Risk-Tiered Review and the Capacity Math
The most important human review design decision is not interface layout. It is risk tiering.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The most important human-review design decision is not interface layout. It is risk tiering.
Without risk tiering, teams face an impossible tradeoff. Review everything and the system becomes too slow and expensive. Review nothing and the system becomes unsafe. Risk-tiered review breaks the false binary. It lets low-risk work move quickly, high-risk work slow down, and prohibited work stop. It also lets humans spend judgment where judgment matters.
This chapter is deliberately mathematical because review capacity is where many AI systems become economically incoherent. A team can be philosophically committed to responsible oversight and still fail if the numbers do not work.
Key Takeaways
- The most important human review design decision is not interface layout. It is risk tiering.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with Human in the Loop Is Not a Plan and the adjacent chapters when you need the wider Evals and Evaluation frame.
The Review Capacity Equation
The core equation:
required_reviewer_hours =
items_per_day
x review_rate
x minutes_per_review
/ 60The staffing equation:
reviewers_needed =
required_reviewer_hours
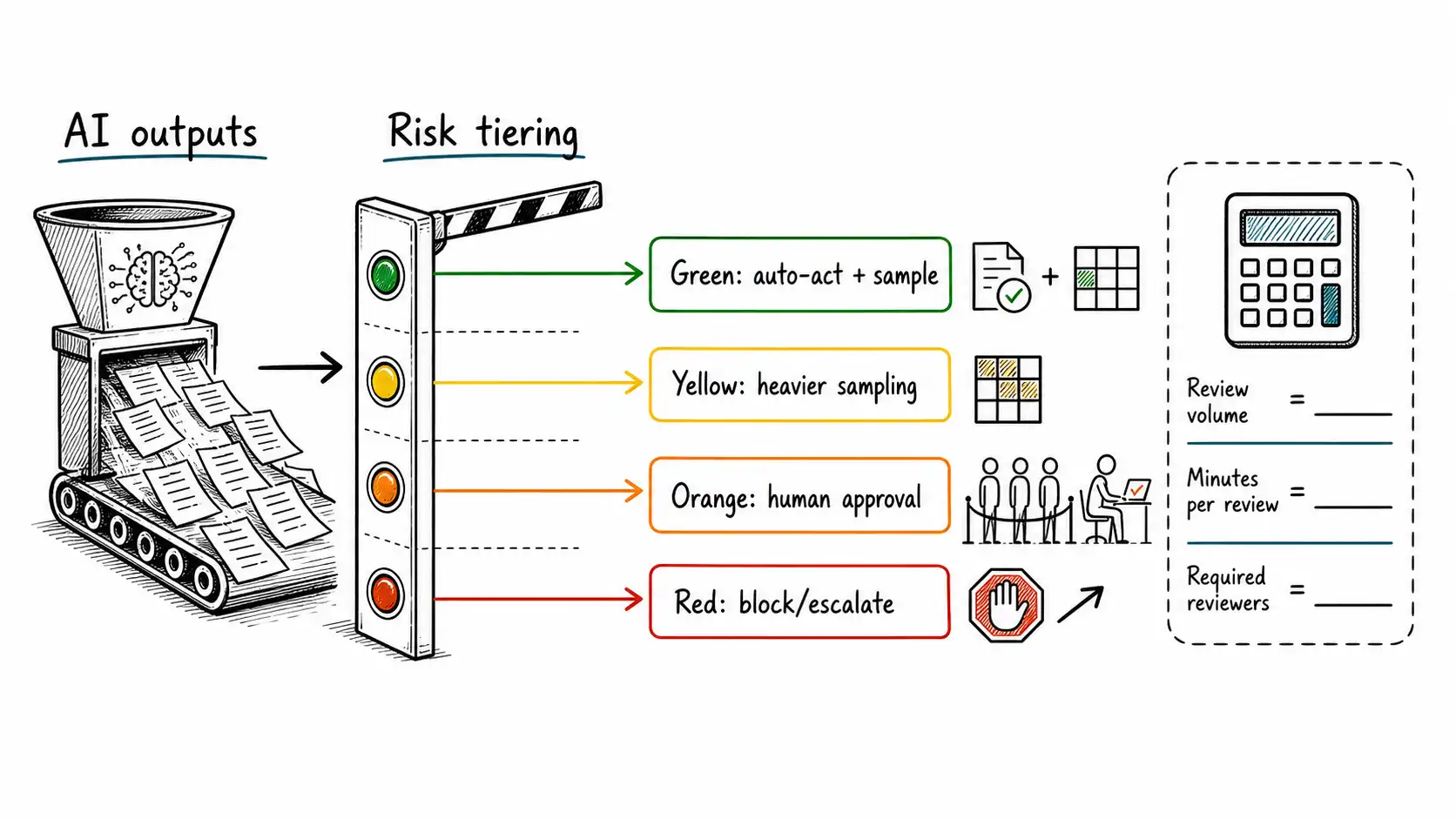
/ effective_review_hours_per_reviewerReview rate is the percentage of items that require human review. If a workflow produces 20,000 AI outputs per day, review-all has a review rate of 1.0. If risk tiering sends only 8% to pre-action review and 5% to post-action audit sampling, the total review rate is 0.13, though the pre-action and post-action queues should be tracked separately.
Example:
| Scenario | Outputs/day | Review rate | Minutes/review | Reviewer hours | Reviewers at 5 hrs/day |
|---|---|---|---|---|---|
| Review everything | 20,000 | 100% | 3.0 | 1,000 | 200 |
| Risk-tiered baseline | 20,000 | 12% | 3.5 | 140 | 28 |
| Better evidence packet | 20,000 | 12% | 1.8 | 72 | 15 |
| Better automation + sampling | 20,000 | 6% | 1.8 | 36 | 8 |
The table shows why review design is product economics. The same AI feature can require 200 reviewers or 8 reviewers depending on routing, evidence, and sampling. This is not a rounding error. It decides whether the product can exist.
Tiering Inputs
Risk tiering should combine at least six signals:
- Potential harm. What goes wrong if the output is wrong?
- Reversibility. Can the action be undone cleanly?
- Uncertainty. How confident is the system, and how well-calibrated is that confidence?
- Novelty. Is this case similar to known cases or outside distribution?
- Policy sensitivity. Does the case involve regulated, legal, financial, medical, safety, or privacy concerns?
- Customer or business impact. Does this touch strategic accounts, large payments, public communications, or contractual commitments?
The model can help estimate some of these, but it should not own the final tiering policy. The tiering policy is a business and risk artifact. It should be reviewed by the teams that own the consequences.
A practical tiering config:
workflow: customer_support_resolution
risk_tiers:
green:
description: common, low harm, reversible
action: auto_send
post_action_sample_rate: 0.03
yellow:
description: moderate uncertainty or customer impact
action: auto_send_with_logging
post_action_sample_rate: 0.15
triggers:
- model_confidence_below: 0.82
- customer_segment: enterprise_trial
orange:
description: high impact or policy ambiguity
action: require_human_approval
triggers:
- refund_amount_above: 500
- policy_conflict_detected: true
- source_missing: true
red:
description: prohibited or unsafe
action: block_and_escalate
triggers:
- legal_threat_detected: true
- medical_advice_requested: true
- cross_tenant_data_detected: trueThis kind of artifact does three things. It makes the loop inspectable. It gives engineers implementation guidance. It gives reviewers and auditors something concrete to challenge.
The Confidence Trap
Do not tier risk by confidence alone. Confidence is a property of the system's belief about its output; risk is a property of the world if the output is wrong. They interact, but they are not the same.
A high-confidence answer to a low-stakes FAQ may be safe to auto-send. A high-confidence answer to a legal question may still need escalation because the domain risk is high. A low-confidence answer to an internal brainstorming prompt may not need review because the harm is low. A low-confidence payment action should stop.
Calibration matters here. The Cost of Being Confidently Wrong, another book in this canon, goes deeper on calibrated doubt, but the operating rule is straightforward: confidence should be treated as usable only after it has been measured. If a model says 0.9 and is correct 90% of the time on similar cases, the score can help route. If no calibration study exists, the score is a feature, not a fact.
Backlog Policy
Every review queue needs a backlog policy before it needs one. A queue under normal volume hides design flaws. A queue under spike volume reveals them. The backlog policy should answer:
| Condition | System behavior |
|---|---|
| Queue age exceeds SLA | Stop accepting new orange-tier actions or downgrade to manual workflow |
| Reviewer capacity drops below threshold | Increase auto-blocking for high-risk tiers |
| Sampling backlog grows | Preserve high-risk sampling; reduce low-risk sampling temporarily |
| Disagreement rate spikes | Pause affected workflow and recalibrate |
| Critical incident detected | Freeze model version and route to incident process |
The worst backlog policy is silent reviewer heroics. People work late, clear the queue, and hide the fact that the system is under-provisioned. The product appears healthy while the operating model is failing. Mature teams prefer visible degradation: slow the workflow, reduce autonomy, or disable a feature rather than pretending the loop is fine.
Designing for Reviewer Time
A reviewer's attention is the scarcest resource in the loop. Interface design should therefore reduce search time, context reconstruction, and unnecessary reading. The review screen should show why the item is in the queue, what decision is required, the recommended action, the evidence, the relevant policy, the allowed actions, and the deadline. It should not ask the reviewer to become a detective.
There is a measurable goal: reduce minutes per review without reducing quality. This is done through better evidence packets, clearer rubrics, pre-filled reason codes, keyboard shortcuts, grouped cases, and automated highlighting of conflict points. It is not done by rushing reviewers.
The Economics of Escalation
Escalation is expensive. A frontline reviewer may handle 100 cases per day. A legal specialist may handle 20. A physician may handle fewer. If the system escalates too many cases to the rarest expert, the expert becomes the bottleneck. Therefore, escalation thresholds must be designed with the capacity of the escalation role in mind.
A three-level model often works:
| Level | Reviewer | Purpose |
|---|---|---|
| L1 | Trained operations reviewer | Apply rubric to common risky cases |
| L2 | Domain specialist | Resolve policy ambiguity or high-value case |
| L3 | Accountable owner | Decide new policy, incident, or exception |
The goal is not to avoid L3. The goal is to reserve L3 for decisions that actually require accountable judgment. If L3 spends its time correcting obvious model mistakes, the loop design is broken.
Chapter Takeaway
Risk-tiered review makes human oversight economically possible. Without tiering and capacity math, human-in-the-loop becomes either unsafe automation or unscalable labor.
Sensitivity Analysis
Capacity models should be stress-tested. The average case is not enough. Review time varies by complexity. Volume spikes. Reviewer availability changes. A model upgrade can increase orange-tier routing. A new regulation can make previously green cases orange. Sensitivity analysis shows which assumptions can break the loop.
| Assumption change | Effect |
|---|---|
| Minutes per review rises from 2 to 4 | Reviewer need doubles |
| Orange tier grows from 5% to 12% | Approval queue more than doubles |
| Reviewer focus time drops from 5h to 3h | Staffing need rises 67% |
| Launch doubles daily volume | Queue may collapse unless review rate falls |
| New policy increases escalation rate | Specialist bottleneck appears |
The model should be recalculated whenever workflow volume, risk tiering, or review time changes. This should be part of release planning, not a quarterly finance surprise.
The Review Load Budget
A useful artifact is the review load budget. Each workflow gets a budget: maximum daily review hours, maximum queue age, maximum escalation volume, and maximum reviewer fatigue threshold. Product teams can spend the budget by increasing volume, increasing risk, or increasing review complexity. If they exceed it, they must reduce autonomy, improve automation, hire capacity, or change scope.
This budget changes product conversations. Instead of asking whether a human is in the loop, the team asks whether the loop has budget. A new feature that generates 5,000 more daily AI outputs must show how many enter review. A prompt change that increases uncertainty must show whether it changes tier distribution. A new enterprise customer workflow must show specialist review capacity.
Using Automation to Protect Human Judgment
Automation should not merely generate work. It should protect reviewers from unnecessary work. Good automation can pre-check policy source freshness, detect missing citations, group similar cases, pre-highlight contradictions, deduplicate repeated issues, and block obviously prohibited cases before they reach human review. This reduces review volume and improves quality.
The important boundary: automation can triage, but it should not silently erase uncertainty. If a case is removed from review because a heuristic says it is safe, that heuristic must itself be monitored. If a case is blocked before review, there should be an appeal or audit path where appropriate. Automation should make the human loop sharper, not invisible.
Review Cost and Product Margin
Human review cost belongs in the unit economics of the AI feature. If a feature saves ten minutes of agent work but adds eight minutes of review, the net gain is much smaller than the demo suggests. If review requires expensive experts, the feature may lose money even when the model cost is low. If review latency reduces conversion or satisfaction, the indirect cost may dominate.
Therefore, every AI business case should include review cost:
net_savings =
avoided_manual_work
- model_cost
- review_cost
- escalation_cost
- quality_failure_costThis equation is crude but useful. It keeps the team honest. A human loop is not free simply because the humans already work at the company. Their attention has opportunity cost.
Peak Design, Not Average Design
Review systems often fail at peaks. Average daily volume may look manageable, while peak hour volume creates unacceptable queue age. A product launch, outage, fraud attack, seasonal demand spike, or regulatory deadline can concentrate cases. Therefore, capacity should be modeled at daily and hourly levels.
If 40% of daily volume arrives in a two-hour window, a team sized only for average daily workload will miss the user-visible deadline. The solution may be staffing overlap, async queues, tier-specific SLAs, automatic autonomy reduction, or precomputed evidence packets. The important point is that review capacity has traffic shape, just like software infrastructure.
Reviewer Skill Mix
The number of reviewers is not enough. Skill mix matters. Ten general reviewers cannot replace one domain expert for a legal ambiguity. A queue that requires specialist review must model specialist capacity separately. Otherwise the team discovers too late that L1 review is idle while L2 is drowning.
A capacity model should therefore include lanes: general review, specialist review, security review, legal review, medical review, manager approval. Each lane has different throughput and SLA. Risk tiering should route cases to the cheapest competent reviewer, not the nearest available person.
Queue Simulations
For high-volume systems, teams should simulate queues before launch. A simple spreadsheet or script can model arrivals, review times, staffing, and priority rules. The goal is not perfect prediction. The goal is to see whether the queue explodes under plausible peaks. If a small change in orange-tier rate causes backlog to grow for days, the workflow is fragile. Simulations also make tradeoffs explicit: adding reviewers, improving evidence packets, narrowing autonomy, or changing SLAs each has a measurable effect. This is the review equivalent of load testing.
The Decision Cost of Delay
Capacity math should include the cost of delay. Some decisions lose value while they wait. A sales quote delayed by a day may lose a buyer. A fraud review delayed by an hour may trap a legitimate customer. A support answer delayed overnight may turn a simple issue into churn risk. Queue age is therefore not only an operations metric; it is a business metric. Risk-tiered review should optimize for safe action, not maximum caution. A system that prevents every error by delaying every decision has merely moved harm from quality into latency.