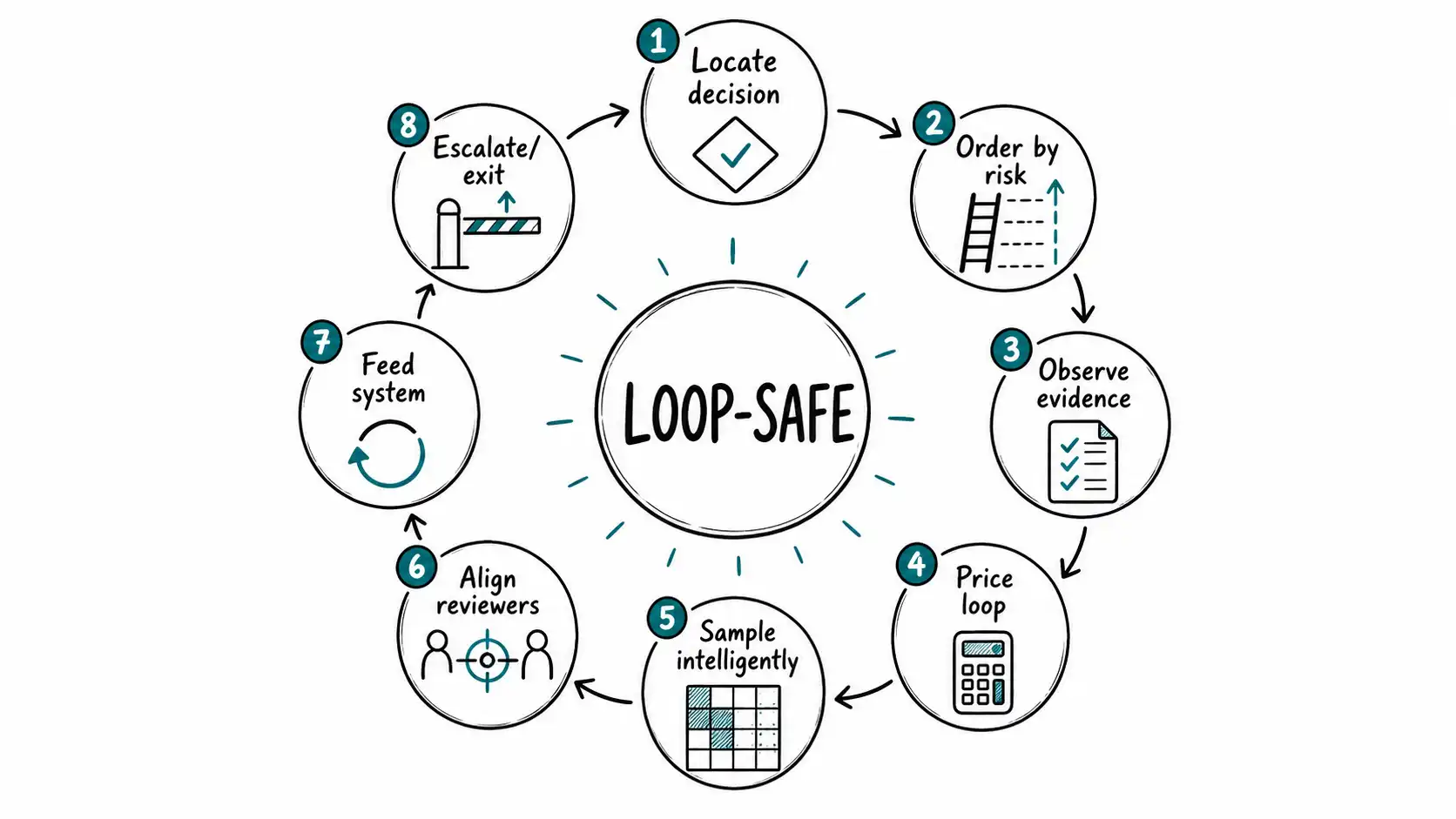
This book needs a compact operating framework because "human review" can sprawl into policy, product, operations, UX, compliance, data, and machine learning. The framework is called LOOP-SAFE.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. This book needs a compact operating framework because "human review" can sprawl into policy, product, operations, UX, compliance, data, and machine learning. The framework is called LOOP-SAFE. It is not meant to be clever. It is meant to be hard to forget.
L - Locate the decision. What exact decision or action needs oversight?
O - Order by risk. Which cases are low, medium, high, or prohibited?
O - Observe the evidence. What must a reviewer or evaluator see to judge correctly?
P - Price the loop. What are the cost, latency, staffing, and fatigue implications?
S - Sample intelligently. What will be reviewed, sampled, or audited after action?
A - Align reviewers. How will rubrics, calibration, and disagreement be managed?
F - Feed the system. How does review become evals, labels, policies, or product changes?
E - Escalate and exit. What happens when the loop cannot decide or capacity is exceeded?
The framework is deliberately operational. It avoids abstract statements like "ensure humans remain in control" because those statements do not tell a team how to ship. LOOP-SAFE asks for artifacts: decision inventory, risk tiers, evidence packet, capacity model, sampling policy, reviewer rubric, feedback schema, and escalation plan.
Key Takeaways
- The LOOP-SAFE Framework names the operating decision a team has to make before it accepts the work.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with Human in the Loop Is Not a Plan and the adjacent chapters when you need the wider Evals and Evaluation frame.
L - Locate the Decision
The first failure is reviewing the wrong thing. A system may generate text, choose a tool, retrieve documents, classify risk, recommend an action, and execute that action. Which of these needs human oversight? The answer is rarely "all of them." It is also rarely "only the final answer."
In a RAG assistant, the risky decision may be retrieval: which source should be used. In a support workflow, it may be whether the customer is eligible for a refund. In an agentic workflow, it may be the tool call that changes state. In a code-generation workflow, it may be accepting a diff that touches authorization. Locating the decision prevents review from focusing on surface output while missing the load-bearing step.
A decision inventory helps:
| Workflow | AI step | Decision made | Action consequence | Oversight target |
|---|---|---|---|---|
| Support reply | Retrieve policy | Which policy governs case | Wrong answer if stale | Retrieval and citation |
| Refund agent | Select action | Offer refund or escalate | Money movement | Action approval |
| Code assistant | Generate diff | Change permission logic | Security regression | Diff acceptance |
| Sales copilot | Draft discount | Recommend price concession | Margin leakage | Pricing approval |
The review target should be the earliest point where the system can still prevent harm. Reviewing the final customer email may be too late if the wrong policy was retrieved and the email looks polished.
O - Order by Risk
Risk tiering is the difference between a scalable loop and a review swamp. Not every item deserves equal scrutiny. The system should classify outputs or actions by potential harm, uncertainty, reversibility, policy sensitivity, and novelty.
A useful four-tier model:
| Tier | Meaning | Default behavior |
|---|---|---|
| Green | Low harm, common, reversible | Auto-act with post-action sampling |
| Yellow | Some uncertainty or moderate impact | Auto-act if confidence and rules pass; sample heavily |
| Orange | High impact, policy ambiguity, unusual case | Pre-action human review |
| Red | Prohibited or unsafe | Block and escalate |
The tier is not the model's confidence. Confidence may inform the tier, but tiering must include business risk. A model can be confident about a high-risk wrong action. A low-confidence draft internal summary may still be harmless. Risk tiering belongs to the product and governance design, not only to the model.
O - Observe the Evidence
Review without evidence creates false accountability. The LOOP-SAFE evidence step asks what the reviewer must see to judge correctly. The answer should be minimal but sufficient. Too little evidence produces guesses. Too much evidence produces fatigue. The design problem is not to show everything; it is to show the right things.
Evidence should be typed. Source evidence supports factual claims. Context evidence explains the user or case. Model evidence explains how the output was produced. Policy evidence explains what rule applies. Operational evidence shows whether the system is in a known-good state. For example, a reviewer approving an enterprise refund needs the customer contract, refund policy, transaction history, model recommendation, reason for review, and allowed reviewer actions. They do not need every customer ticket from the past five years.
P - Price the Loop
Pricing the loop means calculating human cost and product latency before launch. The capacity formula from Chapter 1 should become a standard release artifact. How many items per day enter the loop? How long does review take? How many reviewers are available? What is the expected peak? What is the backlog policy? What happens during holidays, outages, or product launches?
A loop with no capacity plan is an unbounded liability. The worst version is a safety-critical system whose safety mechanism collapses exactly when volume spikes. For example, a fraud review loop may receive more cases during an attack. A content moderation loop may spike during a news event. A support review loop may spike after an outage. If the loop is not designed for peaks, it will fail when it is most needed.
S - Sample Intelligently
Sampling is how the system learns from cases it did not block. Random sampling gives baseline quality. Stratified sampling gives coverage across risk groups, user segments, languages, products, and model confidence bands. Targeted sampling focuses on known weak areas. Adversarial sampling searches for failures. Audit sampling creates evidence for governance.
Sampling should not be an afterthought. It is the difference between knowing only what reviewers saw and knowing how the whole system behaves. A team that reviews only escalated cases learns only about escalated cases. A team that samples intelligently learns about silent failures.
A - Align Reviewers
Reviewer disagreement is data. If two trained reviewers disagree on whether an AI output is acceptable, the problem may be the model, the output, the rubric, the policy, or the reviewers' training. Treat disagreement as a signal, not a nuisance.
Alignment requires rubrics, calibration sessions, gold examples, disagreement tracking, and periodic measurement. The goal is not perfect agreement; complex judgment will always contain ambiguity. The goal is to know where ambiguity lives and prevent the system from hiding it.
F - Feed the System
A review loop should feed at least four downstream systems: the eval suite, the training or preference dataset where appropriate, the policy catalog, and product design. If reviewers repeatedly reject outputs because the same policy is unclear, the fix may be policy writing, not model tuning. If reviewers repeatedly correct tone but not substance, the fix may be prompt design. If reviewers repeatedly catch missing context, the fix may be retrieval or data integration.
Feedback without routing is waste. Routing without ownership is also waste. Every reason code should have an owner.
E - Escalate and Exit
Finally, the loop needs an exit. What happens when the reviewer cannot decide? What happens when reviewers disagree? What happens when the queue exceeds capacity? What happens when the system detects a new class of failure? What happens when a customer appeals?
Escalation paths should be explicit and rehearsed. Exit criteria should exist for both individual items and the whole workflow. A loop may be paused if quality drops below a threshold. A high-risk action class may be disabled if review capacity falls. A model version may be rolled back if sampling detects a regression.
Chapter Takeaway
LOOP-SAFE turns human oversight from a slogan into an operating model: locate the decision, tier the risk, give reviewers evidence, price the queue, sample intelligently, align judgment, feed learning, and define exits.
Applying LOOP-SAFE to a Real Workflow
Consider an AI assistant that drafts customer support resolutions. The initial product proposal says all AI replies will be reviewed by humans. LOOP-SAFE makes the proposal concrete.
Locate the decision. The risky decision is not "write reply." It is "tell the customer the issue is resolved and state what the company will do next." That decision may include policy interpretation, refund eligibility, account state, and tone.
Order by risk. Password-reset instructions are green. A normal shipping-status explanation is green or yellow. A refund under $50 may be yellow. A refund above $500 is orange. A legal threat, medical question, or cross-tenant data exposure is red.
Observe evidence. Reviewers need the customer request, account status, retrieved policy, draft reply, cited sources, reason for tier, and allowed actions. They do not need unrelated account history.
Price the loop. The team estimates daily volume by tier. Green replies are auto-sent and sampled. Yellow replies are sampled at a higher rate. Orange replies require approval. Red cases block and escalate. The review staffing need becomes visible before launch.
Sample intelligently. The team samples by language, policy area, customer segment, and confidence band. It oversamples newly changed prompts and newly ingested policy documents.
Align reviewers. The team creates a support-resolution rubric, runs calibration sessions, tracks disagreement, and updates examples.
Feed the system. Rejections become reason-coded feedback. Unsupported claims become eval cases. Wrong-policy failures become retrieval fixes. Ambiguous policy failures route to policy owners.
Escalate and exit. If queue age exceeds SLA, orange cases fall back to manual support rather than waiting behind the AI queue. If unsupported-claim failures spike, the workflow reduces autonomy and requires approval for more cases.
The framework changes the product from "humans will check it" to a measurable operating system. It also reveals where AI is not ready. If too many cases route orange, the model or workflow may not yet justify its autonomy. If reviewers cannot agree, the rubric or policy may be immature. If evidence packets are incomplete, the integration work is not done.
LOOP-SAFE as a Launch Review
LOOP-SAFE can be used as a launch gate. A product should not launch a new autonomous capability until each letter has an artifact. The decision inventory covers L. The risk policy covers O. The evidence packet covers O. The capacity model covers P. The sampling plan covers S. The calibration rubric covers A. The feedback schema covers F. The escalation playbook covers E.
This gate is not anti-speed. It prevents the team from discovering missing oversight in production. It also gives stakeholders a common language. Legal can challenge the risk tier. Operations can challenge the capacity model. Product can challenge the user latency. Engineering can challenge the evidence packet. Reviewers can challenge the rubric. The framework turns vague concern into specific design work.
The Danger of Partial Loops
A partial loop can be worse than no loop because it creates confidence without control. A team may have risk tiering but no capacity plan. It may have reviewers but no rubric. It may have feedback but no owner to act on it. It may have sampling but no eval promotion. It may have escalation but no authority. Each missing piece converts oversight into theater.
A quick diagnostic: pick ten recent reviewed items and ask whether the loop produced an improvement beyond the individual decision. Did it add an eval? Update a rule? Improve a prompt? Fix retrieval? Clarify policy? Train reviewers? If the answer is usually no, the loop is consuming judgment rather than compounding it.
The Framework Is Reusable Across Domains
LOOP-SAFE works because it does not assume the task. A healthcare triage assistant, a code-generation system, a sales-discount copilot, and a support-resolution agent all need to locate decisions, order risk, observe evidence, price the loop, sample, align reviewers, feed learning, and define escalation. The artifacts differ, but the control structure is the same.
That reuse matters for organizations with many AI efforts. Without a common framework, every team invents oversight language from scratch. With a shared framework, governance can compare systems without flattening them. The healthcare workflow may have stricter red-tier rules than the sales workflow, but both can be reviewed through the same questions.