Packaging Copilots, Agents, and Automations
How much human is in the loop should decide the pricing model, because it decides both the value and who bears the risk.

Research spine
This chapter is grounded in OpenAI API pricing, Anthropic prompt caching documentation, and Stanford HAI, 2025 AI Index Report.
Pricing software that thinks starts by pricing units of resolved work against variable inference, review, and risk cost.
A product leader showed me three AI features his company had shipped under one banner. A writing assistant that suggested phrasing as you typed. An agent that drafted and sent follow-up emails after a meeting. And an automation that processed the entire overnight queue of inbound support tickets without anyone watching. He wanted to price all three the same way, because they were all "AI," and the marketing team wanted one story. That instinct, one pricing model for everything labeled AI, is how you end up overcharging for the assistant and giving away the automation.
These three things are not the same product wearing different masks. They differ on the one axis that should drive AI pricing more than any other: how much human is in the loop. And because that axis governs both the value created and the risk borne, it should govern the pricing model too. This chapter is about reading that axis and pricing each band correctly.
The human-in-the-loop spectrum
Lay out AI features by how much human presence and judgment each requires, and three bands emerge.
Copilots assist a human who stays fully in the loop. The human is present, doing the work, and the AI makes them faster or better: autocomplete in the editor, suggested replies, a "summarize this" button. The human reviews and accepts every output. Value comes from making a present human more productive. The human is the safety net, so the vendor's risk is low.
Agents do a task on a human's behalf, with the human supervising rather than performing. The human delegates a unit of work, the agent does it, the human reviews the result before it counts: an agent that drafts the email for approval, that proposes the redlines for a lawyer to accept, that prepares the reconciliation for a controller to sign off. Value comes from work performed, not just assistance. The human is still a checkpoint, but they are no longer doing the work, so the vendor's risk is higher.
Automations do the work end to end, often with no human present: the overnight ticket queue resolved while the team sleeps, documents processed and filed automatically, transactions reconciled and posted without review. Value comes entirely from work performed in the human's absence. There is no human safety net in the moment, so the vendor bears the most risk and creates the most distinct value.
This is the spectrum the seat-pricing motif was pointing at all along: copilots price presence reasonably well because a human really is present, while automations create value precisely when no one is present, which is where seats become absurd.
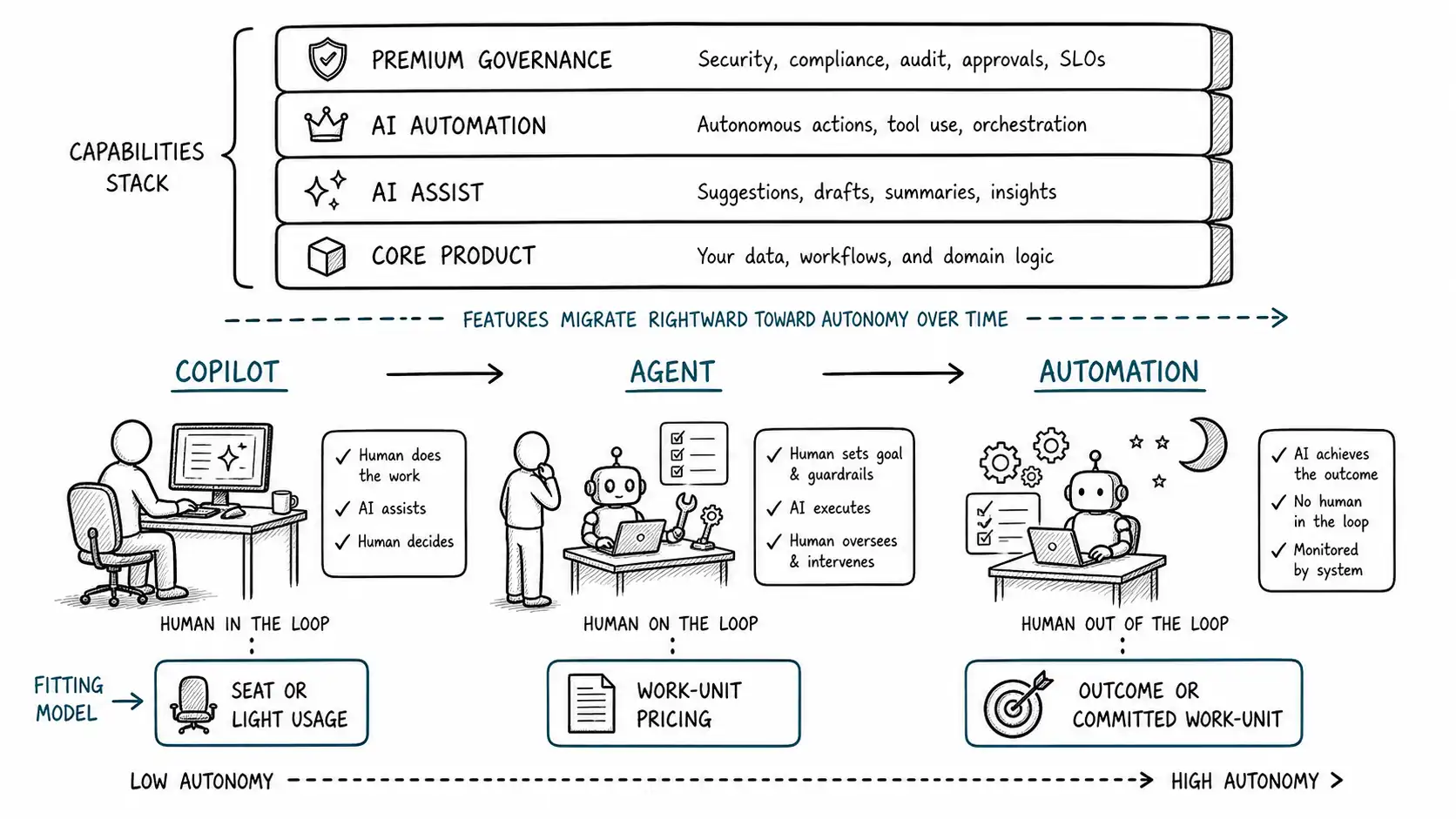
Why the band should pick the model
The band is not a marketing category. It maps almost directly onto which pricing model fits, through the Value-Cost-Risk Triangle.
Copilots: lean toward seat or light usage, because the human is the unit of value. With a copilot, value really does scale roughly with the number of humans being assisted, because each human is present and doing work the copilot accelerates. The old seat logic partially holds again: more assisted humans, more value. The cost is also bounded, because a human can only accept so many suggestions per day; usage is naturally throttled by human attention. So copilots are the one band where a seat-based or seat-plus-light-usage model is defensible, often as a per-seat add-on to an existing subscription. The cost stack is real but capped by human throughput, and the risk is low because the human reviews everything. Just keep a quota or soft cap on the usage component, because a power user can still run a copilot far harder than the average, and you do not want the heavy-user margin problem creeping back in.
Agents: lean toward work-unit pricing, because work is performed but checked. With an agent, the value is the work done (the drafted email, the proposed redline, the prepared reconciliation), so the work unit is the natural price. The human checkpoint reduces but does not eliminate the verification problem from the outcome chapter: you can price per task performed without having to prove the final outcome, because the human is the one who accepts the outcome. This is the sweet spot for the Work Unit Model. Price per task the agent completes, tier it for complexity, and you have a model aligned with value, connected to cost, and predictable for the buyer. The human-in-the-loop also caps your risk: if the agent does the work badly, the human catches it before it counts, so you are less exposed than pure outcome pricing would be.
Automations: lean toward outcome or committed work-unit pricing, because value and risk are highest. With an automation, there is no human in the moment, so the value is purely the work performed and the outcome achieved, and the risk is entirely yours. This is where outcome pricing earns its keep: the automation resolved the ticket or it did not, processed the document or it did not, and because the AI did the whole thing, attribution is clean. It is also where you must load the cost risk into the price, per the outcome chapter, because there is no human absorbing failures. Automations often justify the highest prices because they create value no number of seats could (work done while everyone is asleep) but they also demand the most disciplined cost modeling, because every failure is yours to eat.
Here is the spectrum as a packaging map:
| Band | Human role | Value source | Cost risk | Fitting model |
|---|---|---|---|---|
| Copilot | Performs work, AI assists | Productivity of present human | Low (human reviews) | Seat or light usage add-on, with cap |
| Agent | Supervises, AI performs | Work performed, then checked | Medium | Work-unit pricing, tiered |
| Automation | Absent, AI does it all | Work performed in absence | High (vendor eats failures) | Outcome or committed work-unit |
The packaging architecture
Most real products are not one band; they span the spectrum, like the product leader's three features. The mistake is one model across all three. The fix is a packaging architecture that prices each band on its own terms while keeping the customer's experience coherent. A clean structure looks like this:
- Core product. The non-AI software, priced however it always was (often seats or a platform fee). This is the base the customer already understands.
- AI assist (copilots). Included in higher tiers or a per-seat add-on, with a usage cap so heavy users do not erode margin. Priced as a productivity enhancement to the seats.
- AI automation (agents and automations). Priced on work units or outcomes, metered and expandable, sitting on top of the core. This is where the consumption-style economics live, isolated from the predictable seat base.
- Premium governance and control. For enterprise: audit logs, guarantees, dedicated capacity, compliance features, priced as a platform premium. We treat this in the enterprise chapter.
The architecture lets the customer keep the predictability of seats for the core, opt into copilots as a per-head productivity boost, and pay for automation by the work it performs, all without one band's economics contaminating another's. It also lets you tell a coherent story: presence is priced by seats, work is priced by work units, outcomes are priced by outcomes, and the customer can see why each is different.
The trap: pricing the agent like the copilot
The single most common packaging error is pricing an agent or automation as if it were a copilot, usually by bundling it into a seat. It happens because the agent ships as a feature inside the existing seat-based product, so it inherits the seat pricing by default. Now you have an automation that does work in the customer's absence, priced as if its value scaled with present humans, which it does not. This is the included-AI-on-a-seat disaster from the first chapter, and it is most acute for automations, because automations have the highest cost and the weakest connection to seat count.
The reverse error also happens: pricing a copilot like an automation, slapping per-task or outcome pricing on a feature where the human is fully in the loop and the value is modest assistance. This overcharges, because the customer is paying work-unit prices for what is really a convenience, and it produces resistance, because the buyer correctly senses they are being metered for using a button. Copilots should feel like a productivity perk on the seat, not a meter that runs every time someone hits autocomplete.
The discipline is simple to state: read the band before you pick the model. How much human is in the loop? That answer should pick the model before any other consideration, because it determines both how much value the feature creates and who bears the risk if it fails.
Migration: the band changes over time
One subtlety that catches teams off guard: features migrate up the spectrum as the AI improves. A copilot that suggests replies becomes an agent that drafts them for approval becomes an automation that sends them. The capability ratchets toward autonomy, and when it does, the right pricing model changes with it. A feature you correctly priced as a seat add-on when it was a copilot becomes mispriced the moment it graduates to an automation, because now it is doing work in the customer's absence at a seat price.
This means packaging is not a one-time decision. You should re-run the band assessment whenever a feature's autonomy level changes materially, and be prepared to move it from the AI-assist layer to the AI-automation layer of your architecture when it crosses from supervised to autonomous. The migration chapter handles how to move customers across pricing models without breaking trust; here, just hold the principle: when the human leaves the loop, the pricing model should change, because the value and risk just changed.
Practical exercise
List every AI feature in your product. For each, write down one thing: where the human is. Performing the work (copilot), supervising it (agent), or absent (automation). Then check the pricing model against the band. Any feature where an automation is priced like a copilot is a margin leak you can quantify with the cost stack. Any feature where a copilot is priced like an automation is a churn risk and a competitiveness problem. Fix the mismatches before you touch anything else in packaging, because the band-to-model alignment is the foundation the rest of your packaging sits on.
Key Takeaways
- AI features fall into three bands by how much human is in the loop: copilots (human performs), agents (human supervises), automations (human absent).
- The band should pick the pricing model because it governs both value created and risk borne.
- Copilots fit seat or light-usage add-ons with a cap, because value scales with present humans and human attention throttles cost.
- Agents fit tiered work-unit pricing, the Work Unit Model sweet spot, because work is performed but the human checkpoint caps verification risk.
- Automations fit outcome or committed work-unit pricing, because value and risk are highest and attribution is cleanest when the AI does it end to end.
- Use a layered packaging architecture (core, AI assist, AI automation, premium governance) so each band's economics stay isolated; re-run the band assessment as features grow more autonomous.