Sampling, Evals, and Continuous Learning
If approval loops prevent known high-risk failures, sampling loops detect unknown failures. A system that reviews only the cases it already knows are risky will miss the failures it has not yet learned to name.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. If approval loops prevent known high-risk failures, sampling loops detect unknown failures. A system that reviews only the cases it already knows are risky will miss the failures it has not yet learned to name. Sampling is how an AI system keeps discovering its own blind spots.
This chapter connects human review to evaluation. The loop should not end when a reviewer approves or rejects an item. Review data should become eval cases, regression tests, monitoring signals, policy changes, and sometimes training data. Otherwise the organization pays for human judgment once and forgets it.
Key Takeaways
- Sampling, Evals, and Continuous Learning names the operating decision a team has to make before it accepts the work.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with Human in the Loop Is Not a Plan and the adjacent chapters when you need the wider Evals and Evaluation frame.
Why Review Data Is Not Automatically Learning Data
Review data is messy. It is biased toward routed cases. It reflects the rubric and interface at the time. It may contain reviewer disagreement. It may include corrected outputs but not the reasoning behind them. It may overrepresent high-risk cases and underrepresent silent low-risk failures. Treating raw review data as clean training data is a common mistake.
The first step is separating feedback uses:
| Feedback use | Required quality |
|---|---|
| Product debugging | Reason codes and examples are enough |
| Eval cases | Clear expected behavior and source evidence |
| Training data | Consistent labels, cleaned inputs, policy stability |
| Audit evidence | Immutable record and reviewer identity |
| Policy improvement | Root-cause tags and ambiguity notes |
A rejected output can be valuable even if it never enters training. It may become an eval case. It may reveal a missing source. It may show that the policy is unclear. Learning is broader than model tuning.
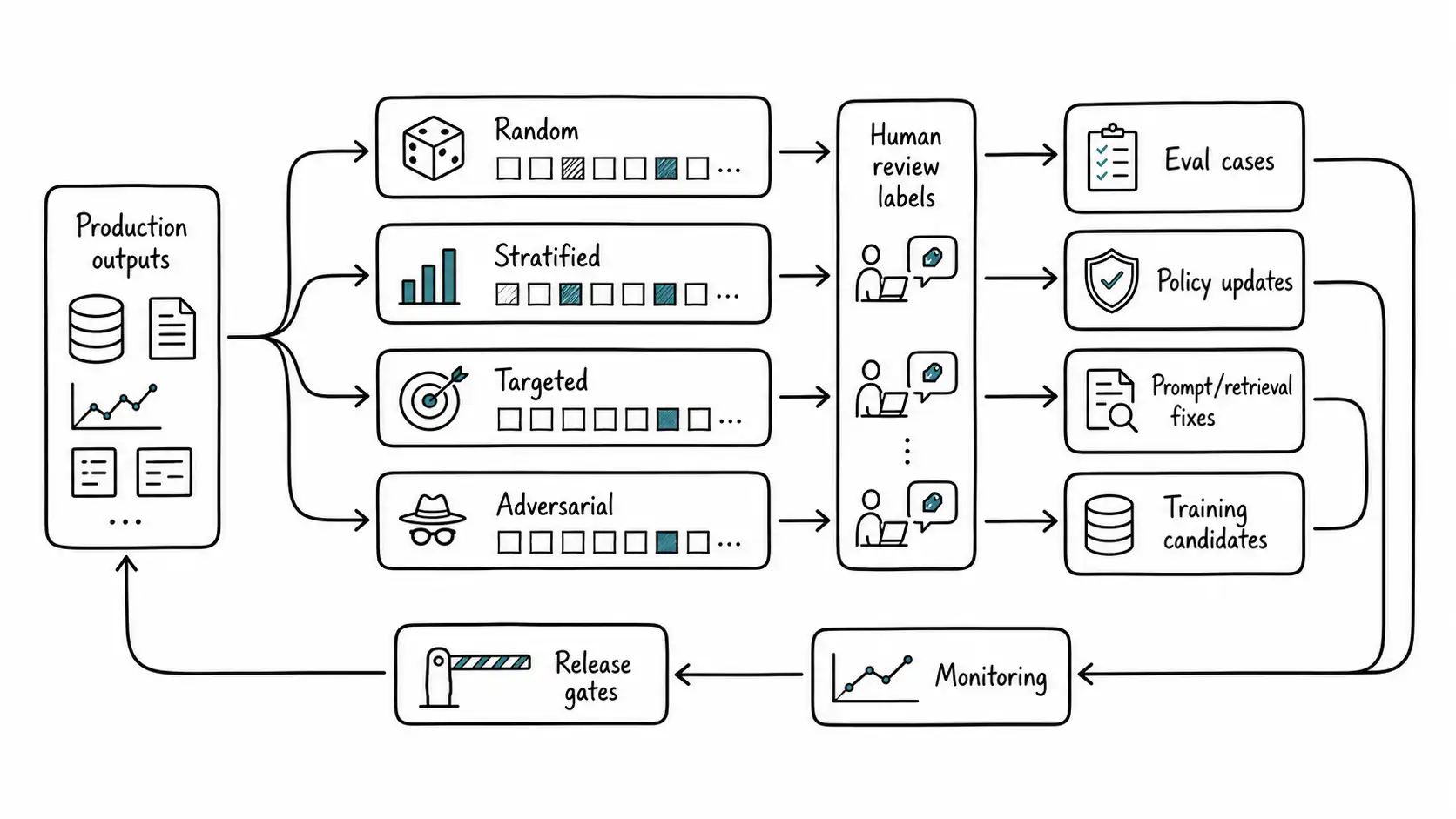
Sampling Strategies
There are four basic sampling strategies every AI-native team should understand.
Random sampling estimates baseline quality. Select a small percentage of all outputs uniformly and review them after action. This reveals how the overall system behaves, but rare failures may be missed.
Stratified sampling ensures coverage across slices: language, region, customer segment, workflow, model confidence band, risk tier, document type, product line. This is essential because aggregate quality can hide local failure. A support assistant may be excellent in English and weak in German. A code assistant may work well for backend changes and poorly for infrastructure code.
Targeted sampling focuses on known weak points: low confidence, new policy areas, recently changed prompts, new document collections, high-value customers, long inputs, tool-use failures, or outputs with missing citations. This is efficient but biased.
Adversarial sampling deliberately searches for failure: prompt injection attempts, contradictory context, edge cases, ambiguous requests, malicious users, and stress tests. This is not representative; it is protective.
A healthy sampling plan combines all four:
sampling_policy:
random_baseline:
rate: 0.02
applies_to: all_green_and_yellow_outputs
stratified:
dimensions: [language, customer_segment, workflow, confidence_band]
minimum_cases_per_week: 30
targeted:
triggers:
- prompt_version_changed
- retrieval_index_rebuilt
- confidence_below_0_75
- new_policy_document
rate: 0.25
adversarial:
cadence: weekly
source: red_team_case_libraryThe policy should be visible in the same way an SLO is visible. Sampling is not a back-office task. It is how the team knows whether autonomy is safe.
From Sampling to Evals
An eval is a repeatable measurement of behavior. A sample is an observation. The workflow is: sample cases, review them, identify failures, convert important failures into eval cases, and run those eval cases before future releases. This is how the system learns from production.
A good eval case includes input, context, expected behavior, unacceptable behavior, rubric, and source. For a RAG system, it may include expected documents. For an agent, it may include allowed and prohibited tool calls. For a code-generation system, it may include tests that must pass and contracts that must not change.
OpenAI's Evals framework, HELM, EleutherAI's language model evaluation harness, RAGAS, and DeepEval all represent the same general movement: explicit, repeatable evaluation replacing vibes. Sources: https://github.com/openai/evals, https://crfm.stanford.edu/helm/, https://github.com/EleutherAI/lm-evaluation-harness, https://docs.ragas.io/en/stable/, https://deepeval.com/docs/introduction The tools differ by task, but the discipline is shared. Do not decide from demos. Measure the behavior that would break in production.
Eval Drift
Evals drift too. A test set that was representative last quarter may become stale after product changes, policy changes, user behavior changes, or model upgrades. Human review data is one way to refresh evals. If reviewers repeatedly see a new kind of failure, the eval suite should absorb it.
Eval drift can be detected by comparing production review failures to eval failures. If production reveals many failures not covered by evals, the eval suite is stale. If evals fail often but production never sees those cases, the eval suite may be overweighting old risks. Neither condition means the eval suite is useless. It means the eval suite is a living artifact.
Labels, Reasons, and Root Causes
A review record should distinguish between outcome label, reason code, and root cause.
The outcome label says what the reviewer decided: approve, reject, edit, escalate. The reason code says why: unsupported claim, wrong policy, tone issue, missing citation, unsafe action. The root cause says what needs to change: retrieval gap, prompt issue, model limitation, stale policy, missing tool, product ambiguity, reviewer training.
Those three layers feed different owners. The ML or AI engineering team may own prompt and retrieval fixes. Product may own ambiguity. Policy may own rules. Operations may own reviewer training. Security may own unsafe tool calls. Without root cause, all failures become "model bad," which is too vague to improve.
Continuous Learning Without Reckless Training
Not every review correction should train the model. Some corrections reflect temporary policy. Some reflect a reviewer's mistake. Some reflect sensitive data. Some reflect edge cases that should be evals but not training examples. Some are valuable only as monitoring signals.
A safe feedback pipeline includes gates:
- Capture structured review.
- Remove or protect sensitive data.
- Resolve reviewer disagreement.
- Classify feedback use.
- Promote selected cases to evals.
- Promote selected cases to training or preference data only after quality review.
- Track which model or prompt versions consumed which feedback.
This is slower than dumping review logs into a fine-tuning job. It is also how teams avoid teaching the system inconsistent policy, private data, or reviewer mistakes.
Monitoring the Learning Loop
The loop itself should be monitored. Useful metrics include review volume, sampling coverage, rejection rate by tier, reason-code distribution, root-cause distribution, eval case promotion rate, time from detected failure to eval coverage, reviewer agreement, and post-release recurrence of known failures.
A particularly valuable metric is failure half-life: how long does it take for a newly discovered failure pattern to stop recurring? If reviewers keep flagging the same issue for months, the organization is not learning. It is paying humans to absorb a defect.
Chapter Takeaway
Sampling finds what approval misses. Human review becomes valuable at scale only when sampled cases turn into evals, policies, product fixes, and monitored learning loops.
Sampling Coverage Maps
A sampling plan should produce coverage maps. A coverage map shows which slices of production behavior have been reviewed recently. Without it, the team may believe it is sampling broadly while missing important slices.
Example coverage map:
| Slice | Weekly volume | Sampled | Reviewed failure rate | Coverage status |
|---|---|---|---|---|
| English support replies | 42,000 | 840 | 1.8% | Healthy |
| German support replies | 3,100 | 12 | 8.3% | Under-sampled |
| Enterprise refunds | 900 | 180 | 6.1% | Healthy |
| New policy docs | 2,400 | 30 | 10.0% | Needs targeted review |
| Low-confidence cases | 1,700 | 425 | 14.4% | Healthy |
The purpose is not only measurement. It is directing attention. German replies in the table have low sample count and high observed failure. That slice needs more review, better evals, or perhaps reduced autonomy until quality improves.
Eval Promotion Policy
Not every sampled failure should become an eval. Eval suites can become bloated. The promotion policy should prefer failures that are severe, recurring, representative, previously unseen, or tied to a known risk. A one-off typo may not deserve a permanent eval. A missing citation on a policy answer probably does. A cross-tenant data leak absolutely does.
Promotion policy:
| Failure type | Promote to eval? |
|---|---|
| Severe safety or privacy failure | Always |
| Historical regression | Always |
| Recurring reason code | Usually |
| Ambiguous policy | After policy clarification |
| One-off style issue | Usually no |
| Reviewer error | No, but use for training |
Each eval case should have an owner and a retirement rule. Old evals can become stale when product behavior changes. The eval suite should grow from production but not become an uncurated dump of everything that ever went wrong.
Learning Loop Latency
Measure how long it takes for review insights to change the system. This is learning-loop latency. If reviewers flag unsupported claims today and the eval suite catches that failure next week, the loop is working. If the same issue remains unresolved for six months, review is not compounding.
Useful targets might be:
| Event | Target |
|---|---|
| Severe failure discovered | Eval case within 48 hours |
| Recurring reason code detected | Root-cause owner assigned within one week |
| New policy ambiguity | Policy decision within two weeks |
| Prompt-related defect | Fix or rollback within one release cycle |
| Retrieval-related defect | Source/index fix scheduled within sprint |
The exact numbers depend on domain. The principle does not. A loop that learns slowly will be overwhelmed by systems that generate failures quickly.
Sampling the Auto-Approved Cases
The most important cases to sample are often the ones the system thought were safe. Escalated cases are visible by definition. Auto-approved cases are where silent failure lives. A system that never samples green-tier output cannot know whether green still means safe.
This matters after model upgrades, prompt changes, retrieval index rebuilds, policy changes, and traffic shifts. A green-tier policy based on last month's behavior may become stale. Sampling protects the team from assuming that yesterday's routing remains valid.
Human Review as Label Infrastructure
When review feedback is structured well, the organization gains label infrastructure. It can answer which failure modes are increasing, which model versions produce more unsupported claims, which customer segments trigger ambiguity, and which reviewers need calibration. This is more valuable than isolated corrections.
But label infrastructure needs data quality discipline. Reason codes should be controlled vocabulary. Reviewers should not invent new labels casually. Ambiguous cases should have resolution. Sensitive fields should be protected. Records should link to source versions. Otherwise the feedback lake becomes another pile of untrusted data.
The Sampling Budget
Sampling also has a budget. Review too little and silent failures go undetected. Review too much and the organization spends judgment where it adds little. The sampling budget should be allocated by risk and uncertainty, not evenly. A mature system might sample 1% of stable green cases, 10% of yellow cases, 25% of newly changed prompt paths, and 100% of a short-term incident slice. The budget should move. When evidence is weak, sample more. When evidence is strong and stable, sample less. This is how the organization learns efficiently.
Negative Sampling and Near Misses
Near misses deserve sampling attention. A reviewer may approve an output but note that it almost failed because the source was barely sufficient or the tone nearly overpromised. These near misses are early warnings. They should be captured separately from hard failures. Negative sampling can also include intentionally difficult cases that the system should reject, such as unsafe requests or missing-source scenarios. This teaches the evaluation suite to value correct refusal, not only successful completion. In autonomous systems, the ability to stop is often more important than the ability to proceed.