Autonomy Boundaries and Evaluation Strength
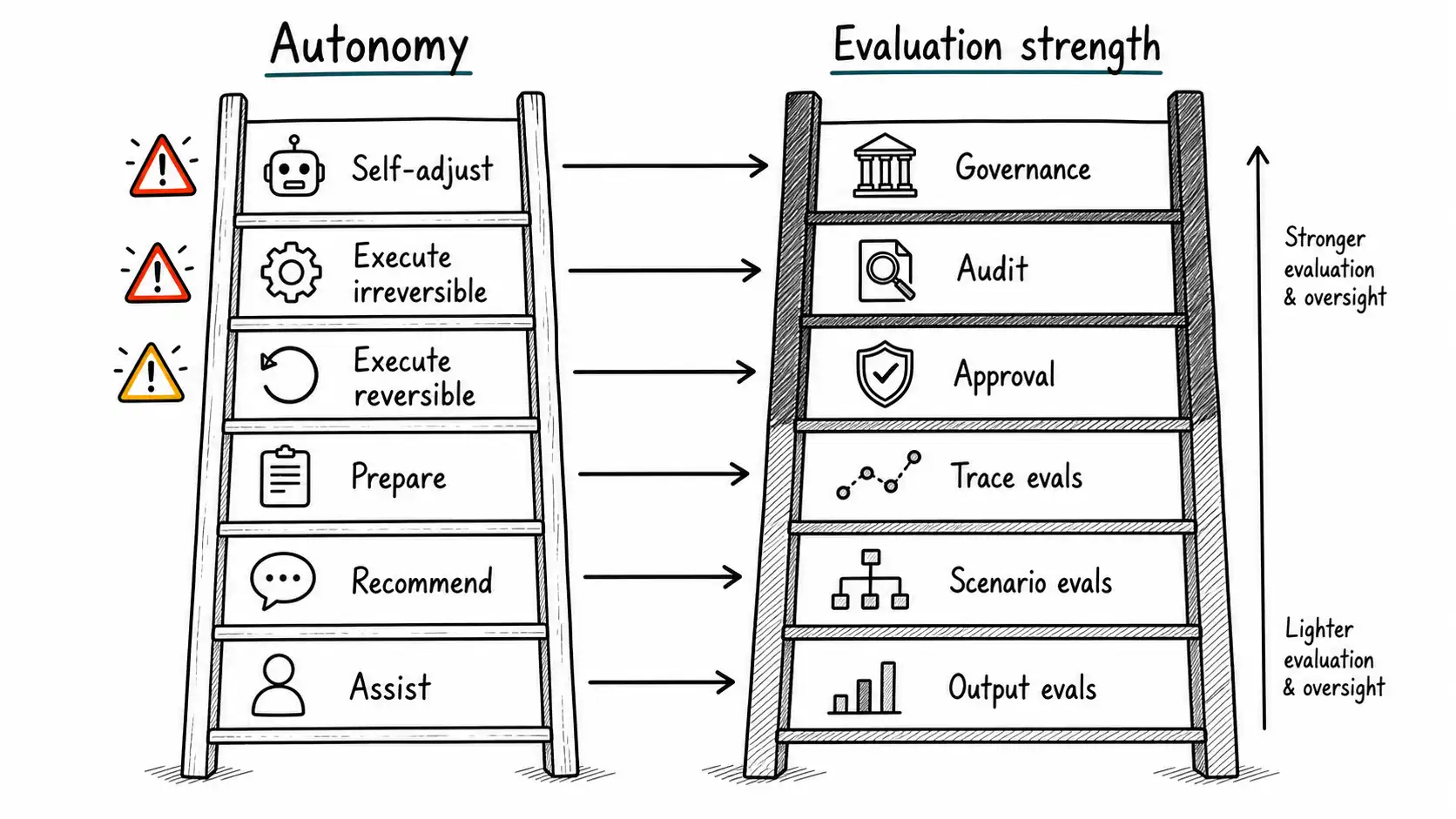
The more autonomy a system has, the stronger its evaluation must be.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The more autonomy a system has, the stronger its evaluation must be. This sounds obvious until a team ships an agent that can change state, call tools, message customers, or create tickets using the same evaluation discipline they used for a text-generation demo.
Autonomy changes the risk surface. A summarizer can be wrong. An agent can be wrong and act. A recommender can show a bad item. A workflow agent can trigger side effects across systems. A coding assistant can generate a vulnerable change. A finance assistant can produce a number that someone relies on. The question is not whether humans are in the loop. The question is what autonomy is allowed before, during, and after evaluation.
Anthropic's practical writing on building effective agents emphasizes that many successful systems are structured workflows rather than unconstrained autonomous loops, and that agents should be used where the task warrants the complexity. Source: https://www.anthropic.com/engineering/building-effective-agents This fits the argument here: autonomy must earn its keep, and evaluation must match the autonomy granted.
Key Takeaways
- The more autonomy a system has, the stronger its evaluation must be.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with Human in the Loop Is Not a Plan and the adjacent chapters when you need the wider Evals and Evaluation frame.
The Autonomy Ladder
A useful ladder:
| Level | System behavior | Evaluation requirement |
|---|---|---|
| Assist | Drafts or suggests; human acts | Output quality evals and reviewer rubric |
| Recommend | Ranks options; human selects | Ranking evals, slice analysis, decision audit |
| Prepare | Completes work but does not execute | End-to-end scenario evals and approval loop |
| Execute reversible | Acts but can undo | Pre-release evals, monitoring, rollback tests, sampling |
| Execute irreversible | Acts with hard-to-reverse consequences | Strong pre-action review, audit, red-team, policy signoff |
| Self-adjust | Changes its own instructions/tools | Change-control evals, governance, strict boundaries |
Most teams should live lower on the ladder than their demos suggest. A demo that shows an agent handling a whole workflow may be exciting, but the production version may sensibly prepare the workflow and ask a human to execute. That is not failure. It is matching autonomy to evidence.
Evaluation Strength
Evaluation strength has several dimensions:
- Coverage. Does the eval suite include common cases, edge cases, high-risk cases, and adversarial cases?
- Realism. Do cases resemble production inputs and tool states?
- Outcome validity. Are expected answers or actions defensible?
- Slice visibility. Can failures be seen by segment, language, workflow, or risk tier?
- Regression power. Would the suite catch known historical failures?
- Operational linkage. Are eval results tied to release gates?
- Human calibration. Are labels and rubrics stable enough to trust?
- Side-effect simulation. For agents, are tool calls and state changes tested safely?
A stronger eval is not simply bigger. A thousand easy cases do not protect a high-risk workflow. The eval must match the failure modes.
HELM's benchmark philosophy is useful because it pushes toward broad, transparent evaluation across scenarios and metrics rather than single-score claims. Source: https://crfm.stanford.edu/helm/latest/ RAGAS is useful for retrieval and generation pipelines because it separates dimensions such as faithfulness and context relevance. Source: https://arxiv.org/abs/2309.15217 The principle applies beyond those tools: evaluate the pieces that can fail, not only the final output.
Permissioned Autonomy
Autonomy should be permissioned. The system should have a policy that says which actions it may take, under what conditions, with which tools, on whose behalf, and with what review. This policy should be machine-readable enough to enforce.
agent_autonomy_policy:
workflow: enterprise_support_agent
allowed_without_review:
- create_internal_summary
- draft_customer_reply
- tag_ticket
allowed_with_review:
- send_customer_reply
- offer_service_credit_below_100
- close_ticket_as_resolved
prohibited:
- change_contract_terms
- issue_refund_above_500
- disclose_cross_tenant_information
required_evidence:
send_customer_reply:
- cited_policy_document
- customer_issue_summary
- confidence_above_0_85
offer_service_credit_below_100:
- account_standing
- credit_policy
- manager_override_if_repeat_customerThis is where human loops and evals connect. The autonomy policy determines which actions require review. The eval suite tests whether the system follows the policy. Monitoring checks whether production behavior matches it. Audit logs preserve evidence.
Tool Use and Side Effects
Tool use is the boundary where language output becomes operational action. A model drafting "I will refund the customer" is one thing. A model calling issue_refund(customer_id, amount) is another. The evaluation system must inspect tool selection, parameters, ordering, retries, and side effects.
Common tool-use failures include calling the right tool with the wrong parameter, calling tools in the wrong order, retrying non-idempotent actions, failing to check permissions before mutation, using stale retrieved data, and continuing after an error that should stop the workflow. These failures may not appear in final answer evaluation. The final answer may say "done" while the tool trace reveals the system did something unsafe.
Therefore, agent evals need trace evaluation. Did the agent call only allowed tools? Did it check preconditions? Did it stop when evidence was missing? Did it expose side effects to the reviewer? Did it preserve rollback data? Did it produce an audit record?
The Human Role at Each Autonomy Level
The human role changes as autonomy increases. At assist level, the human does the work and may use AI to draft. At prepare level, the human approves. At reversible execution level, the human monitors and handles exceptions. At irreversible execution level, the human sets policy, approves high-risk actions, and audits. At self-adjusting level, the human governs the system's ability to change itself.
This is why "human in the loop" is too vague. The human may be operator, approver, supervisor, auditor, trainer, policy owner, appeal authority, or incident commander. Each role requires different information.
Release Gates for Autonomy
Autonomy should be released gradually:
- Offline evaluation only.
- Shadow mode: system proposes actions but does not act.
- Human-confirmed mode: every action requires approval.
- Tiered mode: low-risk actions auto-execute, high-risk actions require approval.
- Monitored autonomy: sampling and monitoring replace approval for selected cases.
- Expanded autonomy only after evidence.
Each promotion should require evidence. Shadow mode should compare proposed actions to human actions. Human-confirmed mode should measure approval rate, correction rate, and reason codes. Tiered mode should monitor auto-action outcomes and sampled errors. Expanded autonomy should require stability across time, not one good day.
Exit Criteria
An autonomy boundary without exit criteria is a one-way door. The system should automatically reduce autonomy when quality drops, queue backlog exceeds limits, source freshness fails, tool errors spike, reviewer disagreement rises, or incident conditions are met. Reduced autonomy is not a failure. It is a safety valve.
Chapter Takeaway
Autonomy must be earned with evidence. The higher the system climbs from suggestion to action, the stronger its evals, permissions, review loops, monitoring, and exits must become.
Shadow Autonomy
Shadow autonomy is one of the safest ways to learn. The system proposes actions exactly as it would in production, but those actions are not executed. The team compares proposed actions to human actions, reviewer decisions, policy outcomes, and downstream results. Shadow mode reveals what autonomy would have done without exposing users to its full consequences.
Shadow mode is especially useful for agents. It can record tool plans, intended parameters, stopping behavior, and escalation decisions. Reviewers can inspect traces and classify errors. Engineers can convert failures into trace evals. Product can estimate how much work would be automated and how many cases would still need approval.
The common mistake is making shadow mode too short. One day of shadow traffic may not include rare cases. A useful shadow period covers enough volume, slices, and time variation to see representative behavior. It should include peak periods, new data, known edge cases, and adversarial tests.
Autonomy Should Be Narrow
Many AI failures come from granting broad autonomy when narrow autonomy would have created most of the value. An agent that can fully resolve every support ticket is risky. An agent that can gather evidence, draft a reply, and prepare three safe actions may deliver large savings with less risk. A code assistant that can rewrite an entire service is risky. One that can propose a small patch with tests under a spec gate is more manageable.
Narrow autonomy is not timid. It is how durable systems ship. The workflow should grant autonomy at the narrowest point where the machine creates clear value and evaluation can prove quality. Expand only after evidence.
Evaluating Non-Action
Autonomy evaluation should include cases where the correct behavior is not to act. Models and agents are often rewarded implicitly for completing tasks. But in production, refusing, escalating, or asking for more information may be the safest and most valuable action.
Eval sets should therefore include missing evidence, conflicting policy, unsafe requests, permission failures, ambiguous user intent, stale sources, tool errors, and irreversible actions without authorization. The expected behavior in these cases is stop, ask, escalate, or block. If the system is evaluated only on successful completions, it will learn the wrong lesson: action is always preferred.
Expanding Autonomy as a Governance Decision
Moving from approval mode to monitored autonomy should require governance review. The review does not need to be slow, but it should be explicit. What evidence supports expansion? Which failures remain? What monitoring will catch regression? What exit criteria reduce autonomy again? Who owns the risk?
This prevents autonomy creep. Without governance, teams gradually route more cases to auto-action because the system "seems fine." Then an incident reveals that no one formally accepted the new boundary. Autonomy should be a versioned product capability, not an accident.
Autonomy Boundary Tests
Before increasing autonomy, run boundary tests. These are cases designed to test whether the system stops at the right edge. Examples: a customer asks for a refund above the allowed amount; a user asks for another tenant's data; a tool returns an error after partial success; the required source is stale; two policies conflict; a request is phrased as urgent but lacks evidence; an agent is asked to perform an irreversible action.
A system that succeeds on normal cases but fails boundary tests is not ready for more autonomy. Boundary tests are the eval equivalent of guardrails on a bridge. They matter most where falling is expensive.
Autonomy Rollback
Autonomy needs rollback just like code. If sampled errors rise, if queue backlog spikes, if a model upgrade changes behavior, or if a new incident occurs, the system should move down the autonomy ladder. Auto-action can become approval-required. Approval-required can become manual-only. A tool can be disabled. A workflow can be narrowed to read-only mode.
Rollback should not require debate during an incident. The triggers and mechanisms should be defined before launch. The team should rehearse them. A rollback that exists only in someone's head is not a rollback.
Autonomy and Customer Trust
Some autonomy boundaries are not only technical. They are relational. Customers may accept an AI assistant drafting an answer but object to it making a decision about their contract. They may accept automatic summarization but expect human accountability for denial, pricing, or termination. Trust depends on expectation. A technically safe action can still damage trust if the customer expected a human decision. Therefore, autonomy policy should include user expectation and disclosure, not only internal risk. The system should know where automation is acceptable, where it must be disclosed, and where a human relationship still matters.
Evidence Before Expansion
A team should require a written autonomy expansion packet. It should include current tier distribution, eval results, sampled failure rates, approval and correction rates, incidents, reviewer disagreement, capacity impact, monitoring readiness, and rollback plan. This packet is not bureaucracy. It is the evidence that the machine has earned a larger boundary. Without it, autonomy expands by enthusiasm. With it, autonomy expands by proof. The difference becomes visible the first time the system encounters an edge case no demo included.