Human in the Loop Is an Incomplete Sentence
"Human in the loop" is an incomplete sentence.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. "Human in the loop" is an incomplete sentence.
A human in which loop? Reviewing what? Against which standard? With what authority? Before or after action? With what evidence? Under what time limit? Feeding which learning system? Escalating to whom? Accountable for what? Allowed to overrule what? Measured how?
Until those questions are answered, the phrase is not an operating model. It is a charm.
The phrase became popular because it solved a communication problem. Product teams wanted to move fast with AI but reassure buyers, executives, regulators, and internal risk teams that people remained involved. The phrase does that rhetorically. It suggests restraint. It implies supervision. It sounds more responsible than "the model decides." But rhetoric does not operate systems. Systems require specific loops.
Microsoft's Guidelines for Human-AI Interaction are useful here because they separate user control, feedback, uncertainty, and graceful failure into distinct design concerns rather than treating "human involvement" as one undifferentiated property. Source: https://www.microsoft.com/en-us/research/project/guidelines-for-human-ai-interaction/ The associated Human-AI Experience Toolkit similarly pushes teams to identify interaction failures, oversight points, and user expectations before launch. Source: https://www.microsoft.com/en-us/haxtoolkit/ai-guidelines/
The practical lesson is that human involvement must be designed at the same level of precision as model behavior. A loop should have a purpose, trigger, reviewer, evidence packet, action set, escalation path, audit record, and feedback destination.
Key Takeaways
- "Human in the loop" is an incomplete sentence.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with Human in the Loop Is Not a Plan and the adjacent chapters when you need the wider Evals and Evaluation frame.
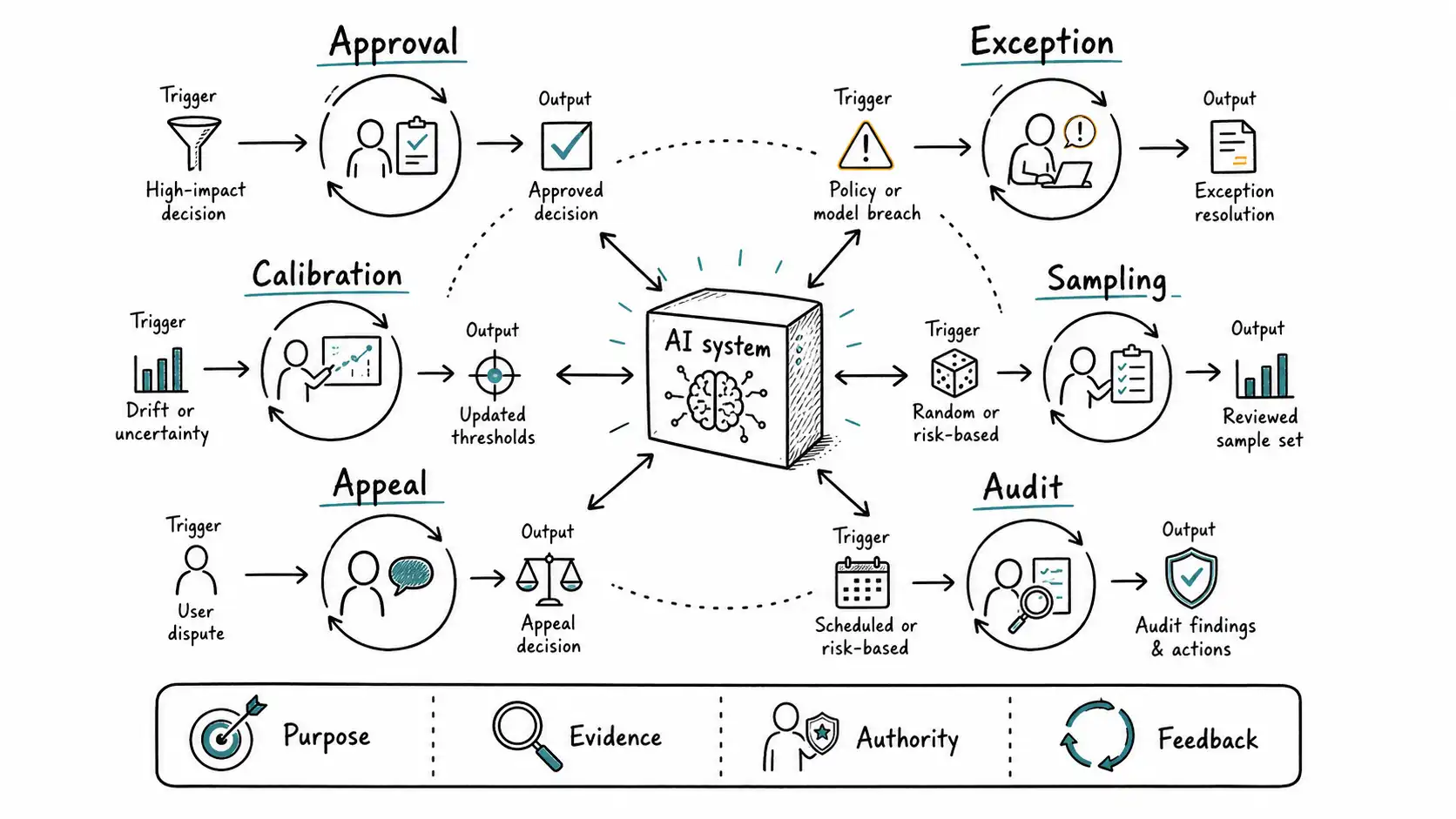
Six Kinds of Human Loops
The first step is naming which kind of loop you need.
| Loop type | Purpose | Human action | Common failure |
|---|---|---|---|
| Approval loop | Prevent risky action | Approve, reject, edit | Becomes bottleneck |
| Exception loop | Handle cases automation cannot | Resolve edge case | Receives only hard cases |
| Calibration loop | Keep labels and rubrics consistent | Compare judgments | Reviewers drift apart |
| Sampling loop | Detect hidden failures | Review sample | Sample is biased |
| Appeal loop | Correct bad outcomes | Reconsider decision | No authority to reverse |
| Audit loop | Preserve accountability | Inspect records | Evidence missing |
A support reply may need a sampling loop but not approval for low-risk answers. A bank transfer may need approval for certain thresholds and audit for all actions. A medical triage assistant may need exception routing plus strict audit. A code-generation system may need sampling of low-risk diffs and approval for security-sensitive changes. Different work, different loop.
The mistake is to put every workflow into the approval model because approval feels safest. Approval is expensive. It also changes human behavior. When reviewers approve thousands of machine suggestions, they tend to become acceptance machines unless the interface and incentives force real scrutiny. This is automation bias in operational clothing: the human begins to trust the system because the system is usually right, and then misses the rare case where review mattered.
Pre-Action and Post-Action Loops
The second distinction is timing. A pre-action loop stops the system before it acts. A post-action loop reviews what happened after the action. Pre-action loops reduce immediate risk but add latency. Post-action loops preserve speed but require reversibility.
A password reset email does not need human approval before sending if the action is reversible and low risk. A wire transfer does. A generated knowledge-base answer might be posted immediately if it is clearly cited and low stakes, then sampled afterward. A legal filing should not.
The decision depends on harm and reversibility:
| Action type | Example | Loop preference |
|---|---|---|
| Low harm, reversible | Drafting an internal summary | Post-action sampling |
| Low harm, irreversible | Sending minor customer email | Targeted sampling + guardrails |
| High harm, reversible | Temporarily suspending an account | Pre-action for uncertain cases |
| High harm, irreversible | Disbursing funds, clinical recommendation | Pre-action approval and audit |
This table is more useful than "human in the loop" because it links the loop to the risk shape. The system should be allowed to move faster where the cost of being wrong is low and the action can be undone. It should slow down where harm is high, irreversible, or hard to detect.
The Evidence Packet
A human reviewer without evidence is not a reviewer. They are a guesser with accountability.
Every loop needs an evidence packet. For an AI-generated support response, the packet might include the customer's question, the retrieved policy sources, confidence signals, similar historical cases, the model's draft, and the reason the item was routed to review. For an agent action, the packet should include the plan, tool calls, parameters, permissions, expected side effects, and rollback option. For a code change, it should include the spec, tests, generated diff, changed contracts, and risk classification.
The evidence packet is what makes review scalable. Without it, the reviewer must reconstruct context from several systems. With it, the reviewer can spend attention on judgment instead of navigation.
A useful packet format:
review_item:
workflow: enterprise_refund
action: approve_refund_offer
risk_tier: high
trigger_reason:
- amount_over_threshold
- policy_exception_detected
model_output: refund_offer_v3
evidence:
sources:
- refund_policy_2026_approved
- customer_contract_amendment_14
retrieved_at: "2026-03-12T14:10:22Z"
customer_history_refs:
- invoice_8842
- ticket_12931
reviewer_actions:
- approve
- reject
- request_more_information
- escalate_legal
audit_required: trueThis is not a theoretical artifact. It is the interface between automation and accountability. The reviewer should not need to ask why the item is in the queue. The system should say.
Authority and Accountability
A loop also needs authority. Many human review systems fail because reviewers can flag concerns but cannot act. They can mark an answer unsafe, but the product still sends it. They can reject an automated decision, but no one owns remediation. They can escalate, but the escalation path is a shared inbox.
Authority must match responsibility. If a reviewer is accountable for approving an action, they need the ability to reject it. If they can reject it, the system needs a path for what happens next. Does the workflow fall back to manual handling? Does the model try again? Does the case escalate? Does the customer wait? These are product decisions, not review-interface details.
Accountability must also be organizational, not personal theatre. A reviewer should not be blamed for missing a failure in a queue that gave them insufficient evidence, impossible volume, and no time. The system owner is accountable for loop design. Reviewers are accountable for applying the rubric inside a sane system.
Feedback Is Not Automatic
Teams often say human review will improve the model. It will not unless the feedback is captured, structured, labeled, and routed into an improvement process. A reviewer editing a draft response is not automatically creating training data. A reviewer rejecting an action is not automatically teaching the model the boundary. Feedback needs schema.
A minimum feedback record includes the original output, reviewer decision, corrected output if applicable, reason code, policy reference, severity, and whether the case should enter the eval set. Free-text comments are useful for nuance but weak as training data. Reason codes make the loop measurable.
{
"decision": "reject",
"reason_codes": ["unsupported_claim", "wrong_policy_version"],
"severity": "high",
"corrected_action": "escalate_to_policy_team",
"add_to_eval_set": true
}A loop that does not produce structured feedback is a cost center. A loop that produces high-quality labels, eval cases, and policy improvements is part of the product's learning system.
Chapter Takeaway
Human involvement only becomes a plan when the loop has a named purpose, timing, evidence packet, authority model, escalation path, and feedback schema.
The Reviewer Is Not the User
Many teams confuse user control with reviewer control. A product may let the end user edit an AI draft, but that does not mean it has a safety loop. The user may not know policy, compliance rules, data provenance, or hidden risks. In other cases, the reviewer is not the end user but an internal operator. The operator may understand policy but not the customer's intent. The distinction matters.
For example, a sales representative editing an AI-generated email is both user and reviewer. They know the customer relationship but may be incentivized to accept aggressive claims. A compliance analyst reviewing the same email understands risk but may not understand the deal context. A manager approving a discount understands margin but may not understand whether the generated explanation is misleading. No single human perspective covers all risks. Some workflows need multiple review types at different points.
The design question is therefore: whose judgment is needed? Domain expert, customer-facing operator, compliance owner, security reviewer, product owner, or end user? The phrase "human" hides that specialization. A loop staffed by the wrong human can create more confidence than safety.
The Loop Contract
A loop contract is a short artifact that defines how oversight works for a workflow. It should fit on one or two pages and answer the following:
| Field | Question |
|---|---|
| Decision | What decision or action is reviewed? |
| Purpose | Why does the loop exist? |
| Trigger | What sends an item into the loop? |
| Reviewer | Who reviews and what training do they need? |
| Evidence | What context must be shown? |
| Authority | What can the reviewer do? |
| SLA | How quickly must review happen? |
| Feedback | What data is captured from the review? |
| Escalation | What happens when the reviewer cannot decide? |
| Exit | When is the loop paused, reduced, or removed? |
This artifact sounds simple because it is. Its power is that it forces the team to be precise. "Human in the loop" becomes "enterprise refunds over $500 enter a pre-action approval loop reviewed by billing operations within one business hour using contract, invoice, policy, and model-reason evidence; reviewers may approve, reject, request information, or escalate to legal; decisions produce reason-coded feedback; the workflow pauses if queue age exceeds SLA for two consecutive hours." That is a plan.
Removing a Loop
A loop should not be permanent by default. Some loops are training wheels. Some are permanent controls. Some should expand when risk increases and shrink when evidence improves. A team should define removal criteria before launch: what approval rate, correction rate, sampled error rate, reviewer agreement, and incident history would justify moving a class of cases from pre-action review to post-action sampling?
This matters because review can become institutional inertia. Once a human loop exists, removing it may feel unsafe even when evidence shows it no longer adds value. The organization continues paying review cost because no one defined what success would look like. A loop without removal criteria is not a control. It is a habit.
For high-risk domains, removal may never be appropriate. But even then, the loop can be improved. The question is not always "remove review?" It may be "can better evidence reduce review time?" or "can low-risk subsets move to sampling?" or "can reviewer feedback eliminate recurring defects?" Scalable oversight is dynamic, not fixed.
Loop Removal as a Positive Milestone
Teams should celebrate removing unnecessary review when evidence supports it. This sounds counterintuitive because review is associated with safety. But an unnecessary loop consumes attention that could be spent on genuinely hard cases. If a class of green-tier cases has months of sampled quality, stable eval performance, low appeal rate, and clear reversibility, moving from high sampling to lower sampling may be the responsible choice.
The removal decision should be reversible. Reduce review gradually, continue monitoring, and define triggers that restore review automatically. This is similar to progressive delivery in software: autonomy ramps up, evidence is watched, and rollback remains available. Review removal is not trust in the model. It is trust in the measurement system.
The Sentence You Should Be Able to Say
Before launch, the team should be able to say the complete sentence aloud: "For this workflow, humans review these decisions, before these actions, when these triggers occur, using this evidence, under this SLA, with these allowed decisions, feeding these evals and owners, and reducing autonomy under these exit conditions." If the sentence cannot be completed, the loop is not designed. It may still be worth experimenting, but it should not be sold internally or externally as a safety plan.