The AI Cost Stack Nobody Puts on the Pricing Page
Token prices are the part of AI cost you can see; the full stack underneath them is what actually decides your margin.

Pricing software that thinks starts by pricing units of resolved work against variable inference, review, and risk cost.
When a team tells me their AI feature costs "about a penny per call," I ask them to walk me through the penny. Almost always, the penny is the input and output tokens for the main model call, read straight off the API pricing page. Almost always, that penny is wrong by a factor of two to five, because it counts one item out of a stack of twelve.
The gap between "the token cost" and "the cost" is where margins go to die. You cannot price work you do not understand the cost of, and you cannot understand the cost of AI work by reading one line off a pricing page. So this chapter is the full inventory: the AI Cost Stack, every layer of variable cost behind a single unit of AI work, most of which never appears on anyone's pricing page and several of which never appear on anyone's cost page either.
The whole stack
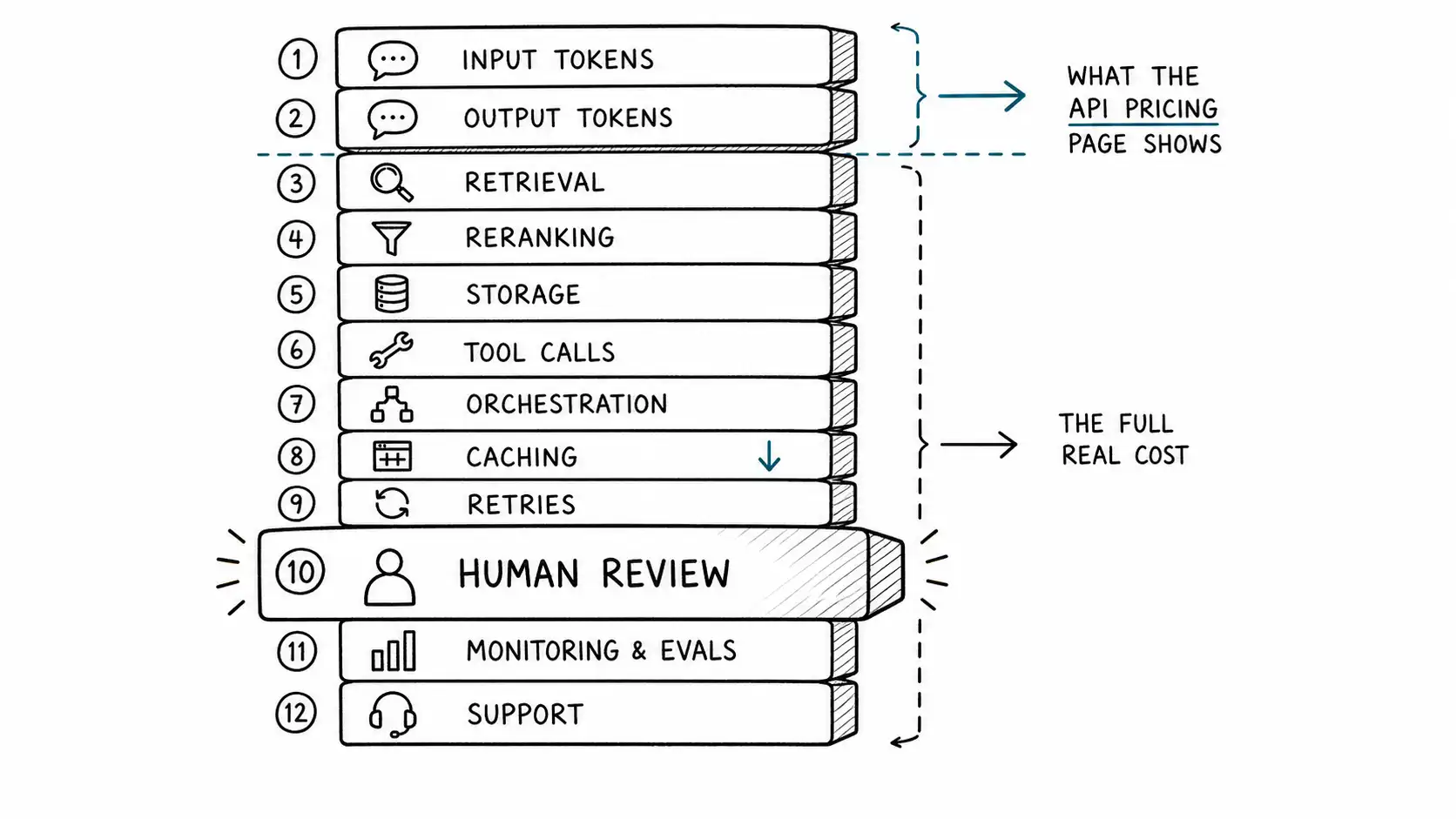
Here is the stack, top to bottom, from the moment a request arrives to the moment you have served a trustworthy result and kept serving it.
- Input tokens. The prompt: system instructions, user input, and crucially the retrieved context you stuff in. Long context is cheap to add and expensive at scale. As of mid-2026, GPT-4.1 input runs about $2 per million tokens and Claude Sonnet 4.6 about $3. A retrieval-heavy prompt with 30,000 tokens of context costs roughly six to nine cents in input alone before the model says a word.
- Output tokens. Usually the most expensive line, because output is priced three to five times higher than input: GPT-4.1 at $8 per million, Sonnet at $15, Opus at $25. A verbose 2,000-token answer on Opus costs five cents in output. Output length is the single biggest cost lever you control, and almost nobody manages it.
- Retrieval. Embedding the query, the vector search, and often the cost of having embedded and stored the corpus in the first place. Per call it is small; at corpus scale and high query volume it is real, and it grows with your data, not just your usage.
- Reranking. Many quality-sensitive systems retrieve broadly then rerank the top candidates with a second model or a cross-encoder. That is an extra model pass per query, often overlooked because it is "just reranking."
- Storage. Vector indexes, document stores, conversation history, caches. Mostly fixed and small per unit, but it scales with your customer base and their data retention, and it never goes to zero.
- Tool and function calls. When the agent calls a search API, a code interpreter, a database, or a third-party service, each call may carry its own metered cost. Agentic workflows can fan out into dozens of tool calls per task.
- Orchestration. The cost of the framework gluing it together: the planner model deciding what to do next, the controller making multiple model calls to complete one user-facing unit of work. An agent that "resolves one ticket" might make eight model calls under the hood. Your unit cost is the sum of all eight, not one.
- Caching. A cost reducer, not a cost, but it belongs in the stack because forgetting it inflates your estimate. Prompt caching cuts cached input cost by roughly 90 percent on the major APIs, per Anthropic's caching documentation. If a stable system prompt and retrieved context repeat across calls, caching turns a large input cost into a small one. Modeling cost without caching overstates it; assuming caching you have not implemented understates it.
- Retries. Models fail, time out, return malformed output, or get rejected by your own validation. Each retry is another full call. A 10 percent retry rate is a 10 percent cost increase on the retried step, and complex agentic flows retry more than you think.
- Human review. The line item that dwarfs all the others when it appears. When the model is uncertain, or the stakes are high, or compliance requires it, a human checks the output. A human minute costs vastly more than a model call. If even 5 percent of units route to a reviewer, the blended cost per unit can double, because you are now paying salary, not tokens.
- Monitoring and evals. Logging, tracing, and the ongoing cost of running evaluation suites to catch quality regressions. This is partly fixed and partly per-unit (you often sample-eval a fraction of production traffic). It is real engineering and compute cost that supports the product working at all.
- Support. When AI output is wrong or confusing, customers contact support. AI features generate their own support load, and that load is a variable cost that scales with usage and with error rate.
Notice how many of these are invisible if you only read the model API page. The page shows you items 1 and 2. The other ten are yours to find.
A worked unit cost
Abstraction does not move anyone, so here is a worked example. This is a hypothetical, labeled as such, but the proportions are representative of real RAG-plus-agent support systems I have costed. The work unit is "one resolved support ticket," and the agent makes multiple model calls plus tools to resolve it.
| Stack layer | Detail | Cost per ticket |
|---|---|---|
| Input tokens | 3 calls, ~12K tokens each, mixed models | $0.075 |
| Output tokens | 3 calls, ~800 tokens each | $0.060 |
| Retrieval | embed + vector search, 2 lookups | $0.004 |
| Reranking | cross-encoder over candidates | $0.006 |
| Tool calls | order-status API, refund API | $0.010 |
| Orchestration | planner model overhead | $0.020 |
| Caching | system prompt cached (saving) | -$0.030 |
| Retries | 12% retry rate on main call | $0.016 |
| Human review | 8% of tickets reviewed, $0.50 each | $0.040 |
| Monitoring/evals | sampled eval + tracing, amortized | $0.008 |
| Support | AI-driven contacts, amortized | $0.012 |
| Total | $0.221 |
The "penny per call" estimate would have read the input-plus-output line, seen about 13.5 cents, and maybe rounded to "a dime." The real cost is 22 cents, and the difference is entirely in the layers that do not appear on the API page. Human review alone, at 8 percent incidence, is bigger than retrieval, reranking, and tools combined. If you priced this resolution at thirty cents thinking your cost was a dime, you would have a 67 percent gross margin in your model and a 26 percent gross margin in reality.
This is exactly the dynamic ICONIQ measured when it reported AI-product margins at 52 percent, and that reporting on inference cost found roughly $230,000 of every million in AI revenue walks out as inference cost before any human is paid. The 52 percent is what you get when the full stack is real and the price was set against a partial view of it.
The two layers that surprise everyone
Two layers deserve special warning because they are the ones teams systematically underweight.
Human review is the margin killer in regulated or high-stakes work. In contract review, medical coding, financial reconciliation, and similar domains, you cannot ship unreviewed AI output, so a fraction of units carry a human cost that dominates the token cost by an order of magnitude. The temptation is to model the "happy path" where the AI handles it alone, and treat review as an edge case. It is not an edge case; it is a cost line, and it scales with your error rate and your risk posture. If your review rate is 20 percent and a review costs a dollar, your floor cost per unit is twenty cents in salary alone, before a single token. Price as if review does not exist and the first compliance-sensitive customer with a high review rate will be your worst account.
Orchestration multiplies the token line. The pricing page shows the cost of a call. Your unit of work is many calls. An agent that plans, retrieves, calls a tool, reflects, and writes a final answer has made five model calls for one user-facing result, and a planner-executor loop on a hard task can make far more. The naive estimate prices one call and ships. The real cost is the sum across the whole orchestration graph, and as your agents get more capable, that graph gets deeper, which means your unit cost can rise even as per-token prices fall. More on that tension in the final chapter.
The AI Cost Stack calculator
You should maintain a living calculator for every work unit you price. Here is the shape, in pseudocode you can drop into a spreadsheet or a script. The discipline is having every layer present, even when a layer is zero, so nothing hides.
def unit_cost(u):
input_tok = u.calls * u.in_tokens * u.in_price_per_tok
output_tok = u.calls * u.out_tokens * u.out_price_per_tok
retrieval = u.lookups * u.retrieval_cost
rerank = u.rerank_passes * u.rerank_cost
tools = sum(t.cost for t in u.tool_calls)
orchestr = u.planner_calls * u.planner_cost
cache_saving= -u.cached_in_tokens * u.in_price_per_tok * 0.90
retries = (input_tok + output_tok) * u.retry_rate
review = u.review_rate * u.review_cost
monitoring = u.eval_sample_rate * u.eval_cost + u.trace_cost
support = u.support_rate * u.support_cost
storage = u.storage_amortized
return sum([input_tok, output_tok, retrieval, rerank, tools,
orchestr, cache_saving, retries, review,
monitoring, support, storage])The value of writing it this way is not precision to the penny. It is that the structure forces you to put a number, even a rough one, on every layer. The first time a team fills this in honestly, two things happen: the total comes in well above the "token cost" they had been using, and one or two layers they had not thought about turn out to dominate. Both are the point.
Why this stays off the pricing page, and why that is fine
Nothing in this chapter belongs on your pricing page, and that is not a contradiction with the transparency I keep preaching. Customers should not see tokens, reranking, or retry rates any more than they see the cost of your data center in a per-seat SaaS bill. The cost stack is an internal instrument. It tells you what a unit costs so you can price it with a known margin. The customer sees the work unit and its price. The transparency chapter draws the line precisely: you explain the price honestly without exposing the cost stack, the same way a restaurant prices a dish without itemizing the kitchen.
What is not fine is pricing the customer-facing work unit without having built the cost stack underneath it. That is pricing blind, and it is the most common reason a celebrated AI launch turns into a margin emergency two quarters later. The stack is the thing standing between "we charge thirty cents" and "we make money charging thirty cents."
Practical exercise
Pick your most-used AI work unit. Build the twelve-layer table for it with real numbers where you have them and honest estimates where you do not. Compare the total to whatever cost figure you have been using in your pricing model. If the gap is more than 30 percent, your current price is set against a fiction, and you should not change another thing about packaging until you have closed it.
Key Takeaways
- The token cost is one item in a stack of twelve; pricing on it alone typically understates real unit cost by two to five times.
- The full stack: input tokens, output tokens, retrieval, reranking, storage, tools, orchestration, caching (a reducer), retries, human review, monitoring and evals, and support.
- Output tokens are usually the largest token line and the biggest lever you control; orchestration multiplies the token line because one work unit is many model calls.
- Human review is the margin killer in high-stakes work and dwarfs token cost when it appears; model it as a line, not an edge case.
- Maintain a per-unit cost calculator with every layer present so nothing hides; aim for structural completeness, not penny precision.
- The cost stack is an internal instrument and stays off the pricing page; what is unacceptable is pricing the work unit without having built it.
Internal map
For the larger argument, keep this chapter connected to Pricing Software That Thinks, Revenue, Re-Engineered, the smaller-model margin argument, and The Economics of Inference.