Rubrics, Calibration, and Disagreement
A review loop is only as good as the judgment it applies. Judgment does not become reliable merely because a human performed it.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. A review loop is only as good as the judgment it applies. Judgment does not become reliable merely because a human performed it. Humans disagree. Humans fatigue. Humans anchor on machine suggestions. Humans interpret policies differently. Humans improve with calibration and degrade without it.
This chapter treats reviewer judgment as a system component. That may sound cold, but it is respectful. If the organization depends on people to make difficult calls, it owes them clear rubrics, good tools, training, manageable volume, disagreement processes, and feedback about how the system is performing. "Use your judgment" is not a process. It is a way to make individuals absorb ambiguity the organization has not resolved.
Key Takeaways
- A review loop is only as good as the judgment it applies. Judgment does not become reliable merely because a human performed it.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with Human in the Loop Is Not a Plan and the adjacent chapters when you need the wider Evals and Evaluation frame.
Rubrics Turn Values Into Decisions
A rubric is a structured way to apply judgment consistently. It names dimensions, levels, examples, and unacceptable conditions. For AI output review, rubrics often include factual grounding, policy compliance, completeness, tone, privacy, safety, actionability, and citation quality.
A support-response rubric might look like this:
| Dimension | Pass | Borderline | Fail |
|---|---|---|---|
| Grounding | Every factual claim is supported by provided sources | Minor unsupported wording, no material risk | Material claim unsupported or contradicted |
| Policy compliance | Matches current approved policy | Policy applies but wording ambiguous | Uses wrong policy or outdated rule |
| Customer actionability | Customer knows what happens next | Some next step implied | No clear next step |
| Privacy | No unnecessary personal data exposed | Includes low-risk redundant detail | Exposes sensitive or cross-tenant data |
| Tone | Respectful and specific | Generic but acceptable | Dismissive, misleading, or overconfident |
The rubric should be attached to the workflow, not hidden in training slides. Reviewers should see it in the interface. The AI system should be evaluated against it. Generated outputs should be designed to make rubric evaluation easier: cite sources, separate facts from recommendations, show uncertainty, and label assumptions.
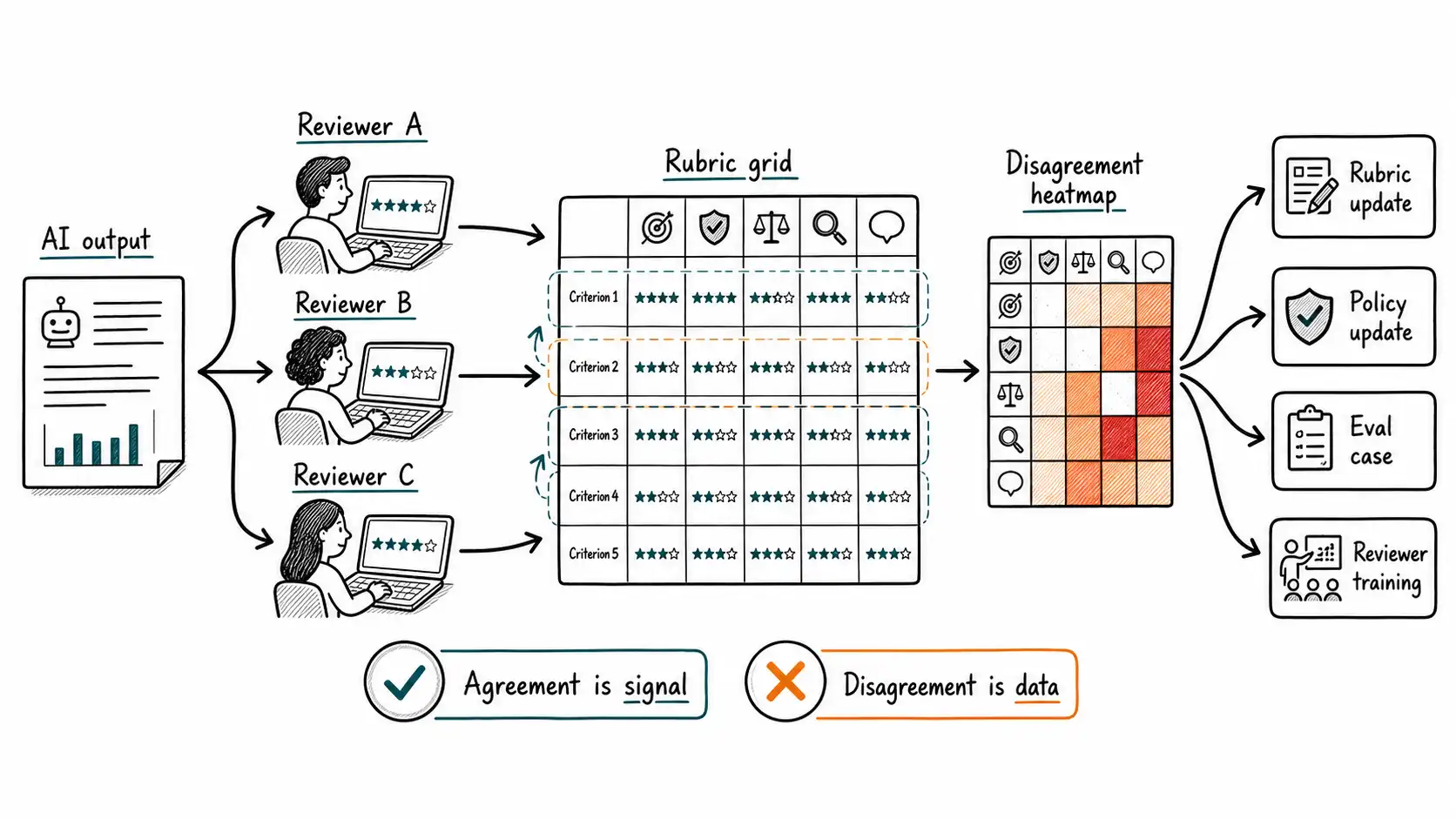
Calibration Is a Practice, Not a Meeting
Reviewer calibration means checking whether reviewers apply the rubric similarly. It usually requires a shared set of cases, independent review, comparison, discussion, and rubric adjustment. Calibration should happen before launch and continue after launch because workflows drift.
A lightweight calibration process:
- Select 30 recent cases across tiers and known edge cases.
- Have reviewers score independently without seeing each other's decisions.
- Measure agreement by dimension.
- Discuss disagreements, not to force consensus but to identify ambiguity.
- Update rubric, examples, or policy.
- Add persistent disagreement cases to the example library.
The point is not to turn reviewers into identical machines. The point is to find where the rubric does not support the decision. If reviewers disagree on tone, perhaps tone examples are weak. If they disagree on policy compliance, perhaps the policy is ambiguous. If they disagree on grounding, perhaps source presentation is poor. Disagreement tells the team where the system's judgment interface is under-specified.
Measuring Agreement
Inter-rater agreement metrics such as Cohen's kappa or Krippendorff's alpha can help, but they should not become theater. For many product teams, simple dimension-level disagreement rates are more actionable.
| Rubric dimension | Agreement | Interpretation |
|---|---|---|
| Privacy | 98% | Rule likely clear |
| Grounding | 86% | Usable but needs examples |
| Tone | 72% | Rubric too vague |
| Policy compliance | 61% | Policy ambiguity or poor source display |
This table is more useful than a single agreement score because it points to fixes. A low policy-compliance agreement rate may require policy rewriting, not reviewer retraining. A low grounding agreement rate may require better citation display or source highlighting. A low tone agreement rate may require examples of acceptable and unacceptable phrasing by customer segment.
Automation Bias and Suggestion Design
Human reviewers are influenced by machine suggestions. If the interface shows a confident AI recommendation, reviewers may approve it faster and scrutinize less. This is not a moral weakness. It is a known human factors issue. Automation changes attention.
Design can reduce the bias. For high-risk cases, the system can hide the model's recommended action until the reviewer has inspected evidence. It can require reviewers to select reason codes before seeing the model explanation. It can present counter-evidence alongside evidence. It can randomize some calibration cases where the model output is intentionally flawed to measure reviewer sensitivity. It can show uncertainty as a reason to inspect, not as decorative probability.
Microsoft's human-AI guidelines include ideas such as making clear what the system can do, supporting efficient correction, and enabling recovery from errors. Source: https://www.microsoft.com/en-us/research/publication/guidelines-for-human-ai-interaction/ In review systems, those principles translate into interfaces that make uncertainty, evidence, and reviewer control visible.
Reviewer Fatigue
Reviewers tire. Fatigue reduces attention and consistency. AI review can be especially fatiguing because outputs are plausible. The reviewer must detect subtle errors, not obvious blanks. This is closer to proofreading a confident junior colleague than filling a form. It drains attention.
Fatigue should be measured operationally. Track review time by hour, disagreement by hour, reversal rates, skipped fields, reason-code entropy, and appeal outcomes. Rotate reviewers across task types. Limit continuous high-risk review sessions. Give reviewers feedback about outcomes so the work has meaning. A reviewer who never sees whether approved actions were correct cannot calibrate their own judgment.
Disagreement as Product Feedback
When reviewers disagree, the team should avoid the reflex to ask "who is right?" Sometimes one reviewer is right. Often the deeper answer is that the product has not made a decision. Should enterprise customers receive more flexible refund wording? Should the assistant mention uncertain timelines? Should a policy exception be offered proactively or only after complaint? These are product and policy questions revealed by review disagreement.
A disagreement log should therefore have a routing path:
disagreement_case:
workflow: support_resolution
item_id: rev_2026_04_1182
dimension: policy_compliance
reviewer_a: pass
reviewer_b: fail
root_cause_after_discussion: policy_ambiguous
routed_to: policy_owner_refunds
action:
- update_policy_text
- add_eval_case
- retrain_reviewer_examplesThe loop improves only if disagreement changes something. Otherwise the same ambiguity returns every week.
Calibrating AI Judges
Some teams use models as judges for evals or review assistance. This can be useful, but an AI judge is not a free source of truth. It also needs calibration against human-labeled examples, drift monitoring, prompt versioning, and disagreement analysis. A judge model may be good at checking format and citation presence but weaker at domain policy nuance. It may agree with humans on easy cases and fail exactly where human review matters.
The safe pattern is to use AI judges as triage and measurement aids, not as unquestioned authorities. Compare judge decisions to calibrated human labels. Track judge-human disagreement. Use judges to reduce reviewer load only where evidence shows they are reliable. OpenAI's evals tooling and the broader ecosystem around benchmark and task evaluation are useful here because they encourage explicit datasets, graders, and repeatable scoring rather than one-off subjective impressions. Source: https://developers.openai.com/api/docs/guides/evals
Chapter Takeaway
Human judgment scales only when rubrics, calibration, disagreement tracking, and reviewer fatigue are treated as production concerns.
Rubric Granularity
Rubrics fail when they are too vague or too detailed. A vague rubric says "answer should be helpful." Reviewers cannot apply that consistently. An over-detailed rubric has dozens of criteria and slows review until people ignore it. The right rubric names the dimensions that change decisions and gives enough examples to make borderline cases discussable.
A useful design test: can a trained reviewer apply the rubric in under two minutes for a normal case, and can two reviewers explain a disagreement by pointing to a specific rubric line? If not, the rubric is either too vague or too heavy.
Rubrics should also separate severity. A typo and an unsupported legal claim are both defects, but they should not carry the same consequence. Severity helps the system learn. Low-severity defects may guide prompt improvements. High-severity defects may block release, reduce autonomy, or trigger incident review.
Golden Review Sets
A golden review set is a collection of cases with agreed labels and explanations. It is used to train reviewers, calibrate new reviewers, evaluate AI judges, and detect drift in human judgment. The set should include easy cases, hard cases, historical failures, and domain-specific edge cases. Each case should include the expected decision and why.
Golden sets should be updated cautiously. If every new opinion changes the gold label, the set loses stability. If the set never changes, it becomes stale. A good process requires owner approval for gold-label changes and records the rationale. When policy changes, affected gold cases should be reviewed and versioned.
Reviewer Interfaces Teach Judgment
The interface can teach or distort the rubric. If the reject button is hidden, rejection rates fall. If the model answer is visually dominant and the sources are collapsed, reviewers focus on fluency rather than evidence. If reason codes are too hard to select, feedback quality drops. If editing is easier than rejecting, reviewers may patch bad outputs instead of identifying root causes.
Design the interface around the judgment you want. Show the rubric. Show source evidence beside claims. Highlight missing required fields. Make escalation easy. Require reason codes for rejections. Allow reviewers to flag policy ambiguity. Keep review actions limited and clear. A good review interface is a judgment instrument, not a generic admin screen.
Disagreement Is Not Always Bad
Some disagreement is desirable because it reveals meaningful ambiguity. If all reviewers agree immediately on every case, the system may be reviewing only easy cases or suppressing uncertainty. The goal is not zero disagreement. The goal is understood disagreement. Which dimensions are subjective? Which policies are ambiguous? Which customer contexts require escalation? Which model outputs create misleading confidence?
Treat disagreement review as product discovery. The cases reviewers argue about are often the cases where customers, regulators, or executives will also care. They deserve attention.
Rubrics for Non-Deterministic Output
AI outputs vary. A rubric should allow multiple acceptable answers while still rejecting unsafe or incorrect ones. This is different from ordinary test assertions. The goal is not one exact sentence. The goal is a set of acceptable properties: supported by sources, no prohibited claims, clear next step, correct tone, no privacy leak.
This is where rubrics and evals meet. A deterministic test can check JSON shape. A rubric can judge whether the output was grounded. An AI judge can assist if calibrated. A human can resolve ambiguity. The workflow should use the cheapest reliable judge for each dimension. Format can be automatic. Policy nuance may need human review. Tone may be sampled. Safety may require strict rules.
Reviewer Training Data
Reviewer training should use real examples from the workflow, not abstract policy slides. Show approved cases, rejected cases, borderline cases, and historical misses. Include why decisions were made. Ask reviewers to score independently, then discuss. This builds shared judgment and reveals where the rubric is unclear.
Training should continue after launch. New policy, new model behavior, new product surfaces, and new customer segments all change the review task. A reviewer trained once and left alone will drift because the system around them changes.
Appeal Outcomes Close the Loop
If users or downstream teams can appeal AI-assisted decisions, appeal outcomes should feed rubric calibration. Appeals are valuable because they reveal errors that survived the original loop. A high appeal reversal rate means the review process is not catching something. Perhaps reviewers lack evidence. Perhaps the rubric undervalues customer context. Perhaps the risk tier is wrong. Appeals should not sit in a separate customer-success system disconnected from evals. They are late-arriving labels about the oversight system itself.