The Operating System for Scalable Oversight
The final chapter assembles the book into an operating system. A team that wants scalable oversight needs more than a review queue, more than evals, and more than a policy document.

Research spine: this chapter stays grounded in NIST AI Risk Management Framework and NIST Secure Software Development Framework, then applies that evidence to the operating judgment in the book. The final chapter assembles the book into an operating system. A team that wants scalable oversight needs more than a review queue, more than evals, and more than a policy document. It needs a cadence of artifacts and decisions that keeps autonomy aligned with evidence as the product changes.
The operating system has seven parts: decision inventory, risk policy, evidence packets, evaluation suites, review operations, monitoring, and governance cadence. Each part has an owner. Each part produces artifacts. Each part is reviewed on a schedule. This is how human oversight stops being improvisation.
Key Takeaways
- The Operating System for Scalable Oversight names the operating decision a team has to make before it accepts the work.
- The practical test is whether a team can name the evidence, owner, and failure mode before it changes behavior.
- Read this with Human in the Loop Is Not a Plan and the adjacent chapters when you need the wider Evals and Evaluation frame.
Decision Inventory
The decision inventory lists the decisions AI systems make or influence. It should include workflow, decision, action consequence, risk tier, human role, eval coverage, monitoring signal, and owner. It is the map of where judgment lives.
| Workflow | AI decision | Consequence | Human role | Eval coverage |
|---|---|---|---|---|
| Support assistant | Select policy and draft reply | Customer receives answer | Approver for orange cases; sampler for green/yellow | Grounding, policy, tone |
| Billing agent | Recommend refund | Money and precedent | Approver above threshold | Scenario and policy evals |
| Code assistant | Modify service code | Production behavior changes | Reviewer accepts diff | Tests, contracts, security checks |
| Sales copilot | Recommend discount | Margin and customer expectation | Sales manager approves exceptions | Pricing-rule evals |
A decision inventory prevents hidden autonomy. It also helps executives understand what the system actually does. The most dangerous AI systems are often not the most technically advanced; they are the ones whose decision surface is poorly understood.
Risk Policy
The risk policy defines tiers, triggers, allowed autonomy, review requirements, and exit criteria. It should be written in plain language and, where possible, mirrored in machine-readable configuration. The policy should not be owned solely by engineering. Product, risk, legal, security, operations, and domain owners should participate.
NIST's AI Risk Management Framework is useful as a high-level reference because it emphasizes mapping, measuring, managing, and governing AI risks rather than treating risk as a single pre-launch checklist. Source: https://www.nist.gov/itl/ai-risk-management-framework The operating system in this chapter is the product-team version of that discipline: map decisions, measure behavior, manage changes, govern evidence.
Evidence Packets
Evidence packets are generated for review, audit, incidents, and evals. They should be standardized enough for tooling and flexible enough for domain variation. A packet for a support answer differs from a packet for a code diff, but both answer the same question: what did the system know, what did it decide, why was this allowed, and who accepted it?
Evidence packet quality is one of the best predictors of reviewer efficiency. If reviewers constantly leave the interface to search for sources, the packet is weak. If auditors cannot reconstruct decisions, the packet is weak. If eval cases cannot be built from review records, the packet is weak.
Evaluation Suites
The evaluation suite is the machine-readable representation of what the team fears breaking. It should include regression cases from incidents, sampled production failures, adversarial cases, slice coverage, and task-specific quality checks. It should run before release and on a cadence against production-like data.
For RAG-style workflows, evals should separate retrieval quality, grounding, answer correctness, and citation quality. For agents, evals should include tool traces and side effects. For code generation, evals should include tests, contracts, static analysis, and security checks. For support workflows, evals should include policy correctness and resolution quality, not just language fluency.
Review Operations
Review operations include staffing, training, calibration, scheduling, queue design, escalation, reviewer tooling, quality checks, and fatigue management. This is operational labor. It deserves operational respect.
A weekly review-ops meeting might inspect:
| Metric | Question |
|---|---|
| Queue age | Are users waiting too long for safe action? |
| Review volume by tier | Is tiering working? |
| Rejection rate | Where is automation weak? |
| Reason-code distribution | What failure modes dominate? |
| Reviewer agreement | Is judgment aligned? |
| Escalation volume | Are specialists overloaded? |
| Sample coverage | Are we seeing the whole system? |
The meeting should produce changes: adjust tier thresholds, improve evidence packets, update rubrics, add eval cases, fix retrieval, change prompts, add policy text, or reduce autonomy. A meeting that only observes numbers is not an operating mechanism.
Monitoring and Incident Response
Oversight systems need monitoring. The review loop can fail, and when it does, the product may become unsafe even if the model is running normally. Monitor queue backlog, queue age, reviewer capacity, sampling coverage, quality scores, approval rate, rejection rate, reason-code spikes, tool errors, source freshness, and eval regressions.
Incidents should have playbooks. If the system sends unsupported claims, freeze the prompt version, increase review tier, inspect retrieval freshness, and add evals. If unauthorized data appears in evidence packets, block affected workflow, preserve logs, notify security, and audit access control. If review backlog exceeds threshold, reduce autonomy or pause affected actions. These responses should be written before the incident.
Governance Cadence
Governance should be periodic and evidence-based. Monthly: review quality metrics, incidents, and autonomy boundaries. Quarterly: review decision inventory, risk policy, eval coverage, sampling plan, and reviewer calibration. Annually or after major product changes: reassess whether the system's autonomy is still appropriate.
Governance should ask hard questions:
- Which decisions did AI make this quarter?
- Which ones caused harm, near misses, or appeals?
- Which failures were not covered by evals?
- Which human loops exceeded capacity?
- Which reviewer disagreements reflect unresolved policy?
- Which workflows should gain autonomy?
- Which should lose autonomy?
- Which artifacts are stale?
The answer to "which should lose autonomy?" is especially important. Mature teams reduce autonomy when evidence weakens. Immature teams only expand.
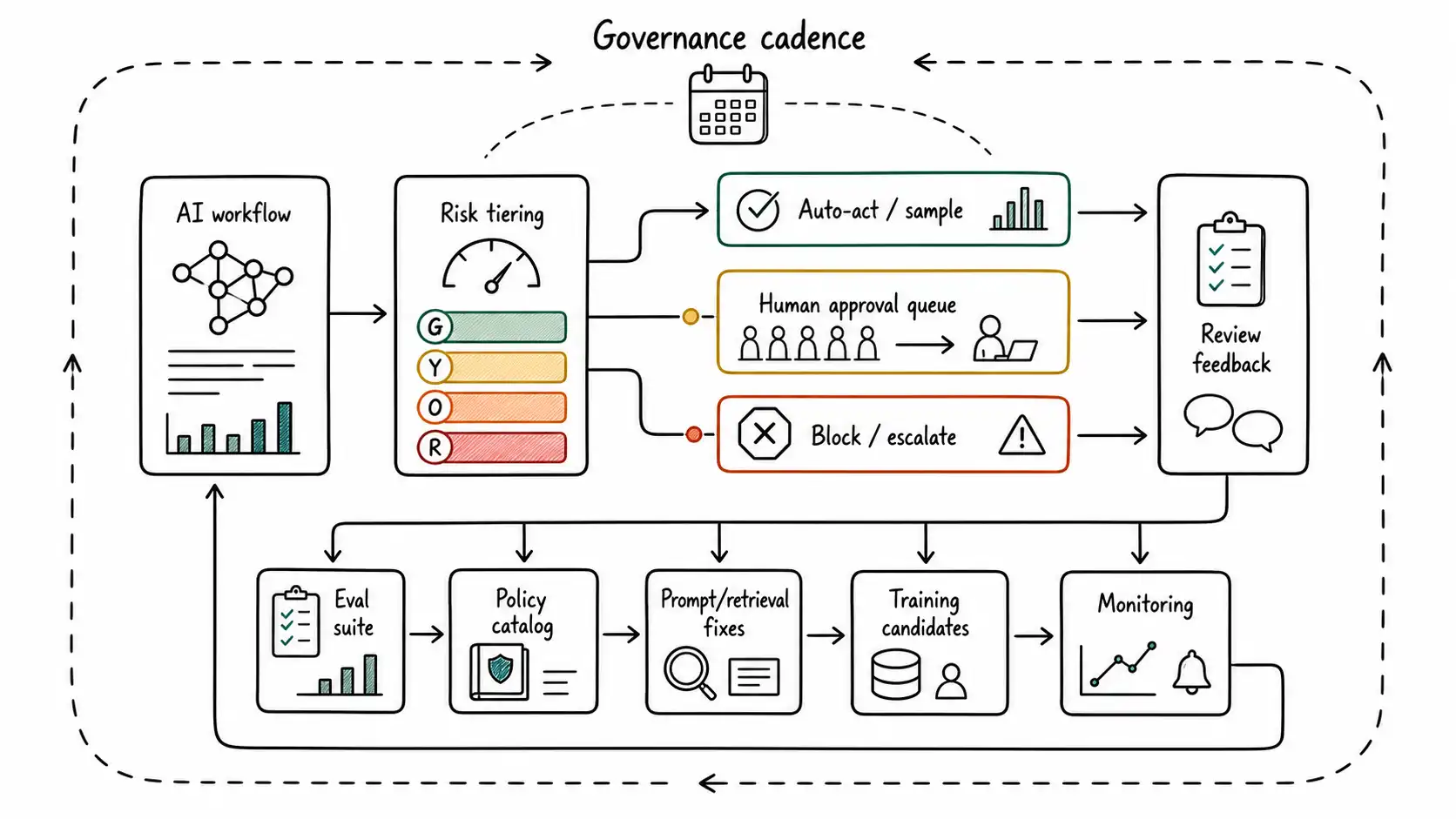
The Scalable Oversight Reference Architecture
A durable oversight system looks like this:
- AI workflow produces candidate output or action.
- Risk tiering classifies the case.
- Low-risk cases act with sampling and monitoring.
- Medium-risk cases may act with heavier sampling or targeted review.
- High-risk cases enter approval with evidence packets.
- Prohibited cases block and escalate.
- Reviews create structured feedback.
- Feedback becomes evals, policy updates, prompt/retrieval fixes, training candidates, and incidents.
- Evals gate future releases.
- Monitoring can reduce autonomy automatically.
This is the loop the title rejected. Not a human vaguely present somewhere. A system that knows when to use human judgment, how to preserve it, how to learn from it, and how to scale it.
Final Checklist Before Shipping
Before launching an autonomous or semi-autonomous AI workflow, answer:
| Area | Question |
|---|---|
| Decision | What exact decision is AI making or influencing? |
| Risk | What happens if the decision is wrong? |
| Autonomy | What can the system do without approval? |
| Evidence | What does a reviewer need to judge? |
| Capacity | Can the review queue handle expected and spike volume? |
| Sampling | How will silent failures be detected? |
| Rubric | What standard do reviewers apply? |
| Calibration | How do you know reviewers agree? |
| Feedback | Where do review outcomes go? |
| Evals | What must pass before release? |
| Monitoring | What detects loop failure? |
| Exit | What reduces autonomy when quality drops? |
| Audit | Can you reconstruct the decision later? |
This checklist is the practical answer to the book. Human-in-the-loop is not a plan. But a designed oversight system can be.
Final Takeaway
The goal is not to keep a human near every AI output. The goal is to spend human judgment where it changes outcomes, preserve that judgment as evidence, and let the system earn autonomy only where evaluation proves it is safe.
Ownership Model
Every part of the oversight operating system needs ownership. Engineering may own instrumentation, eval execution, and workflow controls. Product owns user-facing tradeoffs and autonomy boundaries. Operations owns reviewer staffing and training. Risk or compliance owns policy-sensitive controls. Security owns trust boundaries and abuse response. Domain experts own specialist judgment. A single accountable system owner coordinates the whole.
A RACI table helps, but the deeper requirement is incident accountability. When the loop fails, who leads? If review backlog causes customer harm, is that operations, product, or engineering? If a model action violates policy, who freezes autonomy? If reviewers disagree because policy is ambiguous, who decides? These should be known before failure.
Operating Cadence
A practical cadence:
| Cadence | Meeting or artifact | Purpose |
|---|---|---|
| Daily | Queue health check | Backlog, SLA, incidents, staffing |
| Weekly | Review quality review | Reason codes, sampling, disagreement |
| Biweekly | Eval update | Promote cases, inspect regressions |
| Monthly | Autonomy boundary review | Expand, reduce, or hold autonomy |
| Quarterly | Governance review | Decision inventory, risk policy, audit readiness |
This cadence should be lighter for low-risk systems and heavier for high-risk ones. The point is not meetings. The point is regular decisions. If no decision changes after three meetings, the cadence should be redesigned.
What Good Looks Like
A good oversight system has signs. Reviewers can explain the rubric. Product can explain why each autonomy boundary exists. Engineering can show eval results tied to releases. Operations can show queue health and staffing assumptions. Risk can inspect audit trails. Sampling reveals new failures before customers do. Incidents produce evals. Recurring reason codes decline. Autonomy expands slowly in areas where evidence is strong and contracts in areas where evidence weakens.
A bad system has different signs. Everyone says "human in the loop," but no one can describe capacity. Reviewers use private judgment. Evals are demos. Sampling is ad hoc. Review feedback disappears. The queue grows silently. Autonomy expands because nobody objects. Incidents blame the model instead of the system.
The difference is management discipline, not model capability. The same model can be dangerous in one operating system and useful in another.
The Last Human Question
The final question is not "where do we put the human?" The final question is "which human judgment is scarce enough to preserve?" If the judgment is simple, encode it. If it is repeated, learn from it. If it is ambiguous, clarify policy. If it is high-stakes, slow down. If it is rare and consequential, design escalation. If it is no longer needed, remove the loop. Human attention is too valuable to spend as a decorative checkbox.
That is the mature posture. The human is not a patch for model imperfection. The human is the source of accountable judgment, used deliberately, protected operationally, and converted into better systems over time.
The Executive Dashboard
Leadership should not see only model accuracy or adoption. They should see oversight health: autonomy by workflow, review capacity, queue age, sampled failure rate, high-severity failures, eval pass rate, reviewer agreement, escalation volume, and autonomy changes this period. These metrics tell whether the organization is gaining safe use or merely hiding labor behind an AI interface.
The dashboard should also show decisions, not just numbers. Which workflow gained autonomy this month? Which lost autonomy? Which loop was removed? Which recurring failure was eliminated? Which policy ambiguity remains unresolved? Oversight is a management system; management needs decision visibility.
The Final Operating Principle
Spend human judgment where it is rare, consequential, and learnable. Do not spend it repeatedly on defects the system can fix. Do not spend it on low-risk cases merely to feel safe. Do not remove it from high-stakes decisions because the model is fluent. Treat judgment as precious production capacity, and build the system around preserving it.
The Durable Outcome
When this operating system works, human review volume does not simply grow with AI usage. Some review grows because the product does more. Some review shrinks because the system learns. The important pattern is that human judgment compounds. A reviewer's correction becomes an eval. A disagreement becomes a clearer policy. An incident becomes a boundary test. A backlog becomes a tiering change. The organization becomes better at deciding where the machine may act and where it must stop.